Merge branch 'master' into master
@ -12,9 +12,10 @@
|
||||
"arrow-body-style": "off",
|
||||
"no-loop-func": "off"
|
||||
},
|
||||
"ignorePatterns": ["*.md", "*.png", "*.jpeg", "*.jpg"],
|
||||
"settings": {
|
||||
"react": {
|
||||
"version": "latest"
|
||||
"version": "18.2.0"
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
2
.github/workflows/CI.yml
vendored
@ -11,7 +11,7 @@ jobs:
|
||||
runs-on: ubuntu-latest
|
||||
strategy:
|
||||
matrix:
|
||||
node-version: [ 14.x ]
|
||||
node-version: [ 16.x ]
|
||||
|
||||
steps:
|
||||
- name: Checkout repository
|
||||
|
||||
18
BACKERS.md
@ -14,6 +14,24 @@
|
||||
|
||||
`null`
|
||||
|
||||
<!--
|
||||
<table>
|
||||
<tr>
|
||||
<td align="center">
|
||||
<a href="[PROFILE_URL]">
|
||||
<img
|
||||
src="[PROFILE_IMG_SRC]"
|
||||
width="50"
|
||||
height="50"
|
||||
/>
|
||||
</a>
|
||||
<br />
|
||||
<a href="[PROFILE_URL]">[PROFILE_NAME]</a>
|
||||
</td>
|
||||
</tr>
|
||||
</table>
|
||||
-->
|
||||
|
||||
<!--
|
||||
<ul>
|
||||
<li>
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
[](https://travis-ci.org/trekhleb/javascript-algorithms)
|
||||
[](https://codecov.io/gh/trekhleb/javascript-algorithms)
|
||||
|
||||
تحتوي هذا مقالة على أمثلة عديدة تستند إلى الخوارزميات الشائعة وهياكل البيانات في الجافا سكريبت.
|
||||
تحتوي هذه المقالة على أمثلة عديدة تستند إلى الخوارزميات الشائعة وهياكل البيانات في الجافا سكريبت.
|
||||
|
||||
كل خوارزمية وهياكل البيانات لها برنامج README منفصل خاص بها
|
||||
مع التفسيرات والروابط ذات الصلة لمزيد من القراءة (بما في ذلك تلك
|
||||
@ -23,7 +23,8 @@ _اقرأ هذا في لغات أخرى:_
|
||||
[_Türk_](README.tr-TR.md),
|
||||
[_Italiana_](README.it-IT.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
☝ ملاحضة هذا المشروع مخصص للاستخدام لأغراض التعلم والبحث
|
||||
فقط ، و ** ليست ** معدة للاستخدام في **الإنتاج**
|
||||
|
||||
@ -24,7 +24,8 @@ _Lies dies in anderen Sprachen:_
|
||||
[_Italiana_](README.it-IT.md),
|
||||
[_Bahasa Indonesia_](README.id-ID.md),
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md)
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
_☝ Beachte, dass dieses Projekt nur für Lern- und Forschungszwecke gedacht ist und **nicht** für den produktiven Einsatz verwendet werden soll_
|
||||
|
||||
|
||||
@ -25,7 +25,8 @@ _Léelo en otros idiomas:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
*☝ Nótese que este proyecto está pensado con fines de aprendizaje e investigación,
|
||||
y **no** para ser usado en producción.*
|
||||
@ -69,7 +70,7 @@ definen con precisión una secuencia de operaciones.
|
||||
* **Matemáticas**
|
||||
* `P` [Manipulación de bits](src/algorithms/math/bits) - asignar/obtener/actualizar/limpiar bits, multiplicación/división por dos, hacer negativo, etc.
|
||||
* `P` [Factorial](src/algorithms/math/factorial)
|
||||
* `P` [Número de Fibonacci](src/algorithms/math/fibonacci)
|
||||
* `P` [Sucesión de Fibonacci](src/algorithms/math/fibonacci)
|
||||
* `P` [Prueba de primalidad](src/algorithms/math/primality-test) (método de división de prueba)
|
||||
* `P` [Algoritmo de Euclides](src/algorithms/math/euclidean-algorithm) - calcular el Máximo común divisor (MCD)
|
||||
* `P` [Mínimo común múltiplo](src/algorithms/math/least-common-multiple) (MCM)
|
||||
|
||||
@ -26,7 +26,8 @@ _Lisez ceci dans d'autres langues:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
## Data Structures
|
||||
|
||||
|
||||
@ -23,7 +23,8 @@ _Baca ini dalam bahasa yang lain:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
_☝ Perhatikan bahwa proyek ini hanya dimaksudkan untuk tujuan pembelajaran dan riset, dan **tidak** dimaksudkan untuk digunakan sebagai produksi._
|
||||
|
||||
|
||||
@ -22,7 +22,8 @@ _Leggilo in altre lingue:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
*☝ Si noti che questo progetto è destinato ad essere utilizzato solo per l'apprendimento e la ricerca e non è destinato ad essere utilizzato per il commercio.*
|
||||
|
||||
|
||||
@ -25,7 +25,8 @@ _Read this in other languages:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
## データ構造
|
||||
|
||||
|
||||
@ -24,7 +24,8 @@ _Read this in other languages:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
## 자료 구조
|
||||
|
||||
|
||||
39
README.md
@ -1,12 +1,17 @@
|
||||
# JavaScript Algorithms and Data Structures
|
||||
|
||||
> 🇺🇦 UKRAINE [IS BEING ATTACKED](https://twitter.com/MFA_Ukraine) BY RUSSIAN ARMY. CIVILIANS ARE GETTING KILLED. RESIDENTIAL AREAS ARE GETTING BOMBED.
|
||||
> - Help Ukraine via [National Bank of Ukraine](https://bank.gov.ua/en/news/all/natsionalniy-bank-vidkriv-spetsrahunok-dlya-zboru-koshtiv-na-potrebi-armiyi)
|
||||
> - Help Ukraine via [SaveLife](https://savelife.in.ua/en/donate/) fund
|
||||
> - More info on [war.ukraine.ua](https://war.ukraine.ua/)
|
||||
> 🇺🇦 UKRAINE [IS BEING ATTACKED](https://war.ukraine.ua/) BY RUSSIAN ARMY. CIVILIANS ARE GETTING KILLED. RESIDENTIAL AREAS ARE GETTING BOMBED.
|
||||
> - Help Ukraine via:
|
||||
> - [Serhiy Prytula Charity Foundation](https://prytulafoundation.org/en/)
|
||||
> - [Come Back Alive Charity Foundation](https://savelife.in.ua/en/donate-en/)
|
||||
> - [National Bank of Ukraine](https://bank.gov.ua/en/news/all/natsionalniy-bank-vidkriv-spetsrahunok-dlya-zboru-koshtiv-na-potrebi-armiyi)
|
||||
> - More info on [war.ukraine.ua](https://war.ukraine.ua/) and [MFA of Ukraine](https://twitter.com/MFA_Ukraine)
|
||||
|
||||
<hr/>
|
||||
|
||||
[](https://github.com/trekhleb/javascript-algorithms/actions?query=workflow%3ACI+branch%3Amaster)
|
||||
[](https://codecov.io/gh/trekhleb/javascript-algorithms)
|
||||

|
||||
|
||||
This repository contains JavaScript based examples of many
|
||||
popular algorithms and data structures.
|
||||
@ -31,7 +36,8 @@ _Read this in other languages:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
*☝ Note that this project is meant to be used for learning and researching purposes
|
||||
only, and it is **not** meant to be used for production.*
|
||||
@ -43,6 +49,8 @@ be accessed and modified efficiently. More precisely, a data structure is a coll
|
||||
values, the relationships among them, and the functions or operations that can be applied to
|
||||
the data.
|
||||
|
||||
Remember that each data has its own trade-offs. And you need to pay attention more to why you're choosing a certain data structure than to how to implement it.
|
||||
|
||||
`B` - Beginner, `A` - Advanced
|
||||
|
||||
* `B` [Linked List](src/data-structures/linked-list)
|
||||
@ -60,8 +68,9 @@ the data.
|
||||
* `A` [Segment Tree](src/data-structures/tree/segment-tree) - with min/max/sum range queries examples
|
||||
* `A` [Fenwick Tree](src/data-structures/tree/fenwick-tree) (Binary Indexed Tree)
|
||||
* `A` [Graph](src/data-structures/graph) (both directed and undirected)
|
||||
* `A` [Disjoint Set](src/data-structures/disjoint-set)
|
||||
* `A` [Disjoint Set](src/data-structures/disjoint-set) - a union–find data structure or merge–find set
|
||||
* `A` [Bloom Filter](src/data-structures/bloom-filter)
|
||||
* `A` [LRU Cache](src/data-structures/lru-cache/) - Least Recently Used (LRU) cache
|
||||
|
||||
## Algorithms
|
||||
|
||||
@ -97,7 +106,7 @@ a set of rules that precisely define a sequence of operations.
|
||||
* **Sets**
|
||||
* `B` [Cartesian Product](src/algorithms/sets/cartesian-product) - product of multiple sets
|
||||
* `B` [Fisher–Yates Shuffle](src/algorithms/sets/fisher-yates) - random permutation of a finite sequence
|
||||
* `A` [Power Set](src/algorithms/sets/power-set) - all subsets of a set (bitwise and backtracking solutions)
|
||||
* `A` [Power Set](src/algorithms/sets/power-set) - all subsets of a set (bitwise, backtracking, and cascading solutions)
|
||||
* `A` [Permutations](src/algorithms/sets/permutations) (with and without repetitions)
|
||||
* `A` [Combinations](src/algorithms/sets/combinations) (with and without repetitions)
|
||||
* `A` [Longest Common Subsequence](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||
@ -130,6 +139,7 @@ a set of rules that precisely define a sequence of operations.
|
||||
* `B` [Shellsort](src/algorithms/sorting/shell-sort)
|
||||
* `B` [Counting Sort](src/algorithms/sorting/counting-sort)
|
||||
* `B` [Radix Sort](src/algorithms/sorting/radix-sort)
|
||||
* `B` [Bucket Sort](src/algorithms/sorting/bucket-sort)
|
||||
* **Linked Lists**
|
||||
* `B` [Straight Traversal](src/algorithms/linked-list/traversal)
|
||||
* `B` [Reverse Traversal](src/algorithms/linked-list/reverse-traversal)
|
||||
@ -277,14 +287,14 @@ npm test -- 'LinkedList'
|
||||
|
||||
**Troubleshooting**
|
||||
|
||||
In case if linting or testing is failing try to delete the `node_modules` folder and re-install npm packages:
|
||||
If linting or testing is failing, try to delete the `node_modules` folder and re-install npm packages:
|
||||
|
||||
```
|
||||
rm -rf ./node_modules
|
||||
npm i
|
||||
```
|
||||
|
||||
Also make sure that you're using a correct Node version (`>=14.16.0`). If you're using [nvm](https://github.com/nvm-sh/nvm) for Node version management you may run `nvm use` from the root folder of the project and the correct version will be picked up.
|
||||
Also make sure that you're using a correct Node version (`>=16`). If you're using [nvm](https://github.com/nvm-sh/nvm) for Node version management you may run `nvm use` from the root folder of the project and the correct version will be picked up.
|
||||
|
||||
**Playground**
|
||||
|
||||
@ -301,7 +311,8 @@ npm test -- 'playground'
|
||||
|
||||
### References
|
||||
|
||||
[▶ Data Structures and Algorithms on YouTube](https://www.youtube.com/playlist?list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
- [▶ Data Structures and Algorithms on YouTube](https://www.youtube.com/playlist?list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
- [✍🏻 Data Structure Sketches](https://okso.app/showcase/data-structures)
|
||||
|
||||
### Big O Notation
|
||||
|
||||
@ -357,6 +368,10 @@ Below is the list of some of the most used Big O notations and their performance
|
||||
|
||||
> You may support this project via ❤️️ [GitHub](https://github.com/sponsors/trekhleb) or ❤️️ [Patreon](https://www.patreon.com/trekhleb).
|
||||
|
||||
[Folks who are backing this project](https://github.com/trekhleb/javascript-algorithms/blob/master/BACKERS.md) `∑ = 0`
|
||||
[Folks who are backing this project](https://github.com/trekhleb/javascript-algorithms/blob/master/BACKERS.md) `∑ = 1`
|
||||
|
||||
> ℹ️ A few more [projects](https://trekhleb.dev/projects/) and [articles](https://trekhleb.dev/blog/) about JavaScript and algorithms on [trekhleb.dev](https://trekhleb.dev)
|
||||
## Author
|
||||
|
||||
[@trekhleb](https://trekhleb.dev)
|
||||
|
||||
A few more [projects](https://trekhleb.dev/projects/) and [articles](https://trekhleb.dev/blog/) about JavaScript and algorithms on [trekhleb.dev](https://trekhleb.dev)
|
||||
|
||||
@ -26,7 +26,8 @@ _Read this in other languages:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
## Struktury Danych
|
||||
|
||||
|
||||
220
README.pt-BR.md
@ -26,14 +26,13 @@ _Leia isto em outros idiomas:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
## Estrutura de Dados
|
||||
|
||||
Uma estrutura de dados é uma maneira particular de organizar e armazenar dados em um computador para que ele possa
|
||||
ser acessado e modificado de forma eficiente. Mais precisamente, uma estrutura de dados é uma coleção de dados
|
||||
valores, as relações entre eles e as funções ou operações que podem ser aplicadas a
|
||||
os dados.
|
||||
ser acessado e modificado de forma eficiente. Mais precisamente, uma estrutura de dados é uma coleção de valores de dados, as relações entre eles e as funções ou operações que podem ser aplicadas aos dados.
|
||||
|
||||
`B` - Iniciante, `A` - Avançado
|
||||
|
||||
@ -42,17 +41,17 @@ os dados.
|
||||
* `B` [Fila (Queue)](src/data-structures/queue/README.pt-BR.md)
|
||||
* `B` [Pilha (Stack)](src/data-structures/stack/README.pt-BR.md)
|
||||
* `B` [Tabela de Hash (Hash Table)](src/data-structures/hash-table/README.pt-BR.md)
|
||||
* `B` [Heap](src/data-structures/heap/README.pt-BR.md)
|
||||
* `B` [Heap](src/data-structures/heap/README.pt-BR.md) - versões de heap máximo e mínimo
|
||||
* `B` [Fila de Prioridade (Priority Queue)](src/data-structures/priority-queue/README.pt-BR.md)
|
||||
* `A` [Árvore de prefixos (Trie)](src/data-structures/trie/README.pt-BR.md)
|
||||
* `A` [Árvore de Prefixos (Trie)](src/data-structures/trie/README.pt-BR.md)
|
||||
* `A` [Árvore (Tree)](src/data-structures/tree/README.pt-BR.md)
|
||||
* `A` [Árvore de Pesquisa Binária (Binary Search Tree)](src/data-structures/tree/binary-search-tree/README.pt-BR.md)
|
||||
* `A` [Árvore AVL (AVL Tree)](src/data-structures/tree/avl-tree/README.pt-BR.md)
|
||||
* `A` [Árvore Vermelha-Preta (Red-Black Tree)](src/data-structures/tree/red-black-tree/README.pt-BR.md)
|
||||
* `A` [Árvore de Segmento (Segment Tree)](src/data-structures/tree/segment-tree/README.pt-BR.md) - Com exemplos de consultas min / max / sum range
|
||||
* `A` [Árvore Rubro-Negra (Red-Black Tree)](src/data-structures/tree/red-black-tree/README.pt-BR.md)
|
||||
* `A` [Árvore de Segmento (Segment Tree)](src/data-structures/tree/segment-tree/README.pt-BR.md) - com exemplos de consultas min / max / sum range
|
||||
* `A` [Árvore Fenwick (Fenwick Tree)](src/data-structures/tree/fenwick-tree/README.pt-BR.md) (Árvore indexada binária)
|
||||
* `A` [Grafo (Graph)](src/data-structures/graph/README.pt-BR.md) (ambos dirigidos e não direcionados)
|
||||
* `A` [Conjunto Disjuntor (Disjoint Set)](src/data-structures/disjoint-set/README.pt-BR.md)
|
||||
* `A` [Conjunto Disjunto (Disjoint Set)](src/data-structures/disjoint-set/README.pt-BR.md)
|
||||
* `A` [Filtro Bloom (Bloom Filter)](src/data-structures/bloom-filter/README.pt-BR.md)
|
||||
|
||||
## Algoritmos
|
||||
@ -72,36 +71,37 @@ um conjunto de regras que define precisamente uma sequência de operações.
|
||||
* `B` [Algoritmo Euclidiano](src/algorithms/math/euclidean-algorithm) - Calcular o Máximo Divisor Comum (MDC)
|
||||
* `B` [Mínimo Múltiplo Comum](src/algorithms/math/least-common-multiple) Calcular o Mínimo Múltiplo Comum (MMC)
|
||||
* `B` [Peneira de Eratóstenes](src/algorithms/math/sieve-of-eratosthenes) - Encontrar todos os números primos até um determinado limite
|
||||
* `B` [Potência de dois](src/algorithms/math/is-power-of-two) - Verifique se o número é a potência de dois (algoritmos ingênuos e bit a bit)
|
||||
* `B` [Potência de Dois](src/algorithms/math/is-power-of-two) - Verifique se o número é a potência de dois (algoritmos ingênuos e bit a bit)
|
||||
* `B` [Triângulo de Pascal](src/algorithms/math/pascal-triangle)
|
||||
* `B` [Número complexo](src/algorithms/math/complex-number) - Números complexos e operações básicas com eles
|
||||
* `A` [Partição inteira](src/algorithms/math/integer-partition)
|
||||
* `B` [Número Complexo](src/algorithms/math/complex-number) - Números complexos e operações básicas com eles
|
||||
* `A` [Partição Inteira](src/algorithms/math/integer-partition)
|
||||
* `A` [Algoritmo Liu Hui π](src/algorithms/math/liu-hui) - Cálculos aproximados de π baseados em N-gons
|
||||
* **Conjuntos**
|
||||
* `B` [Produto cartesiano](src/algorithms/sets/cartesian-product) - Produto de vários conjuntos
|
||||
* `B` [Produto Cartesiano](src/algorithms/sets/cartesian-product) - Produto de vários conjuntos
|
||||
* `B` [Permutações de Fisher–Yates](src/algorithms/sets/fisher-yates) - Permutação aleatória de uma sequência finita
|
||||
* `A` [Potência e Conjunto](src/algorithms/sets/power-set) - Todos os subconjuntos de um conjunto
|
||||
* `A` [Permutações](src/algorithms/sets/permutations) (com e sem repetições)
|
||||
* `A` [Combinações](src/algorithms/sets/combinations) (com e sem repetições)
|
||||
* `A` [Mais longa subsequência comum](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||
* `A` [Maior subsequência crescente](src/algorithms/sets/longest-increasing-subsequence)
|
||||
* `A` [Supersequência Comum mais curta](src/algorithms/sets/shortest-common-supersequence) (SCS)
|
||||
* `A` [Problema da mochila](src/algorithms/sets/knapsack-problem) - "0/1" e "Não consolidado"
|
||||
* `A` [Máximo Subarray](src/algorithms/sets/maximum-subarray) - "Força bruta" e " Programação Dinâmica" versões (Kadane's)
|
||||
* `A` [Mais Longa Subsequência Comum](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||
* `A` [Maior Subsequência Crescente](src/algorithms/sets/longest-increasing-subsequence)
|
||||
* `A` [Supersequência Comum Mais Curta](src/algorithms/sets/shortest-common-supersequence) (SCS)
|
||||
* `A` [Problema da Mochila](src/algorithms/sets/knapsack-problem) - "0/1" e "Não consolidado"
|
||||
* `A` [Subarray Máximo](src/algorithms/sets/maximum-subarray) - "Força bruta" e "Programação Dinâmica", versões de Kadane
|
||||
* `A` [Soma de Combinação](src/algorithms/sets/combination-sum) - Encontre todas as combinações que formam uma soma específica
|
||||
* **Cadeia de Caracteres**
|
||||
* `B` [Hamming Distance](src/algorithms/string/hamming-distance) - Número de posições em que os símbolos são diferentes
|
||||
* `A` [Levenshtein Distance](src/algorithms/string/levenshtein-distance) - Distância mínima de edição entre duas sequências
|
||||
* `A` [Knuth–Morris–Pratt Algorithm](src/algorithms/string/knuth-morris-pratt) (Algoritmo KMP) - Pesquisa de substring (correspondência de padrão)
|
||||
* `B` [Distância de Hamming](src/algorithms/string/hamming-distance) - Número de posições em que os símbolos são diferentes
|
||||
* `B` [Palíndromos](src/algorithms/string/palindrome) - Verifique se a cadeia de caracteres (string) é a mesma ao contrário
|
||||
* `A` [Distância Levenshtein](src/algorithms/string/levenshtein-distance) - Distância mínima de edição entre duas sequências
|
||||
* `A` [Algoritmo Knuth–Morris–Pratt](src/algorithms/string/knuth-morris-pratt) (Algoritmo KMP) - Pesquisa de substring (correspondência de padrão)
|
||||
* `A` [Z Algorithm](src/algorithms/string/z-algorithm) - Pesquisa de substring (correspondência de padrão)
|
||||
* `A` [Rabin Karp Algorithm](src/algorithms/string/rabin-karp) - Pesquisa de substring
|
||||
* `A` [Longest Common Substring](src/algorithms/string/longest-common-substring)
|
||||
* `A` [Regular Expression Matching](src/algorithms/string/regular-expression-matching)
|
||||
* `A` [Algoritmo de Rabin Karp](src/algorithms/string/rabin-karp) - Pesquisa de substring
|
||||
* `A` [Substring Comum Mais Longa](src/algorithms/string/longest-common-substring)
|
||||
* `A` [Expressões Regulares Correspondentes](src/algorithms/string/regular-expression-matching)
|
||||
* **Buscas**
|
||||
* `B` [Linear Search](src/algorithms/search/linear-search)
|
||||
* `B` [Jump Search](src/algorithms/search/jump-search) (ou Bloquear pesquisa) - Pesquisar na matriz ordenada
|
||||
* `B` [Binary Search](src/algorithms/search/binary-search) - Pesquisar na matriz ordenada
|
||||
* `B` [Interpolation Search](src/algorithms/search/interpolation-search) - Pesquisar em matriz classificada uniformemente distribuída
|
||||
* `B` [Busca Linear (Linear Search)](src/algorithms/search/linear-search)
|
||||
* `B` [Busca por Saltos (Jump Search)](src/algorithms/search/jump-search) - Pesquisa em matriz ordenada
|
||||
* `B` [Busca Binária (Binary Search)](src/algorithms/search/binary-search) - Pesquisa em matriz ordenada
|
||||
* `B` [Busca por Interpolação (Interpolation Search)](src/algorithms/search/interpolation-search) - Pesquisa em matriz classificada uniformemente distribuída
|
||||
* **Classificação**
|
||||
* `B` [Bubble Sort](src/algorithms/sorting/bubble-sort)
|
||||
* `B` [Selection Sort](src/algorithms/sorting/selection-sort)
|
||||
@ -112,35 +112,35 @@ um conjunto de regras que define precisamente uma sequência de operações.
|
||||
* `B` [Shellsort](src/algorithms/sorting/shell-sort)
|
||||
* `B` [Counting Sort](src/algorithms/sorting/counting-sort)
|
||||
* `B` [Radix Sort](src/algorithms/sorting/radix-sort)
|
||||
* **Arvóres**
|
||||
* `B` [Depth-First Search](src/algorithms/tree/depth-first-search) (DFS)
|
||||
* `B` [Breadth-First Search](src/algorithms/tree/breadth-first-search) (BFS)
|
||||
* **Árvores**
|
||||
* `B` [Busca em Profundidade (Depth-First Search)](src/algorithms/tree/depth-first-search) (DFS)
|
||||
* `B` [Busca em Largura (Breadth-First Search)](src/algorithms/tree/breadth-first-search) (BFS)
|
||||
* **Grafos**
|
||||
* `B` [Depth-First Search](src/algorithms/graph/depth-first-search) (DFS)
|
||||
* `B` [Breadth-First Search](src/algorithms/graph/breadth-first-search) (BFS)
|
||||
* `B` [Kruskal’s Algorithm](src/algorithms/graph/kruskal) - Encontrar Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderado
|
||||
* `A` [Dijkstra Algorithm](src/algorithms/graph/dijkstra) - Encontrar caminhos mais curtos para todos os vértices do grafo a partir de um único vértice
|
||||
* `A` [Bellman-Ford Algorithm](src/algorithms/graph/bellman-ford) - Encontrar caminhos mais curtos para todos os vértices do grafo a partir de um único vértice
|
||||
* `A` [Floyd-Warshall Algorithm](src/algorithms/graph/floyd-warshall) - Encontrar caminhos mais curtos entre todos os pares de vértices
|
||||
* `A` [Detect Cycle](src/algorithms/graph/detect-cycle) - Para gráficos direcionados e não direcionados (versões baseadas em DFS e Conjunto Disjuntivo)
|
||||
* `A` [Prim’s Algorithm](src/algorithms/graph/prim) - Encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderado
|
||||
* `A` [Topological Sorting](src/algorithms/graph/topological-sorting) - Métodos DFS
|
||||
* `A` [Articulation Points](src/algorithms/graph/articulation-points) -O algoritmo de Tarjan (baseado em DFS)
|
||||
* `A` [Bridges](src/algorithms/graph/bridges) - Algoritmo baseado em DFS
|
||||
* `A` [Eulerian Path and Eulerian Circuit](src/algorithms/graph/eulerian-path) - Algoritmo de Fleury - Visite todas as bordas exatamente uma vez
|
||||
* `A` [Hamiltonian Cycle](src/algorithms/graph/hamiltonian-cycle) - Visite todas as bordas exatamente uma vez
|
||||
* `A` [Strongly Connected Components](src/algorithms/graph/strongly-connected-components) - Algoritmo de Kosaraju's
|
||||
* `A` [Travelling Salesman Problem](src/algorithms/graph/travelling-salesman) - Rota mais curta possível que visita cada cidade e retorna à cidade de origem
|
||||
* `B` [Busca em Profundidade (Depth-First Search)](src/algorithms/graph/depth-first-search) (DFS)
|
||||
* `B` [Busca em Largura (Breadth-First Search)](src/algorithms/graph/breadth-first-search) (BFS)
|
||||
* `B` [Algoritmo de Kruskal](src/algorithms/graph/kruskal) - Encontrando Árvore Mínima de Abrangência (MST) para grafo conexo com pesos
|
||||
* `A` [Algoritmo de Dijkstra](src/algorithms/graph/dijkstra) - Encontrar caminhos mais curtos para todos os vértices do grafo a partir de um único vértice
|
||||
* `A` [Algoritmo de Bellman-Ford](src/algorithms/graph/bellman-ford) - Encontrar caminhos mais curtos para todos os vértices do grafo a partir de um único vértice
|
||||
* `A` [Algoritmo de Floyd-Warshall](src/algorithms/graph/floyd-warshall) - Encontrar caminhos mais curtos entre todos os pares de vértices
|
||||
* `A` [Detectar Ciclo](src/algorithms/graph/detect-cycle) - Para grafos direcionados e não direcionados (versões baseadas em DFS e Conjunto Disjuntivo)
|
||||
* `A` [Algoritmo de Prim](src/algorithms/graph/prim) - Encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderado
|
||||
* `A` [Ordenação Topológica](src/algorithms/graph/topological-sorting) - Métodos DFS
|
||||
* `A` [Pontos de Articulação](src/algorithms/graph/articulation-points) - O algoritmo de Tarjan (baseado em DFS)
|
||||
* `A` [Pontes](src/algorithms/graph/bridges) - Algoritmo baseado em DFS
|
||||
* `A` [Caminho e Circuito Euleriano](src/algorithms/graph/eulerian-path) - Algoritmo de Fleury - Visite todas as bordas exatamente uma vez
|
||||
* `A` [Ciclo Hamiltoniano](src/algorithms/graph/hamiltonian-cycle) - Visite todas as bordas exatamente uma vez
|
||||
* `A` [Componentes Fortemente Conectados](src/algorithms/graph/strongly-connected-components) - Algoritmo de Kosaraju
|
||||
* `A` [Problema do Caixeiro Viajante](src/algorithms/graph/travelling-salesman) - Rota mais curta possível que visita cada cidade e retorna à cidade de origem
|
||||
* **Criptografia**
|
||||
* `B` [Polynomial Hash](src/algorithms/cryptography/polynomial-hash) - Função de hash de rolagem baseada em polinômio
|
||||
* `B` [Hash Polinomial](src/algorithms/cryptography/polynomial-hash) - Função de hash de rolagem baseada em polinômio
|
||||
* **Sem categoria**
|
||||
* `B` [Tower of Hanoi](src/algorithms/uncategorized/hanoi-tower)
|
||||
* `B` [Square Matrix Rotation](src/algorithms/uncategorized/square-matrix-rotation) - Algoritmo no local
|
||||
* `B` [Jump Game](src/algorithms/uncategorized/jump-game) - Backtracking, programação dinâmica (top-down + bottom-up) e exemplos gananciosos
|
||||
* `B` [Unique Paths](src/algorithms/uncategorized/unique-paths) - Backtracking, programação dinâmica e exemplos baseados no triângulo de Pascal
|
||||
* `B` [Rain Terraces](src/algorithms/uncategorized/rain-terraces) - Trapping problema da água da chuva (programação dinâmica e versões de força bruta)
|
||||
* `A` [N-Queens Problem](src/algorithms/uncategorized/n-queens)
|
||||
* `A` [Knight's Tour](src/algorithms/uncategorized/knight-tour)
|
||||
* `B` [Torre de Hanoi](src/algorithms/uncategorized/hanoi-tower)
|
||||
* `B` [Rotação de Matriz Quadrada](src/algorithms/uncategorized/square-matrix-rotation) - Algoritmo no local
|
||||
* `B` [Jogo do Salto](src/algorithms/uncategorized/jump-game) - Backtracking, programação dinâmica (top-down + bottom-up) e exemplos gananciosos
|
||||
* `B` [Caminhos Únicos](src/algorithms/uncategorized/unique-paths) - Backtracking, programação dinâmica e exemplos baseados no triângulo de Pascal
|
||||
* `B` [Terraços de Chuva](src/algorithms/uncategorized/rain-terraces) - Problema de retenção da água da chuva (programação dinâmica e versões de força bruta)
|
||||
* `A` [Problema das N-Rainhas](src/algorithms/uncategorized/n-queens)
|
||||
* `A` [Passeio do Cavaleiro](src/algorithms/uncategorized/knight-tour)
|
||||
|
||||
### Algoritmos por Paradigma
|
||||
|
||||
@ -149,54 +149,52 @@ de algoritmos. É uma abstração maior do que a noção de um algoritmo, assim
|
||||
algoritmo é uma abstração maior que um programa de computador.
|
||||
|
||||
* **Força bruta** - Pense em todas as possibilidades e escolha a melhor solução
|
||||
* `B` [Linear Search](src/algorithms/search/linear-search)
|
||||
* `B` [Rain Terraces](src/algorithms/uncategorized/rain-terraces) - Trapping problema da água da chuva
|
||||
* `A` [Maximum Subarray](src/algorithms/sets/maximum-subarray)
|
||||
* `A` [Travelling Salesman Problem](src/algorithms/graph/travelling-salesman) - Rota mais curta possível que visita cada cidade e retorna à cidade de origem
|
||||
* `B` [Busca Linear (Linear Search)](src/algorithms/search/linear-search)
|
||||
* `B` [Terraços de Chuva](src/algorithms/uncategorized/rain-terraces) - Problema de retenção de água da chuva (programação dinâmica e versões de força bruta)
|
||||
* `A` [Subarray Máximo](src/algorithms/sets/maximum-subarray)
|
||||
* `A` [Problema do Caixeiro Viajante](src/algorithms/graph/travelling-salesman) - Rota mais curta possível que visita cada cidade e retorna à cidade de origem
|
||||
* **Ganância** - Escolha a melhor opção no momento, sem qualquer consideração pelo futuro
|
||||
* `B` [Jump Game](src/algorithms/uncategorized/jump-game)
|
||||
* `A` [Unbound Knapsack Problem](src/algorithms/sets/knapsack-problem)
|
||||
* `A` [Dijkstra Algorithm](src/algorithms/graph/dijkstra) - Encontrar o caminho mais curto para todos os vértices do gráfico
|
||||
* `A` [Prim’s Algorithm](src/algorithms/graph/prim) - Encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderado
|
||||
* `A` [Kruskal’s Algorithm](src/algorithms/graph/kruskal) - Encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderado
|
||||
* `B` [Jogo do Salto](src/algorithms/uncategorized/jump-game)
|
||||
* `A` [Problema da Mochila](src/algorithms/sets/knapsack-problem)
|
||||
* `A` [Algoritmo de Dijkstra](src/algorithms/graph/dijkstra) - Encontrar caminhos mais curtos para todos os vértices do grafo a partir de um único vértice
|
||||
* `A` [Algoritmo de Prim](src/algorithms/graph/prim) - Encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderado
|
||||
* `A` [Algoritmo de Kruskal](src/algorithms/graph/kruskal) - Encontrando Árvore Mínima de Abrangência (MST) para grafo conexo com pesos
|
||||
* **Dividir e Conquistar** - Dividir o problema em partes menores e então resolver essas partes
|
||||
* `B` [Busca binária (Binary Search)](src/algorithms/search/binary-search)
|
||||
* `B` [Tower of Hanoi](src/algorithms/uncategorized/hanoi-tower)
|
||||
* `B` [Pascal's Triangle](src/algorithms/math/pascal-triangle)
|
||||
* `B` [Euclidean Algorithm](src/algorithms/math/euclidean-algorithm) - Calcular o Máximo Divisor Comum (MDC)
|
||||
* `B` [Busca Binária (Binary Search)](src/algorithms/search/binary-search)
|
||||
* `B` [Torre de Hanoi](src/algorithms/uncategorized/hanoi-tower)
|
||||
* `B` [Triângulo de Pascal](src/algorithms/math/pascal-triangle)
|
||||
* `B` [Algoritmo Euclidiano](src/algorithms/math/euclidean-algorithm) - Calcular o Máximo Divisor Comum (MDC)
|
||||
* `B` [Merge Sort](src/algorithms/sorting/merge-sort)
|
||||
* `B` [Quicksort](src/algorithms/sorting/quick-sort)
|
||||
* `B` [Tree Depth-First Search](src/algorithms/tree/depth-first-search) (DFS)
|
||||
* `B` [Graph Depth-First Search](src/algorithms/graph/depth-first-search) (DFS)
|
||||
* `B` [Jump Game](src/algorithms/uncategorized/jump-game)
|
||||
* `A` [Permutations](src/algorithms/sets/permutations) (com e sem repetições)
|
||||
* `A` [Combinations](src/algorithms/sets/combinations) (com e sem repetições)
|
||||
* `B` [Busca em Profundidade (Depth-First Search)](src/algorithms/tree/depth-first-search) (DFS)
|
||||
* `B` [Busca em Largura (Breadth-First Search)](src/algorithms/graph/breadth-first-search) (BFS)
|
||||
* `B` [Jogo do Salto](src/algorithms/uncategorized/jump-game)
|
||||
* `A` [Permutações](src/algorithms/sets/permutations) (com e sem repetições)
|
||||
* `A` [Combinações](src/algorithms/sets/combinations) (com e sem repetições)
|
||||
* **Programação Dinâmica** - Criar uma solução usando sub-soluções encontradas anteriormente
|
||||
* `B` [Fibonacci Number](src/algorithms/math/fibonacci)
|
||||
* `B` [Jump Game](src/algorithms/uncategorized/jump-game)
|
||||
* `B` [Unique Paths](src/algorithms/uncategorized/unique-paths)
|
||||
* `B` [Rain Terraces](src/algorithms/uncategorized/rain-terraces) - Trapping problema da água da chuva
|
||||
* `A` [Levenshtein Distance](src/algorithms/string/levenshtein-distance) - Distância mínima de edição entre duas sequências
|
||||
* `A` [Longest Common Subsequence](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||
* `A` [Longest Common Substring](src/algorithms/string/longest-common-substring)
|
||||
* `A` [Longest Increasing Subsequence](src/algorithms/sets/longest-increasing-subsequence)
|
||||
* `A` [Shortest Common Supersequence](src/algorithms/sets/shortest-common-supersequence)
|
||||
* `A` [0/1 Knapsack Problem](src/algorithms/sets/knapsack-problem)
|
||||
* `A` [Integer Partition](src/algorithms/math/integer-partition)
|
||||
* `A` [Maximum Subarray](src/algorithms/sets/maximum-subarray)
|
||||
* `A` [Bellman-Ford Algorithm](src/algorithms/graph/bellman-ford) - Encontrar o caminho mais curto para todos os vértices do gráfico
|
||||
* `A` [Floyd-Warshall Algorithm](src/algorithms/graph/floyd-warshall) - Encontrar caminhos mais curtos entre todos os pares de vértices
|
||||
* `A` [Regular Expression Matching](src/algorithms/string/regular-expression-matching)
|
||||
* **Backtracking** - Da mesma forma que a força bruta, tente gerar todas as soluções possíveis, mas cada vez que você gerar a próxima solução, você testará
|
||||
se satisfizer todas as condições, e só então continuar gerando soluções subseqüentes. Caso contrário, volte atrás e siga um caminho diferente para encontrar uma solução. Normalmente, a passagem DFS do espaço de estados está sendo usada.
|
||||
* `B` [Jump Game](src/algorithms/uncategorized/jump-game)
|
||||
* `B` [Unique Paths](src/algorithms/uncategorized/unique-paths)
|
||||
* `A` [Hamiltonian Cycle](src/algorithms/graph/hamiltonian-cycle) - Visite todos os vértices exatamente uma vez
|
||||
* `A` [N-Queens Problem](src/algorithms/uncategorized/n-queens)
|
||||
* `A` [Knight's Tour](src/algorithms/uncategorized/knight-tour)
|
||||
* `A` [Combination Sum](src/algorithms/sets/combination-sum) - Encontre todas as combinações que formam uma soma específica
|
||||
* **Branch & Bound** - Lembre-se da solução de menor custo encontrada em cada etapa do retrocesso
|
||||
pesquisar e usar o custo da solução de menor custo encontrada até o limite inferior do custo de
|
||||
* `B` [Número de Fibonacci](src/algorithms/math/fibonacci)
|
||||
* `B` [Jogo do Salto](src/algorithms/uncategorized/jump-game)
|
||||
* `B` [Caminhos Únicos](src/algorithms/uncategorized/unique-paths)
|
||||
* `B` [Terraços de Chuva](src/algorithms/uncategorized/rain-terraces) - Trapping problema da água da chuva
|
||||
* `A` [Distância Levenshtein](src/algorithms/string/levenshtein-distance) - Distância mínima de edição entre duas sequências
|
||||
* `A` [Mais Longa Subsequência Comum](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||
* `A` [Substring Comum Mais Longa](src/algorithms/string/longest-common-substring)
|
||||
* `A` [Maior Subsequência Crescente](src/algorithms/sets/longest-increasing-subsequence)
|
||||
* `A` [Supersequência Comum Mais Curta](src/algorithms/sets/shortest-common-supersequence)
|
||||
* `A` [Problema da Mochila](src/algorithms/sets/knapsack-problem)
|
||||
* `A` [Partição Inteira](src/algorithms/math/integer-partition)
|
||||
* `A` [Subarray Máximo](src/algorithms/sets/maximum-subarray)
|
||||
* `A` [Algoritmo de Bellman-Ford](src/algorithms/graph/bellman-ford) - Encontrar caminhos mais curtos para todos os vértices do grafo a partir de um único vértice
|
||||
* `A` [Algoritmo de Floyd-Warshall](src/algorithms/graph/floyd-warshall) - Encontrar caminhos mais curtos entre todos os pares de vértices
|
||||
* `A` [Expressões Regulares Correspondentes](src/algorithms/string/regular-expression-matching)
|
||||
* **Backtracking** - Da mesma forma que a força bruta, tente gerar todas as soluções possíveis, mas, cada vez que você gerar a próxima solução será necessário testar se a mesma satisfaz todas as condições, e só então continuará a gerar as soluções subsequentes. Caso contrário, volte atrás e siga um caminho diferente para encontrar uma solução. Normalmente, a passagem DFS do espaço de estados está sendo usada.
|
||||
* `B` [Jogo do Salto](src/algorithms/uncategorized/jump-game)
|
||||
* `B` [Caminhos Únicos](src/algorithms/uncategorized/unique-paths)
|
||||
* `A` [Ciclo Hamiltoniano](src/algorithms/graph/hamiltonian-cycle) - Visite todos os vértices exatamente uma vez
|
||||
* `A` [Problema das N-Rainhas](src/algorithms/uncategorized/n-queens)
|
||||
* `A` [Passeio do Cavaleiro](src/algorithms/uncategorized/knight-tour)
|
||||
* `A` [Soma de Combinação](src/algorithms/sets/combination-sum) - Encontre todas as combinações que formam uma soma específica
|
||||
* **Branch & Bound** - Lembre-se da solução de menor custo encontrada em cada etapa do retrocesso, pesquisar e usar o custo da solução de menor custo encontrada até o limite inferior do custo de
|
||||
solução de menor custo para o problema, a fim de descartar soluções parciais com custos maiores que o
|
||||
solução de menor custo encontrada até o momento. Normalmente, a travessia BFS em combinação com a passagem DFS do espaço de estados
|
||||
árvore está sendo usada
|
||||
@ -225,10 +223,19 @@ npm test
|
||||
```
|
||||
npm test -- 'LinkedList'
|
||||
```
|
||||
**Solução de problemas**
|
||||
|
||||
**Parque infantil**
|
||||
Caso o linting ou o teste estejam falhando, tente excluir a pasta node_modules e reinstalar os pacotes npm:
|
||||
```
|
||||
rm -rf ./node_modules
|
||||
npm i
|
||||
```
|
||||
|
||||
Você pode brincar com estruturas de dados e algoritmos em `./src/playground/playground.js` arquivar e escrever
|
||||
Verifique também se você está usando uma versão correta do Node (>=14.16.0). Se você estiver usando [nvm](https://github.com/nvm-sh/nvm) para gerenciamento de versão do Node, você pode executar `nvm use` a partir da pasta raiz do projeto e a versão correta será escolhida.
|
||||
|
||||
**Playground**
|
||||
|
||||
Você pode brincar com estruturas de dados e algoritmos no arquivo `./src/playground/playground.js` e escrever
|
||||
testes para isso em `./src/playground/__test__/playground.test.js`.
|
||||
|
||||
Em seguida, basta executar o seguinte comando para testar se o código do seu playground funciona conforme o esperado:
|
||||
@ -241,15 +248,16 @@ npm test -- 'playground'
|
||||
|
||||
### Referências
|
||||
|
||||
[▶ Estruturas de dados e algoritmos no YouTube](https://www.youtube.com/playlist?list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
- [▶ Estruturas de Dados e Algoritmos no YouTube](https://www.youtube.com/playlist?list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
- [✍🏻 Esboços de Estruturas de Dados](https://okso.app/showcase/data-structures)
|
||||
|
||||
### Notação Big O
|
||||
|
||||
Ordem de crescimento dos algoritmos especificados em notação Big O.
|
||||
A notação Big O é usada para classificar algoritmos de acordo com a forma como seu tempo de execução ou requisitos de espaço crescem à medida que o tamanho da entrada aumenta. No gráfico abaixo você pode encontrar as ordens mais comuns de crescimento de algoritmos especificados na notação Big O.
|
||||
|
||||

|
||||
|
||||
Fonte: [Notação Big-O dicas](http://bigocheatsheet.com/).
|
||||
Fonte: [Notação Big-O Dicas](http://bigocheatsheet.com/).
|
||||
|
||||
Abaixo está a lista de algumas das notações Big O mais usadas e suas comparações de desempenho em relação aos diferentes tamanhos dos dados de entrada.
|
||||
|
||||
@ -271,14 +279,14 @@ Abaixo está a lista de algumas das notações Big O mais usadas e suas compara
|
||||
| **Stack** | n | n | 1 | 1 | |
|
||||
| **Queue** | n | n | 1 | 1 | |
|
||||
| **Linked List** | n | n | 1 | 1 | |
|
||||
| **Hash Table** | - | n | n | n | Em caso de uma função hash perfeita, os custos seriam O (1) |
|
||||
| **Binary Search Tree** | n | n | n | n | No caso de custos de árvore equilibrados seria O (log (n))
|
||||
| **Hash Table** | - | n | n | n | Em caso de uma função hash perfeita, os custos seriam O(1) |
|
||||
| **Binary Search Tree** | n | n | n | n | No caso de custos de árvore equilibrados seria O(log(n))
|
||||
| **B-Tree** | log(n) | log(n) | log(n) | log(n) | |
|
||||
| **Red-Black Tree** | log(n) | log(n) | log(n) | log(n) | |
|
||||
| **AVL Tree** | log(n) | log(n) | log(n) | log(n) | |
|
||||
| **Bloom Filter** | - | 1 | 1 | - | Falsos positivos são possíveis durante a pesquisa |
|
||||
|
||||
### Array Sorting Algorithms Complexity
|
||||
### Complexidade dos Algoritmos de Ordenação de Matrizes
|
||||
|
||||
| Nome | Melhor | Média | Pior | Mémoria | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
@ -287,7 +295,7 @@ Abaixo está a lista de algumas das notações Big O mais usadas e suas compara
|
||||
| **Selection sort** | n<sup>2</sup> | n<sup>2</sup> | n<sup>2</sup> | 1 | Não | |
|
||||
| **Heap sort** | n log(n) | n log(n) | n log(n) | 1 | Não | |
|
||||
| **Merge sort** | n log(n) | n log(n) | n log(n) | n | Sim | |
|
||||
| **Quick sort** | n log(n) | n log(n) | n<sup>2</sup> | log(n) | Não | O Quicksort geralmente é feito no local com o espaço de pilha O O(log(n)) stack space |
|
||||
| **Quick sort** | n log(n) | n log(n) | n<sup>2</sup> | log(n) | Não | O Quicksort geralmente é feito no local com espaço de pilha O(log(n)) |
|
||||
| **Shell sort** | n log(n) | depende da sequência de lacunas | n (log(n))<sup>2</sup> | 1 | Não | |
|
||||
| **Counting sort** | n + r | n + r | n + r | n + r | Sim | r - maior número na matriz |
|
||||
| **Radix sort** | n * k | n * k | n * k | n + k | Sim | k - comprimento da chave mais longa |
|
||||
|
||||
@ -23,7 +23,8 @@ _Читать на других языках:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
*☝ Замечание: этот репозиторий предназначен для учебно-исследовательских целей (**не** для использования в продакшн-системах).*
|
||||
|
||||
|
||||
@ -23,7 +23,8 @@ _Read this in other languages:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
*☝ Not, bu proje araştırma ve öğrenme amacı ile yapılmış
|
||||
olup üretim için **yapılmamıştır**.*
|
||||
|
||||
@ -23,7 +23,8 @@ _Вивчення матеріалу на інших мовах:_
|
||||
[_Bahasa Indonesia_](README.id-ID.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
*☝ Зверніть увагу! Даний проект призначений лише для навчальних та дослідницьких цілей, і він **не** призначений для виробництва (продакшн).*
|
||||
|
||||
|
||||
358
README.uz-UZ.md
Normal file
@ -0,0 +1,358 @@
|
||||
# JavaScript algoritmlari va ma'lumotlar tuzilmalari
|
||||
|
||||
[](https://github.com/trekhleb/javascript-algorithms/actions?query=workflow%3ACI+branch%3Amaster)
|
||||
[](https://codecov.io/gh/trekhleb/javascript-algorithms)
|
||||

|
||||
|
||||
Bu repozitoriyada JavaScript-ga asoslangan ko'plab mashhur algoritmlar
|
||||
va ma'lumotlar tuzilmalarining namunalari mavjud.
|
||||
|
||||
Har bir algoritm va ma'lumotlar tuzilmasining alohida README fayli
|
||||
bo'lib, unda tegishli tushuntirishlar va qo'shimcha o'qish uchun
|
||||
havolalar (shu jumladan YouTube videolariga ham havolalar) mavjud.
|
||||
|
||||
_Read this in other languages:_
|
||||
[_简体中文_](README.zh-CN.md),
|
||||
[_繁體中文_](README.zh-TW.md),
|
||||
[_한국어_](README.ko-KR.md),
|
||||
[_日本語_](README.ja-JP.md),
|
||||
[_Polski_](README.pl-PL.md),
|
||||
[_Français_](README.fr-FR.md),
|
||||
[_Español_](README.es-ES.md),
|
||||
[_Português_](README.pt-BR.md),
|
||||
[_Русский_](README.ru-RU.md),
|
||||
[_Türkçe_](README.tr-TR.md),
|
||||
[_Italiana_](README.it-IT.md),
|
||||
[_Bahasa Indonesia_](README.id-ID.md),
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
Yodda tuting, bu loyiha faqat o'quv va tadqiqot maqsadida ishlatilishi
|
||||
uchun mo'ljallangan va ishlab chiqarishda ishlatilishi **mumkin emas**.
|
||||
|
||||
## Ma'lumotlar tuzilmalari
|
||||
|
||||
Ma'lumotlar tuzilmasi - bu kompyuterda ma'lumotlarni samarali tarzda
|
||||
olish va o'zgartirish uchun ularni tashkil etish va saqlashning ma'lum
|
||||
bir usuli. Ayniqsa, ma'lumotlar tuzilmasi ma'lumot qiymatlarining
|
||||
to'plami, ular orasidagi munosabatlar va ma'lumotlarga qo'llanilishi
|
||||
mumkin bo'lgan funksiyalar yoki operatsiyalardir.
|
||||
|
||||
`B` - Boshlang'ich, `A` - Ilg'or
|
||||
|
||||
- `B` [Bog'langan ro'yxat](src/data-structures/linked-list)
|
||||
- `B` [Ikki marta bog'langan ro'yxat](src/data-structures/doubly-linked-list)
|
||||
- `B` [Navbat](src/data-structures/queue)
|
||||
- `B` [Stek](src/data-structures/stack)
|
||||
- `B` [Hash jadvali](src/data-structures/hash-table)
|
||||
- `B` [Heap](src/data-structures/heap) - maksimal va minimal heap versiyalari
|
||||
- `B` [Ustuvor navbat](src/data-structures/priority-queue)
|
||||
- `A` [Trie](src/data-structures/trie)
|
||||
- `A` [Daraxt](src/data-structures/tree)
|
||||
- `A` [Ikkilik qidiruv daraxt](src/data-structures/tree/binary-search-tree)
|
||||
- `A` [AVL daraxt](src/data-structures/tree/avl-tree)
|
||||
- `A` [Qizil-qora daraxt](src/data-structures/tree/red-black-tree)
|
||||
- `A` [Segment daraxt](src/data-structures/tree/segment-tree) - min/max/sum diapazon so'rovlari bilan misollar
|
||||
- `A` [Fenwick daraxt](src/data-structures/tree/fenwick-tree) (ikkilik indeksli daraxt)
|
||||
- `A` [Graf](src/data-structures/graph) (yo'naltirilgan hamda yo'naltirilmagan)
|
||||
- `A` [Ajratilgan to'plam](src/data-structures/disjoint-set) - union-find ma'lumotlar strukturasi yoki merge-find to'plami
|
||||
- `A` [Bloom filtri](src/data-structures/bloom-filter)
|
||||
- `A` [LRU keshi](src/data-structures/lru-cache/) - Eng kam ishlatilgan (LRU) keshi
|
||||
|
||||
## Algoritmlar
|
||||
|
||||
Algoritm muammolar sinfini qanday hal qilishning aniq spetsifikatsiyasi. Bu operatsiyalar ketma-ketligini aniqlaydigan qoidalar to'plami.
|
||||
|
||||
`B` - Boshlang'ich, `A` - Ilg'or
|
||||
|
||||
### Mavzu bo'yicha algoritmlar
|
||||
|
||||
- **Matematika**
|
||||
- `B` [Bit manipulatsiyasi](src/algorithms/math/bits) - bitlarni qo'yish/olish/yangilash/tozalash, ikkilikka ko'paytirish/bo'lish, manfiy qilish va hokazo.
|
||||
- `B` [Ikkilik suzuvchi nuqta](src/algorithms/math/binary-floating-point) - suzuvchi nuqtali sonlarning ikkilik tasviri.
|
||||
- `B` [Faktorial](src/algorithms/math/factorial)
|
||||
- `B` [Fibonachchi raqam](src/algorithms/math/fibonacci) - klassik va yopiq shakldagi versiyalar
|
||||
- `B` [Asosiy omillar](src/algorithms/math/prime-factors) - tub omillarni topish va ularni Xardi-Ramanujan teoremasi yordamida sanash
|
||||
- `B` [Birlamchilik testi](src/algorithms/math/primality-test) (sinov bo'linish usuli)
|
||||
- `B` [Evklid algoritmi](src/algorithms/math/euclidean-algorithm) - eng katta umumiy bo'luvchini (EKUB) hisoblash
|
||||
- `B` [Eng kichik umumiy karrali](src/algorithms/math/least-common-multiple) (EKUK)
|
||||
- `B` [Eratosfen elagi](src/algorithms/math/sieve-of-eratosthenes) - berilgan chegaragacha barcha tub sonlarni topish
|
||||
- `B` [Ikkining darajasimi](src/algorithms/math/is-power-of-two) - raqamning ikkining darajasi ekanligini tekshirish (sodda va bitli algoritmlar)
|
||||
- `B` [Paskal uchburchagi](src/algorithms/math/pascal-triangle)
|
||||
- `B` [Kompleks sonlar](src/algorithms/math/complex-number) - kompleks sonlar va ular bilan asosiy amallar
|
||||
- `B` [Radian & Daraja](src/algorithms/math/radian) - radianlarni darajaga va orqaga aylantirish
|
||||
- `B` [Tez ko'tarish](src/algorithms/math/fast-powering)
|
||||
- `B` [Horner metodi](src/algorithms/math/horner-method) - polinomlarni baholash
|
||||
- `B` [Matritsalar](src/algorithms/math/matrix) - matritsalar va asosiy matritsa operatsiyalari (ko'paytirish, transpozitsiya va boshqalar).
|
||||
- `B` [Evklid masofasi](src/algorithms/math/euclidean-distance) - ikki nuqta/vektor/matritsa orasidagi masofa
|
||||
- `A` [Butun sonlarni bo'lish](src/algorithms/math/integer-partition)
|
||||
- `A` [Kvadrat ildiz](src/algorithms/math/square-root) - Nyuton metodi
|
||||
- `A` [Liu Hui π algoritmi](src/algorithms/math/liu-hui) - N-gonlarga asoslangan π ning taxminiy hisoblari
|
||||
- `A` [Diskret Furye transformatsiyasi](src/algorithms/math/fourier-transform) - vaqt funksiyasini (signalni) uni tashkil etuvchi chastotalarga ajratish
|
||||
- **Sets**
|
||||
- `B` [Karteziya maxsuloti](src/algorithms/sets/cartesian-product) - bir nechta to'plamlarning ko'paytmasi
|
||||
- `B` [Fisher–Yates Shuffle](src/algorithms/sets/fisher-yates) - chekli ketma-ketlikni tasodifiy almashtirish
|
||||
- `A` [Power Set](src/algorithms/sets/power-set) - to'plamning barcha kichik to'plamlari (bitwise, backtracking va kaskadli echimlar)
|
||||
- `A` [Permutatsiyalar](src/algorithms/sets/permutations) (takroriyalash bilan va takroriyalashsiz)
|
||||
- `A` [Kombinatsiyalar](src/algorithms/sets/combinations) (takroriyalash bilan va takroriyalashsiz)
|
||||
- `A` [Eng uzun umumiy ketma-ketlik](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||
- `A` [Eng uzun ortib boruvchi ketma-ketlik](src/algorithms/sets/longest-increasing-subsequence)
|
||||
- `A` [Eng qisqa umumiy ketma-ketlik](src/algorithms/sets/shortest-common-supersequence) (SCS)
|
||||
- `A` [Knapsack muammosi](src/algorithms/sets/knapsack-problem) - "0/1" va "Bir-biriga bog'lanmagan"
|
||||
- `A` [Maksimal kichik massiv](src/algorithms/sets/maximum-subarray) - Toʻliq kuch va dinamik dasturlash (Kadane usuli) versiyalari
|
||||
- `A` [Kombinatsiya yig'indisi](src/algorithms/sets/combination-sum) - ma'lum summani tashkil etuvchi barcha kombinatsiyalarni topish
|
||||
- **Stringlar**
|
||||
- `B` [Hamming masofasi](src/algorithms/string/hamming-distance) - belgilarning bir-biridan farq qiladigan pozitsiyalar soni
|
||||
- `B` [Palindrom](src/algorithms/string/palindrome) - satrning teskari tomoni ham bir xil ekanligini tekshirish
|
||||
- `A` [Levenshtein masofasi](src/algorithms/string/levenshtein-distance) - ikki ketma-ketlik o'rtasidagi minimal tahrirlash masofasi
|
||||
- `A` [Knuth–Morris–Pratt Algoritmi](src/algorithms/string/knuth-morris-pratt) (KMP Algoritmi) - kichik qatorlarni qidirish (mosh keluvchi naqshni qidirish)
|
||||
- `A` [Z Algoritmi](src/algorithms/string/z-algorithm) - kichik qatorlarni qidirish (mosh keluvchi naqshni qidirish)
|
||||
- `A` [Rabin Karp Algoritmi](src/algorithms/string/rabin-karp) - kichik qatorlarni qidirish
|
||||
- `A` [Eng uzun umumiy kichik matn](src/algorithms/string/longest-common-substring)
|
||||
- `A` [Regulyar ifoda moslashuvi](src/algorithms/string/regular-expression-matching) (RegEx)
|
||||
- **Qidiruvlar**
|
||||
- `B` [Linear qidirish](src/algorithms/search/linear-search)
|
||||
- `B` [Jump qidirish](src/algorithms/search/jump-search) (yoki Blok qidirish) - saralangan qatorda qidirish
|
||||
- `B` [Ikkilik qidirish](src/algorithms/search/binary-search) - saralangan qatorda qidirish
|
||||
- `B` [Interpolatsiya qidirish](src/algorithms/search/interpolation-search) - bir tekis taqsimlangan saralangan qatorda qidirish
|
||||
- **Tartiblash**
|
||||
- `B` [Pufakcha tartiblash](src/algorithms/sorting/bubble-sort)
|
||||
- `B` [Tanlash tartibi](src/algorithms/sorting/selection-sort)
|
||||
- `B` [Kiritish tartibi](src/algorithms/sorting/insertion-sort)
|
||||
- `B` [Heap tartibi](src/algorithms/sorting/heap-sort)
|
||||
- `B` [Birlashtirish tartibi](src/algorithms/sorting/merge-sort)
|
||||
- `B` [Tezkor saralash](src/algorithms/sorting/quick-sort) - joyida va joyida bo'lmagan amalga oshirish
|
||||
- `B` [Shell tartiblash](src/algorithms/sorting/shell-sort)
|
||||
- `B` [Sanash tartibi](src/algorithms/sorting/counting-sort)
|
||||
- `B` [Radiksli tartiblash](src/algorithms/sorting/radix-sort)
|
||||
- `B` [Bucket tartiblash](src/algorithms/sorting/bucket-sort)
|
||||
- **Bog'langan ro'yhatlar**
|
||||
- `B` [To'g'ri traversal](src/algorithms/linked-list/traversal)
|
||||
- `B` [Teskari traversal](src/algorithms/linked-list/reverse-traversal)
|
||||
- **Daraxtlar**
|
||||
- `B` [Birinchi-pastga qarab qidirish](src/algorithms/tree/depth-first-search) (Depth-First Search)
|
||||
- `B` [Birinchi-yonga qarab qidirish](src/algorithms/tree/breadth-first-search) (Breadth-First Search)
|
||||
- **Grafiklar**
|
||||
- `B` [Birinchi-pastga qarab qidirish](src/algorithms/graph/depth-first-search) (Depth-First Search)
|
||||
- `B` [Birinchi-yonga qarab qidirish](src/algorithms/graph/breadth-first-search) (Breadth-First Search)
|
||||
- `B` [Kruskal Algoritmi](src/algorithms/graph/kruskal) - og'irlikdagi yo'naltirilmagan grafik uchun Minimal kengayuvchi daraxtni (MST) topish
|
||||
- `A` [Dijkstra Algoritmi](src/algorithms/graph/dijkstra) - grafikning bir cho'qqisidan qolgan barcha nuqtalarga eng qisqa yo'llarni topish
|
||||
- `A` [Bellman-Ford Algoritmi](src/algorithms/graph/bellman-ford) - grafikning bir cho'qqisidan qolgan barcha nuqtalarga eng qisqa yo'llarni topish
|
||||
- `A` [Floyd-Warshall Algoritmi](src/algorithms/graph/floyd-warshall) - grafikning barcha uchlari orasidagi eng qisqa masofalarni topish
|
||||
- `A` [Siklni aniqlash](src/algorithms/graph/detect-cycle) - yo'naltirilgan va yo'naltirilmagan grafiklar uchun (DFS va Disjoint Set-ga asoslangan versiyalar)
|
||||
- `A` [Prim Algoritmi](src/algorithms/graph/prim) - og'irlikdagi yo'naltirilmagan grafik uchun Minimal kengayuvchi daraxtni (MST) topish
|
||||
- `A` [Topologik saralash](src/algorithms/graph/topological-sorting) - DFS metodi
|
||||
- `A` [Artikulyatsiya nuqtalari](src/algorithms/graph/articulation-points) - Tarjan algoritmi (DFS asosida)
|
||||
- `A` [Ko'priklar](src/algorithms/graph/bridges) - DFS asosidagi algoritm
|
||||
- `A` [Eyler yo'li va Eyler sxemasi](src/algorithms/graph/eulerian-path) - Fleury algoritmi - Har bir chekkaga bir marta tashrif buyurish
|
||||
- `A` [Gamilton sikli](src/algorithms/graph/hamiltonian-cycle) - Har bir cho'qqiga bir marta tashrif buyurish
|
||||
- `A` [Kuchli bog'langan komponentlar](src/algorithms/graph/strongly-connected-components) - Kosaraju algoritmi
|
||||
- `A` [Sayohatchi sotuvchi muammosi](src/algorithms/graph/travelling-salesman) - har bir shaharga tashrif buyuradigan va kelib chiqqan shaharga qaytib keladigan eng qisqa yo'l
|
||||
- **Kriptografiya**
|
||||
- `B` [Polynomial Hash](src/algorithms/cryptography/polynomial-hash) - polinomga asoslangan hash funktsiyasi
|
||||
- `B` [Rail Fence Cipher](src/algorithms/cryptography/rail-fence-cipher) - xabarlarni kodlash uchun transpozitsiya shifrlash algoritmi
|
||||
- `B` [Caesar Cipher](src/algorithms/cryptography/caesar-cipher) - oddiy almashtirish shifridir
|
||||
- `B` [Hill Cipher](src/algorithms/cryptography/hill-cipher) - chiziqli algebraga asoslangan almashtirish shifri
|
||||
- **Machine Learning**
|
||||
- `B` [NanoNeuron](https://github.com/trekhleb/nano-neuron) - Mashinalar aslida qanday o'rganishi mumkinligini ko'rsatadigan 7 ta oddiy JS funksiyasi (forward/backward tarqalish)
|
||||
- `B` [k-NN](src/algorithms/ml/knn) - eng yaqin qo'shnilarni tasniflash algoritmi
|
||||
- `B` [k-Means](src/algorithms/ml/k-means) - k-Means kalsterlash algoritmi
|
||||
- **Tasvirga ishlov berish**
|
||||
- `B` [Seam Carving](src/algorithms/image-processing/seam-carving) - kontentga moslashuvchan rasm o'lchamini o'zgartirish algoritmi
|
||||
- **Statistikalar**
|
||||
- `B` [Weighted Random](src/algorithms/statistics/weighted-random) - elementlarning og'irligi asosida ro'yxatdan tasodifiy elementni tanlash
|
||||
- **Evolyutsion algoritmlar**
|
||||
- `A` [Genetik algoritm](https://github.com/trekhleb/self-parking-car-evolution) - avtoturargohni o'rgatish uchun genetik algoritm qanday qo'llanilishiga misol.
|
||||
- **Kategoriyasiz**
|
||||
- `B` [Xanoy minorasi](src/algorithms/uncategorized/hanoi-tower)
|
||||
- `B` [Kvadrat matritsaning aylanishi](src/algorithms/uncategorized/square-matrix-rotation) - joyidagi algoritm
|
||||
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game) - orqaga qaytish, dinamik dasturlash (yuqoridan pastga + pastdan yuqoriga) va ochko'z misollar
|
||||
- `B` [Noyob yo'llar](src/algorithms/uncategorized/unique-paths) - orqaga qaytish, dinamik dasturlash va Paskal uchburchagiga asoslangan misolla
|
||||
- `B` [Yomg'ir teraslari](src/algorithms/uncategorized/rain-terraces) - yomg'ir suvini ushlab turish muammosi (dinamik dasturlash va qo'pol kuch versiyalari)
|
||||
- `B` [Rekursiv zinapoya](src/algorithms/uncategorized/recursive-staircase) - yuqoriga chiqish yo'llari sonini hisoblash (4 ta echim)
|
||||
- `B` [Aksiyalarni sotib olish va sotish uchun eng yaxshi vaqt](src/algorithms/uncategorized/best-time-to-buy-sell-stocks) - bo'linib-zabt etish va bir marta o'tish misollari
|
||||
- `A` [N-Queens Muommosi](src/algorithms/uncategorized/n-queens)
|
||||
- `A` [Ritsar sayohati](src/algorithms/uncategorized/knight-tour)
|
||||
|
||||
### Paradigma bo'yicha algoritmlar
|
||||
|
||||
Algorithmic paradigm - bu algoritmlar sinfini loyihalashtirishga asos bo'lib xizmat qiladigan umumiy usul yoki yondashuv. Bu algoritm tushunchasidan yuqori darajadagi abstraktsiya bo'lib, algoritm kompyuter dasturi tushunchasidan yuqori darajadagi abstraktsiya bo'lgani kabi.
|
||||
|
||||
- **Brute Force** - barcha imkoniyatlarni ko'rib chiqib va eng yaxshi echimni tanlash
|
||||
- `B` [Chiziqli qidirish](src/algorithms/search/linear-search)
|
||||
- `B` [Yomg'irli teraslar](src/algorithms/uncategorized/rain-terraces) - yomg'ir suvini to'plash muammosi
|
||||
- `B` [Rekursiv zinapoya](src/algorithms/uncategorized/recursive-staircase) - cho'qqiga chiqish yo'llari sonini hisoblash
|
||||
- `A` [Maksimal kichik massiv](src/algorithms/sets/maximum-subarray)
|
||||
- `A` [Sayohatchi sotuvchi muammosi](src/algorithms/graph/travelling-salesman) - har bir shaharga tashrif buyuradigan va kelib chiqqan shaharga qaytib keladigan eng qisqa yo'l
|
||||
- `A` [Diskret Furye transformatsiyasi](src/algorithms/math/fourier-transform) - vaqt funksiyasini (signalni) uni tashkil etuvchi chastotalarga ajratish
|
||||
- **Greedy** - kelajakni o'ylamasdan, hozirgi vaqtda eng yaxshi variantni tanlash
|
||||
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game)
|
||||
- `A` [Bog'lanmagan yukxalta muammosi](src/algorithms/sets/knapsack-problem)
|
||||
- `A` [Dijkstra Algoritmi](src/algorithms/graph/dijkstra) - grafikning bir cho'qqisidan qolgan barcha nuqtalarga eng qisqa yo'llarni topish
|
||||
- `A` [Prim Algoritmi](src/algorithms/graph/prim) - og'irlikdagi yo'naltirilmagan grafik uchun Minimal kengayuvchi daraxtni (MST) topish
|
||||
- `A` [Kruskal Algoritmi](src/algorithms/graph/kruskal) - og'irlikdagi yo'naltirilmagan grafik uchun Minimal kengayuvchi daraxtni (MST) topish
|
||||
- **Divide and Conquer** - muammoni kichikroq qismlarga bo'lib va keyin bu qismlarni hal qilish
|
||||
|
||||
- `B` [Ikkilik qidiruv](src/algorithms/search/binary-search)
|
||||
- `B` [Xanoy minorasi](src/algorithms/uncategorized/hanoi-tower)
|
||||
- `B` [Paskal uchburchagi](src/algorithms/math/pascal-triangle)
|
||||
- `B` [Evklid Algoritmi](src/algorithms/math/euclidean-algorithm) - eng katta umumiy bo'luvchini (EKUB) hisoblash
|
||||
- `B` [Birlashtirish tartibi](src/algorithms/sorting/merge-sort)
|
||||
- `B` [Tezkor saralash](src/algorithms/sorting/quick-sort)
|
||||
- `B` [Birinchi-pastga qarab qidirish daraxti](src/algorithms/tree/depth-first-search) (DFS)
|
||||
- `B` [Birinchi-pastga qarab qidirish grafigi](src/algorithms/graph/depth-first-search) (DFS)
|
||||
- `B` [Matritsalar](src/algorithms/math/matrix) - turli shakldagi matritsalarni hosil qilish va kesib o'tish
|
||||
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game)
|
||||
- `B` [Tez ko'tarish](src/algorithms/math/fast-powering)
|
||||
- `B` [Aksiyalarni sotib olish va sotish uchun eng yaxshi vaqt](src/algorithms/uncategorized/best-time-to-buy-sell-stocks) - bo'linib-zabt etish va bir marta o'tish misollari
|
||||
- `A` [Permutatsiyalar](src/algorithms/sets/permutations) (takroriyalash bilan va takroriyalashsiz)
|
||||
- `A` [Kombinatsiyalar](src/algorithms/sets/combinations) (takroriyalash bilan va takroriyalashsiz)
|
||||
- `A` [Maksimal kichik massiv](src/algorithms/sets/maximum-subarray)
|
||||
|
||||
- **Dinamik dasturlash** - ilgari topilgan kichik yechimlar yordamida yechim yaratish
|
||||
- `B` [Fibonachchi raqam](src/algorithms/math/fibonacci)
|
||||
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game)
|
||||
- `B` [Noyob yo'llar](src/algorithms/uncategorized/unique-paths)
|
||||
- `B` [Yomg'ir teraslari](src/algorithms/uncategorized/rain-terraces) - yomg'ir suvini to'plash muammosi
|
||||
- `B` [Recursive Staircase](src/algorithms/uncategorized/recursive-staircase) - count the number of ways to reach to the top
|
||||
- `B` [Seam Carving](src/algorithms/image-processing/seam-carving) - kontentga moslashuvchan rasm o'lchamini o'zgartirish algoritmi
|
||||
- `A` [Levenshtein masofasi](src/algorithms/string/levenshtein-distance) - ikki ketma-ketlik o'rtasidagi minimal tahrirlash masofasi
|
||||
- `A` [Eng uzun umumiy ketma-ketlik](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||
- `A` [Eng uzun umumiy kichik matn](src/algorithms/string/longest-common-substring)
|
||||
- `A` [Eng uzun ortib boruvchi ketma-ketlik](src/algorithms/sets/longest-increasing-subsequence)
|
||||
- `A` [Eng qisqa umumiy ketma-ketlik](src/algorithms/sets/shortest-common-supersequence)
|
||||
- `A` [0/1 Knapsak muommosi](src/algorithms/sets/knapsack-problem)
|
||||
- `A` [Butun sonlarni bo'lish](src/algorithms/math/integer-partition)
|
||||
- `A` [Maksimal kichik massiv](src/algorithms/sets/maximum-subarray)
|
||||
- `A` [Bellman-Ford Algoritmi](src/algorithms/graph/bellman-ford) - grafikning bir cho'qqisidan qolgan barcha nuqtalarga eng qisqa yo'llarni topish
|
||||
- `A` [Floyd-Warshall Algoritmi](src/algorithms/graph/floyd-warshall) -grafikning barcha uchlari orasidagi eng qisqa masofalarni topish
|
||||
- `A` [Regulyar ifoda moslashuvi](src/algorithms/string/regular-expression-matching)
|
||||
- **Backtracking** - brute forcega o'xshab, barcha mumkin bo'lgan yechimlarni generatsiya qilishga harakat qiladi, lekin har safar keyingi yechimni yaratganingizda, yechim barcha shartlarga javob beradimi yoki yo'qligini tekshirasiz va shundan keyingina keyingi yechimlarni ishlab chiqarishni davom ettirasiz. Aks holda, orqaga qaytib, yechim topishning boshqa yo'liga o'tasiz. Odatda state-space ning DFS-qidiruvi ishlatiladi.
|
||||
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game)
|
||||
- `B` [Noyob yo'llar](src/algorithms/uncategorized/unique-paths)
|
||||
- `B` [Power Set](src/algorithms/sets/power-set) - to'plamning barcha kichik to'plamlari
|
||||
- `A` [Gamilton sikli](src/algorithms/graph/hamiltonian-cycle) - Har bir cho'qqiga bir marta tashrif buyurish
|
||||
- `A` [N-Queens muommosi](src/algorithms/uncategorized/n-queens)
|
||||
- `A` [Ritsar sayohati](src/algorithms/uncategorized/knight-tour)
|
||||
- `A` [Kombinatsiya yig'indisi](src/algorithms/sets/combination-sum) - ma'lum summani tashkil etuvchi barcha kombinatsiyalarni topish
|
||||
- **Branch & Bound** - shu paytgacha topilgan eng arzon echimdan kattaroq xarajatlarga ega qisman echimlarni bekor qilish uchun, backtracking qidiruvining har bir bosqichida topilgan eng arzon echimni eslab qoling va shu paytgacha topilgan eng arzon yechim narxidan muammoni eng kam xarajatli yechim narxining past chegarasi sifatida foydalaning. Odatda state-space daraxtining DFS o'tishi bilan birgalikda BFS traversal qo'llaniladi.
|
||||
|
||||
## Ushbu repozitoriyadan qanday foydalanish kerak
|
||||
|
||||
**Barcha dependensiylarni o'rnating**
|
||||
|
||||
```
|
||||
npm install
|
||||
```
|
||||
|
||||
**ESLint ni ishga tushiring**
|
||||
|
||||
Kod sifatini tekshirish uchun ESLint ni ishga tushirishingiz mumkin.
|
||||
|
||||
```
|
||||
npm run lint
|
||||
```
|
||||
|
||||
**Barcha testlarni ishga tushuring**
|
||||
|
||||
```
|
||||
npm test
|
||||
```
|
||||
|
||||
**Testlarni nom bo'yicha ishga tushirish**
|
||||
|
||||
```
|
||||
npm test -- 'LinkedList'
|
||||
```
|
||||
|
||||
**Muammolarni bartaraf qilish (Troubleshooting)**
|
||||
|
||||
Agar linting yoki sinov muvaffaqiyatsiz bo'lsa, `node_modules` papkasini o'chirib, npm paketlarini qayta o'rnatishga harakat qiling:
|
||||
|
||||
```
|
||||
rm -rf ./node_modules
|
||||
npm i
|
||||
```
|
||||
|
||||
Shuningdek, to'g'ri Node versiyasidan foydalanayotganingizga ishonch hosil qiling (`>=16`). Agar Node versiyasini boshqarish uchun [nvm](https://github.com/nvm-sh/nvm) dan foydalanayotgan bo'lsangiz, loyihaning ildiz papkasidan `nvm use` ni ishga tushiring va to'g'ri versiya tanlanadi.
|
||||
|
||||
**O'yin maydoni (Playground)**
|
||||
|
||||
`./src/playground/playground.js` faylida ma'lumotlar strukturalari va algoritmlar bilan o'ynashingiz, `./src/playground/test/playground.test.js` faylida esa ular uchun testlar yozishingiz mumkin.
|
||||
|
||||
Shundan so'ng, playground kodingiz kutilgandek ishlashini tekshirish uchun quyidagi buyruqni ishga tushirishingiz kifoya:
|
||||
|
||||
```
|
||||
npm test -- 'playground'
|
||||
```
|
||||
|
||||
## Foydali ma'lumotlar
|
||||
|
||||
### Manbalar
|
||||
|
||||
- [▶ Data Structures and Algorithms on YouTube](https://www.youtube.com/playlist?list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
- [✍🏻 Data Structure Sketches](https://okso.app/showcase/data-structures)
|
||||
|
||||
### Big O Notation
|
||||
|
||||
_Big O notation_ algoritmlarni kirish hajmi oshgani sayin ularning ishlash vaqti yoki bo'sh joy talablari qanday o'sishiga qarab tasniflash uchun ishlatiladi. Quyidagi jadvalda siz Big O notatsiyasida ko'rsatilgan algoritmlarning o'sishining eng keng tarqalgan tartiblarini topishingiz mumkin.
|
||||
|
||||

|
||||
|
||||
Manba: [Big O Cheat Sheet](http://bigocheatsheet.com/).
|
||||
|
||||
Quyida eng ko'p qo'llaniladigan Big O notatsiyalarining ro'yxati va ularning kirish ma'lumotlarining turli o'lchamlariga nisbatan ishlashini taqqoslash keltirilgan.
|
||||
|
||||
| Big O Notatsiya | Turi | 10 ta element uchun hisob-kitoblar | 100 ta element uchun hisob-kitoblar | 1000 ta element uchun hisob-kitoblar |
|
||||
| --------------- | ------------ | ---------------------------------- | ----------------------------------- | ------------------------------------ |
|
||||
| **O(1)** | O'zgarmas | 1 | 1 | 1 |
|
||||
| **O(log N)** | Logarifmik | 3 | 6 | 9 |
|
||||
| **O(N)** | Chiziqli | 10 | 100 | 1000 |
|
||||
| **O(N log N)** | n log(n) | 30 | 600 | 9000 |
|
||||
| **O(N^2)** | Kvadrat | 100 | 10000 | 1000000 |
|
||||
| **O(2^N)** | Eksponensial | 1024 | 1.26e+29 | 1.07e+301 |
|
||||
| **O(N!)** | Faktorial | 3628800 | 9.3e+157 | 4.02e+2567 |
|
||||
|
||||
### Ma'lumotlar tuzilmalarining operatsiyalari murakkabligi
|
||||
|
||||
| Ma'lumotlar tuzilmalari | Kirish | Qidirish | Kiritish | O'chirish | Izohlar |
|
||||
| --------------------------- | :----: | :------: | :------: | :-------: | :--------------------------------------------------------- |
|
||||
| **Massiv** | 1 | n | n | n | |
|
||||
| **Stak** | n | n | 1 | 1 | |
|
||||
| **Navbat** | n | n | 1 | 1 | |
|
||||
| **Bog'langan ro'yhat** | n | n | 1 | n | |
|
||||
| **Hash jadval** | - | n | n | n | Mukammal xash funksiyasi bo'lsa, xarajatlar O (1) bo'ladi. |
|
||||
| **Ikkilik qidiruv daraxti** | n | n | n | n | Balanslangan daraxt narxida O(log(n)) bo'ladi. |
|
||||
| **B-daraxti** | log(n) | log(n) | log(n) | log(n) | |
|
||||
| **Qizil-qora daraxt** | log(n) | log(n) | log(n) | log(n) | |
|
||||
| **AVL Daraxt** | log(n) | log(n) | log(n) | log(n) | |
|
||||
| **Bloom filtri** | - | 1 | 1 | - | Qidiruv paytida noto'g'ri pozitivlar bo'lishi mumkin |
|
||||
|
||||
### Massivlarni saralash algoritmlarining murakkabligi
|
||||
|
||||
| Nomi | Eng yaxshi | O'rta | Eng yomon | Xotira | Barqaror | Izohlar |
|
||||
| ------------------------- | :-----------: | :---------------------: | :-------------------------: | :----: | :------: | :--------------------------------------------------------------------------- |
|
||||
| **Pufakcha tartiblash** | n | n<sup>2</sup> | n<sup>2</sup> | 1 | Ha | |
|
||||
| **Kiritish tartibi** | n | n<sup>2</sup> | n<sup>2</sup> | 1 | Ha | |
|
||||
| **Tanlash tartibi** | n<sup>2</sup> | n<sup>2</sup> | n<sup>2</sup> | 1 | Yo'q | |
|
||||
| **Heap tartibi** | n log(n) | n log(n) | n log(n) | 1 | Yo'q | |
|
||||
| **Birlashtirish tartibi** | n log(n) | n log(n) | n log(n) | n | Ha | |
|
||||
| **Tezkor saralash** | n log(n) | n log(n) | n<sup>2</sup> | log(n) | Yo'q | Tezkor saralash odatda O(log(n)) stek maydoni bilan joyida amalga oshiriladi |
|
||||
| **Shell tartiblash** | n log(n) | depends on gap sequence | n (log(n))<sup>2</sup> | 1 | Yo'q | |
|
||||
| **Sanash tartibi** | n + r | n + r | n + r | n + r | Ha | r - massivdagi eng katta raqam |
|
||||
| **Radiksli tartiblash** | n \* k | n \* k | n \* k | n + k | Ha | k - eng uzun kalitning uzunligi |
|
||||
|
||||
## Loyihani qo'llab-quvvatlovchilar
|
||||
|
||||
> Siz ushbu loyihani ❤️️ [GitHub](https://github.com/sponsors/trekhleb) yoki ❤️️ [Patreon](https://www.patreon.com/trekhleb) orqali qo'llab-quvvatlashingiz mumkin.
|
||||
|
||||
[Ushbu loyihani qo'llab-quvvatlagan odamlar](https://github.com/trekhleb/javascript-algorithms/blob/master/BACKERS.md) `∑ = 1`
|
||||
|
||||
## Muallif
|
||||
|
||||
[@trekhleb](https://trekhleb.dev)
|
||||
|
||||
A few more [projects](https://trekhleb.dev/projects/) and [articles](https://trekhleb.dev/blog/) about JavaScript and algorithms on [trekhleb.dev](https://trekhleb.dev)
|
||||
@ -23,7 +23,8 @@ _Read this in other languages:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
*注意:这个项目仅用于学习和研究,**不是**用于生产环境。*
|
||||
|
||||
|
||||
@ -22,7 +22,8 @@ _Read this in other languages:_
|
||||
[_Українська_](README.uk-UA.md),
|
||||
[_Arabic_](README.ar-AR.md),
|
||||
[_Tiếng Việt_](README.vi-VN.md),
|
||||
[_Deutsch_](README.de-DE.md)
|
||||
[_Deutsch_](README.de-DE.md),
|
||||
[_Uzbek_](README.uz-UZ.md)
|
||||
|
||||
## 資料結構
|
||||
|
||||
|
||||
@ -24,7 +24,9 @@ module.exports = {
|
||||
// This option sets the URL for the jsdom environment.
|
||||
// It is reflected in properties such as location.href.
|
||||
// @see: https://github.com/facebook/jest/issues/6769
|
||||
testURL: 'http://localhost/',
|
||||
testEnvironmentOptions: {
|
||||
url: 'http://localhost/',
|
||||
},
|
||||
|
||||
// @see: https://jestjs.io/docs/en/configuration#coveragethreshold-object
|
||||
coverageThreshold: {
|
||||
|
||||
14008
package-lock.json
generated
25
package.json
@ -35,21 +35,20 @@
|
||||
"prepare": "husky install"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@babel/cli": "7.16.8",
|
||||
"@babel/preset-env": "7.16.11",
|
||||
"@types/jest": "27.4.0",
|
||||
"canvas": "2.9.0",
|
||||
"eslint": "8.7.0",
|
||||
"@babel/cli": "7.20.7",
|
||||
"@babel/preset-env": "7.20.2",
|
||||
"@types/jest": "29.4.0",
|
||||
"eslint": "8.33.0",
|
||||
"eslint-config-airbnb": "19.0.4",
|
||||
"eslint-plugin-import": "2.25.4",
|
||||
"eslint-plugin-jest": "25.7.0",
|
||||
"eslint-plugin-jsx-a11y": "6.5.1",
|
||||
"eslint-plugin-react": "7.28.0",
|
||||
"husky": "7.0.4",
|
||||
"jest": "27.4.7"
|
||||
"eslint-plugin-import": "2.27.5",
|
||||
"eslint-plugin-jest": "27.2.1",
|
||||
"eslint-plugin-jsx-a11y": "6.7.1",
|
||||
"husky": "8.0.3",
|
||||
"jest": "29.4.1",
|
||||
"pngjs": "^7.0.0"
|
||||
},
|
||||
"engines": {
|
||||
"node": ">=14.16.0",
|
||||
"npm": ">=6.14.0"
|
||||
"node": ">=16.15.0",
|
||||
"npm": ">=8.5.5"
|
||||
}
|
||||
}
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# Breadth-First Search (BFS)
|
||||
|
||||
Breadth-first search (BFS) is an algorithm for traversing
|
||||
or searching tree or graph data structures. It starts at
|
||||
Breadth-first search (BFS) is an algorithm for traversing,
|
||||
searching tree, or graph data structures. It starts at
|
||||
the tree root (or some arbitrary node of a graph, sometimes
|
||||
referred to as a 'search key') and explores the neighbor
|
||||
nodes first, before moving to the next level neighbors.
|
||||
|
||||
@ -0,0 +1,85 @@
|
||||
import fs from 'fs';
|
||||
import { PNG } from 'pngjs';
|
||||
|
||||
import resizeImageWidth from '../resizeImageWidth';
|
||||
|
||||
const testImageBeforePath = './src/algorithms/image-processing/seam-carving/__tests__/test-image-before.png';
|
||||
const testImageAfterPath = './src/algorithms/image-processing/seam-carving/__tests__/test-image-after.png';
|
||||
|
||||
/**
|
||||
* Compares two images and finds the number of different pixels.
|
||||
*
|
||||
* @param {ImageData} imgA - ImageData for the first image.
|
||||
* @param {ImageData} imgB - ImageData for the second image.
|
||||
* @param {number} threshold - Color difference threshold [0..255]. Smaller - stricter.
|
||||
* @returns {number} - Number of different pixels.
|
||||
*/
|
||||
function pixelsDiff(imgA, imgB, threshold = 0) {
|
||||
if (imgA.width !== imgB.width || imgA.height !== imgB.height) {
|
||||
throw new Error('Images must have the same size');
|
||||
}
|
||||
|
||||
let differentPixels = 0;
|
||||
const numColorParams = 4; // RGBA
|
||||
|
||||
for (let pixelIndex = 0; pixelIndex < imgA.data.length; pixelIndex += numColorParams) {
|
||||
// Get pixel's color for each image.
|
||||
const [aR, aG, aB] = imgA.data.subarray(pixelIndex, pixelIndex + numColorParams);
|
||||
const [bR, bG, bB] = imgB.data.subarray(pixelIndex, pixelIndex + numColorParams);
|
||||
|
||||
// Get average pixel's color for each image (make them greyscale).
|
||||
const aAvgColor = Math.floor((aR + aG + aB) / 3);
|
||||
const bAvgColor = Math.floor((bR + bG + bB) / 3);
|
||||
|
||||
// Compare pixel colors.
|
||||
if (Math.abs(aAvgColor - bAvgColor) > threshold) {
|
||||
differentPixels += 1;
|
||||
}
|
||||
}
|
||||
|
||||
return differentPixels;
|
||||
}
|
||||
|
||||
const pngLoad = (path) => new Promise((resolve) => {
|
||||
fs.createReadStream(path)
|
||||
.pipe(new PNG())
|
||||
.on('parsed', function Parsed() {
|
||||
/** @type {ImageData} */
|
||||
const imageData = {
|
||||
colorSpace: 'srgb',
|
||||
width: this.width,
|
||||
height: this.height,
|
||||
data: this.data,
|
||||
};
|
||||
resolve(imageData);
|
||||
});
|
||||
});
|
||||
|
||||
describe('resizeImageWidth', () => {
|
||||
it('should perform content-aware image width reduction', async () => {
|
||||
const imgBefore = await pngLoad(testImageBeforePath);
|
||||
const imgAfter = await pngLoad(testImageAfterPath);
|
||||
|
||||
const toWidth = Math.floor(imgBefore.width / 2);
|
||||
|
||||
const {
|
||||
img: imgResized,
|
||||
size: resizedSize,
|
||||
} = resizeImageWidth({ img: imgBefore, toWidth });
|
||||
|
||||
expect(imgResized).toBeDefined();
|
||||
expect(resizedSize).toBeDefined();
|
||||
|
||||
expect(resizedSize).toEqual({ w: toWidth, h: imgBefore.height });
|
||||
expect(imgResized.width).toBe(imgAfter.width);
|
||||
expect(imgResized.height).toBe(imgAfter.height);
|
||||
|
||||
const colorThreshold = 50;
|
||||
const differentPixels = pixelsDiff(imgResized, imgAfter, colorThreshold);
|
||||
|
||||
// Allow 10% of pixels to be different
|
||||
const pixelsThreshold = Math.floor((imgAfter.width * imgAfter.height) / 10);
|
||||
|
||||
expect(differentPixels).toBeLessThanOrEqual(pixelsThreshold);
|
||||
});
|
||||
});
|
||||
@ -1,91 +0,0 @@
|
||||
import { createCanvas, loadImage } from 'canvas';
|
||||
import resizeImageWidth from '../resizeImageWidth';
|
||||
|
||||
const testImageBeforePath = './src/algorithms/image-processing/seam-carving/__tests__/test-image-before.jpg';
|
||||
const testImageAfterPath = './src/algorithms/image-processing/seam-carving/__tests__/test-image-after.jpg';
|
||||
|
||||
/**
|
||||
* Compares two images and finds the number of different pixels.
|
||||
*
|
||||
* @param {ImageData} imgA - ImageData for the first image.
|
||||
* @param {ImageData} imgB - ImageData for the second image.
|
||||
* @param {number} threshold - Color difference threshold [0..255]. Smaller - stricter.
|
||||
* @returns {number} - Number of different pixels.
|
||||
*/
|
||||
function pixelsDiff(imgA, imgB, threshold = 0) {
|
||||
if (imgA.width !== imgB.width || imgA.height !== imgB.height) {
|
||||
throw new Error('Images must have the same size');
|
||||
}
|
||||
|
||||
let differentPixels = 0;
|
||||
const numColorParams = 4; // RGBA
|
||||
|
||||
for (let pixelIndex = 0; pixelIndex < imgA.data.length; pixelIndex += numColorParams) {
|
||||
// Get pixel's color for each image.
|
||||
const [aR, aG, aB] = imgA.data.subarray(pixelIndex, pixelIndex + numColorParams);
|
||||
const [bR, bG, bB] = imgB.data.subarray(pixelIndex, pixelIndex + numColorParams);
|
||||
|
||||
// Get average pixel's color for each image (make them greyscale).
|
||||
const aAvgColor = Math.floor((aR + aG + aB) / 3);
|
||||
const bAvgColor = Math.floor((bR + bG + bB) / 3);
|
||||
|
||||
// Compare pixel colors.
|
||||
if (Math.abs(aAvgColor - bAvgColor) > threshold) {
|
||||
differentPixels += 1;
|
||||
}
|
||||
}
|
||||
|
||||
return differentPixels;
|
||||
}
|
||||
|
||||
describe('resizeImageWidth', () => {
|
||||
it('should perform content-aware image width reduction', () => {
|
||||
// @see: https://jestjs.io/docs/asynchronous
|
||||
return Promise.all([
|
||||
loadImage(testImageBeforePath),
|
||||
loadImage(testImageAfterPath),
|
||||
]).then(([imgBefore, imgAfter]) => {
|
||||
// Original image.
|
||||
const canvasBefore = createCanvas(imgBefore.width, imgBefore.height);
|
||||
const ctxBefore = canvasBefore.getContext('2d');
|
||||
ctxBefore.drawImage(imgBefore, 0, 0, imgBefore.width, imgBefore.height);
|
||||
const imgDataBefore = ctxBefore.getImageData(0, 0, imgBefore.width, imgBefore.height);
|
||||
|
||||
// Resized image saved.
|
||||
const canvasAfter = createCanvas(imgAfter.width, imgAfter.height);
|
||||
const ctxAfter = canvasAfter.getContext('2d');
|
||||
ctxAfter.drawImage(imgAfter, 0, 0, imgAfter.width, imgAfter.height);
|
||||
const imgDataAfter = ctxAfter.getImageData(0, 0, imgAfter.width, imgAfter.height);
|
||||
|
||||
const toWidth = Math.floor(imgBefore.width / 2);
|
||||
|
||||
const {
|
||||
img: resizedImg,
|
||||
size: resizedSize,
|
||||
} = resizeImageWidth({ img: imgDataBefore, toWidth });
|
||||
|
||||
expect(resizedImg).toBeDefined();
|
||||
expect(resizedSize).toBeDefined();
|
||||
|
||||
// Resized image generated.
|
||||
const canvasTest = createCanvas(resizedSize.w, resizedSize.h);
|
||||
const ctxTest = canvasTest.getContext('2d');
|
||||
ctxTest.putImageData(resizedImg, 0, 0, 0, 0, resizedSize.w, resizedSize.h);
|
||||
const imgDataTest = ctxTest.getImageData(0, 0, resizedSize.w, resizedSize.h);
|
||||
|
||||
expect(resizedSize).toEqual({ w: toWidth, h: imgBefore.height });
|
||||
expect(imgDataTest.width).toBe(toWidth);
|
||||
expect(imgDataTest.height).toBe(imgBefore.height);
|
||||
expect(imgDataTest.width).toBe(imgAfter.width);
|
||||
expect(imgDataTest.height).toBe(imgAfter.height);
|
||||
|
||||
const colorThreshold = 50;
|
||||
const differentPixels = pixelsDiff(imgDataTest, imgDataAfter, colorThreshold);
|
||||
|
||||
// Allow 10% of pixels to be different
|
||||
const pixelsThreshold = Math.floor((imgAfter.width * imgAfter.height) / 10);
|
||||
|
||||
expect(differentPixels).toBeLessThanOrEqual(pixelsThreshold);
|
||||
});
|
||||
});
|
||||
});
|
||||
{kind=link}
|
Before Width: | Height: | Size: 5.9 KiB |
{kind=link}
|
After Width: | Height: | Size: 6.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.3 KiB |
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
@ -1,7 +1,8 @@
|
||||
# Reversed Linked List Traversal
|
||||
|
||||
_Read this in other languages:_
|
||||
[中文](README.zh-CN.md)
|
||||
[_中文_](README.zh-CN.md),
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
The task is to traverse the given linked list in reversed order.
|
||||
|
||||
|
||||
23
src/algorithms/linked-list/reverse-traversal/README.pt-BR.md
Normal file
@ -0,0 +1,23 @@
|
||||
# Travessia de Lista Encadeada Reversa
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_中文_](README.zh-CN.md),
|
||||
[_English_](README.md)
|
||||
|
||||
A tarefa é percorrer a lista encadeada fornecida em ordem inversa.
|
||||
|
||||
Por exemplo, para a seguinte lista vinculada:
|
||||
|
||||

|
||||
|
||||
A ordem de travessia deve ser:
|
||||
|
||||
```texto
|
||||
37 → 99 → 12
|
||||
```
|
||||
|
||||
A complexidade de tempo é `O(n)` porque visitamos cada nó apenas uma vez.
|
||||
|
||||
## Referência
|
||||
|
||||
- [Wikipedia](https://en.wikipedia.org/wiki/Linked_list)
|
||||
@ -2,7 +2,8 @@
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Русский_](README.ru-RU.md),
|
||||
[中文](README.zh-CN.md)
|
||||
[_中文_](README.zh-CN.md),
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
The task is to traverse the given linked list in straight order.
|
||||
|
||||
|
||||
24
src/algorithms/linked-list/traversal/README.pt-BR.md
Normal file
@ -0,0 +1,24 @@
|
||||
# Travessia de Lista Encadeada
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_Русский_](README.ru-RU.md),
|
||||
[_中文_](README.zh-CN.md),
|
||||
[_English_](README.md)
|
||||
|
||||
A tarefa é percorrer a lista encadeada fornecida em ordem direta.
|
||||
|
||||
Por exemplo, para a seguinte lista vinculada:
|
||||
|
||||

|
||||
|
||||
A ordem de travessia deve ser:
|
||||
|
||||
```texto
|
||||
12 → 99 → 37
|
||||
```
|
||||
|
||||
A complexidade de tempo é `O(n)` porque visitamos cada nó apenas uma vez.
|
||||
|
||||
## Referência
|
||||
|
||||
- [Wikipedia](https://en.wikipedia.org/wiki/Linked_list)
|
||||
32
src/algorithms/math/factorial/README.ka-GE.md
Normal file
@ -0,0 +1,32 @@
|
||||
# ფაქტორიალი
|
||||
|
||||
მათემატიკაში `n` ნატურალური რიცხვის ფაქტორიალი
|
||||
(აღინიშნება `n!` სიმბოლოთი)
|
||||
არის ყველა ნატურალური რიცხვის ნამრავლი 1-იდან `n`-ის ჩათვლით. მაგალითად:
|
||||
|
||||
```
|
||||
5! = 5 * 4 * 3 * 2 * 1 = 120
|
||||
```
|
||||
|
||||
| n | n! |
|
||||
| --- | ----------------: |
|
||||
| 0 | 1 |
|
||||
| 1 | 1 |
|
||||
| 2 | 2 |
|
||||
| 3 | 6 |
|
||||
| 4 | 24 |
|
||||
| 5 | 120 |
|
||||
| 6 | 720 |
|
||||
| 7 | 5 040 |
|
||||
| 8 | 40 320 |
|
||||
| 9 | 362 880 |
|
||||
| 10 | 3 628 800 |
|
||||
| 11 | 39 916 800 |
|
||||
| 12 | 479 001 600 |
|
||||
| 13 | 6 227 020 800 |
|
||||
| 14 | 87 178 291 200 |
|
||||
| 15 | 1 307 674 368 000 |
|
||||
|
||||
## სქოლიო
|
||||
|
||||
[Wikipedia](https://ka.wikipedia.org/wiki/%E1%83%9B%E1%83%90%E1%83%97%E1%83%94%E1%83%9B%E1%83%90%E1%83%A2%E1%83%98%E1%83%99%E1%83%A3%E1%83%A0%E1%83%98_%E1%83%A4%E1%83%90%E1%83%A5%E1%83%A2%E1%83%9D%E1%83%A0%E1%83%98%E1%83%90%E1%83%9A%E1%83%98)
|
||||
@ -1,7 +1,7 @@
|
||||
# Factorial
|
||||
|
||||
_Read this in other languages:_
|
||||
[_简体中文_](README.zh-CN.md), [français](README.fr-FR.md), [turkish](README.tr-TR.md).
|
||||
[_简体中文_](README.zh-CN.md), [_Français_](README.fr-FR.md), [_Türkçe_](README.tr-TR.md), [_ქართული_](README.ka-GE.md), [_Українська_](README.uk-UA.md).
|
||||
|
||||
In mathematics, the factorial of a non-negative integer `n`,
|
||||
denoted by `n!`, is the product of all positive integers less
|
||||
|
||||
33
src/algorithms/math/factorial/README.uk-UA.md
Normal file
@ -0,0 +1,33 @@
|
||||
# Факторіал
|
||||
|
||||
_Прочитайте це іншими мовами:_
|
||||
[_English_](README.md), [_简体中文_](README.zh-CN.md), [_Français_](README.fr-FR.md), [_Türkçe_](README.tr-TR.md), [_ქართული_](README.ka-GE.md).
|
||||
|
||||
У математиці факторіал невід'ємного цілого числа `n`, позначений `n!`, є добутком усіх натуральних чисел, менших або рівних `n`. Наприклад:
|
||||
|
||||
```
|
||||
5! = 5 * 4 * 3 * 2 * 1 = 120
|
||||
```
|
||||
|
||||
| n | n! |
|
||||
| --- | ----------------: |
|
||||
| 0 | 1 |
|
||||
| 1 | 1 |
|
||||
| 2 | 2 |
|
||||
| 3 | 6 |
|
||||
| 4 | 24 |
|
||||
| 5 | 120 |
|
||||
| 6 | 720 |
|
||||
| 7 | 5 040 |
|
||||
| 8 | 40 320 |
|
||||
| 9 | 362 880 |
|
||||
| 10 | 3 628 800 |
|
||||
| 11 | 39 916 800 |
|
||||
| 12 | 479 001 600 |
|
||||
| 13 | 6 227 020 800 |
|
||||
| 14 | 87 178 291 200 |
|
||||
| 15 | 1 307 674 368 000 |
|
||||
|
||||
## Посилання
|
||||
|
||||
[Wikipedia](https://uk.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BA%D1%82%D0%BE%D1%80%D1%96%D0%B0%D0%BB)
|
||||
@ -1,7 +1,8 @@
|
||||
# Nombre de Fibonacci
|
||||
|
||||
_Read this in other languages:_
|
||||
[english](README.md).
|
||||
[english](README.md),
|
||||
[ქართული](README.ka-GE.md).
|
||||
|
||||
En mathématiques, la suite de Fibonacci est une suite d'entiers
|
||||
dans laquelle chaque terme (après les deux premiers)
|
||||
|
||||
20
src/algorithms/math/fibonacci/README.ka-GE.md
Normal file
@ -0,0 +1,20 @@
|
||||
# ფიბონაჩის რიცხვი
|
||||
|
||||
მათემატიკაში ფიბონაჩის მიმდევრობა წარმოადგენს მთელ რიცხვთა მიმდევრობას,
|
||||
რომელშიც ყოველი რიცხვი (პირველი ორი რიცხვის შემდეგ)
|
||||
მისი წინამორბედი ორი რიცხვის
|
||||
ჯამის ტოლია:
|
||||
|
||||
`0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ...`
|
||||
|
||||
კვადრატების წყობა, სადაც ყოველი კვადრატის გვერდების სიგრძე, თანმიმდევრობით, ფიბონაჩის რიცხვებს შეესაბამება
|
||||
|
||||

|
||||
|
||||
ფიბონაჩის სპირალი: ოქროს სპირალის აპროქსიმაცია, რომელიც შექმნილია კვადრატების მოპირდაპირე კუთხეებს შორის შემაერთებელი რკალების გავლებით;[4] ამ შემთხვევაში, გამოყენებულ კვადრატთა [გვერდების] ზომებია: 1, 1, 2, 3, 5, 8, 13 და 21.
|
||||
|
||||

|
||||
|
||||
## სქოლიო
|
||||
|
||||
- [Wikipedia](https://en.wikipedia.org/wiki/Fibonacci_number)
|
||||
@ -2,7 +2,8 @@
|
||||
|
||||
_Read this in other languages:_
|
||||
[français](README.fr-FR.md),
|
||||
[简体中文](README.zh-CN.md).
|
||||
[简体中文](README.zh-CN.md),
|
||||
[ქართული](README.ka-GE.md).
|
||||
|
||||
In mathematics, the Fibonacci numbers are the numbers in the following
|
||||
integer sequence, called the Fibonacci sequence, and characterized by
|
||||
|
||||
@ -2,7 +2,8 @@
|
||||
|
||||
_Read this in other languages:_
|
||||
[français](README.fr-FR.md),
|
||||
[english](README.md).
|
||||
[english](README.md),
|
||||
[ქართული](README.ka-GE.md).
|
||||
|
||||
在数学中,斐波那契数是以下整数序列(称为斐波那契数列)中的数字,其特征在于前两个数字之后的每个数字都是前两个数字的和:
|
||||
|
||||
|
||||
@ -1,5 +1,8 @@
|
||||
# k-Means Algorithm
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
The **k-Means algorithm** is an unsupervised Machine Learning algorithm. It's a clustering algorithm, which groups the sample data on the basis of similarity between dimensions of vectors.
|
||||
|
||||
In k-Means classification, the output is a set of classes assigned to each vector. Each cluster location is continuously optimized in order to get the accurate locations of each cluster such that they represent each group clearly.
|
||||
@ -27,6 +30,11 @@ _Image source: [Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering)_
|
||||
|
||||
The centroids are moving continuously in order to create better distinction between the different set of data points. As we can see, after a few iterations, the difference in centroids is quite low between iterations. For example between iterations `13` and `14` the difference is quite small because there the optimizer is tuning boundary cases.
|
||||
|
||||
## Code Examples
|
||||
|
||||
- [kMeans.js](./kMeans.js)
|
||||
- [kMeans.test.js](./__test__/kMeans.test.js) (test cases)
|
||||
|
||||
## References
|
||||
|
||||
- [k-Means neighbors algorithm on Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering)
|
||||
|
||||
35
src/algorithms/ml/k-means/README.pt-BR.md
Normal file
@ -0,0 +1,35 @@
|
||||
# Algoritmo k-Means
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md)
|
||||
|
||||
O **algoritmo k-Means** é um algoritmo de aprendizado de máquina não supervisionado. É um algoritmo de agrupamento, que agrupa os dados da amostra com base na semelhança entre as dimensões dos vetores.
|
||||
|
||||
Na classificação k-Means, a saída é um conjunto de classes atribuídas a cada vetor. Cada localização de cluster é continuamente otimizada para obter as localizações precisas de cada cluster de forma que representem cada grupo claramente.
|
||||
|
||||
A ideia é calcular a similaridade entre a localização do cluster e os vetores de dados e reatribuir os clusters com base nela. [Distância Euclidiana](https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/math/euclidean-distance) é usado principalmente para esta tarefa.
|
||||
|
||||

|
||||
|
||||
_Fonte: [Wikipedia](https://en.wikipedia.org/wiki/Euclidean_distance)_
|
||||
|
||||
O algoritmo é o seguinte:
|
||||
|
||||
1. Verifique se há erros como dados inválidos/inconsistentes
|
||||
2. Inicialize os locais do cluster `k` com pontos `k` iniciais/aleatórios
|
||||
3. Calcule a distância de cada ponto de dados de cada cluster
|
||||
4. Atribua o rótulo do cluster de cada ponto de dados igual ao do cluster em sua distância mínima
|
||||
5. Calcule o centroide de cada cluster com base nos pontos de dados que ele contém
|
||||
6. Repita cada uma das etapas acima até que as localizações do centroide estejam variando
|
||||
|
||||
Aqui está uma visualização do agrupamento k-Means para melhor compreensão:
|
||||
|
||||

|
||||
|
||||
_Fonte: [Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering)_
|
||||
|
||||
Os centroides estão se movendo continuamente para criar uma melhor distinção entre os diferentes conjuntos de pontos de dados. Como podemos ver, após algumas iterações, a diferença de centroides é bastante baixa entre as iterações. Por exemplo, entre as iterações `13` e `14` a diferença é bem pequena porque o otimizador está ajustando os casos limite.
|
||||
|
||||
## Referências
|
||||
|
||||
- [k-Means neighbors algorithm on Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering)
|
||||
@ -1,5 +1,8 @@
|
||||
# k-Nearest Neighbors Algorithm
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
The **k-nearest neighbors algorithm (k-NN)** is a supervised Machine Learning algorithm. It's a classification algorithm, determining the class of a sample vector using a sample data.
|
||||
|
||||
In k-NN classification, the output is a class membership. An object is classified by a plurality vote of its neighbors, with the object being assigned to the class most common among its `k` nearest neighbors (`k` is a positive integer, typically small). If `k = 1`, then the object is simply assigned to the class of that single nearest neighbor.
|
||||
|
||||
44
src/algorithms/ml/knn/README.pt-BR.md
Normal file
@ -0,0 +1,44 @@
|
||||
# Algoritmo de k-vizinhos mais próximos
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md)
|
||||
|
||||
O **algoritmo de k-vizinhos mais próximos (k-NN)** é um algoritmo de aprendizado de máquina supervisionado. É um algoritmo de classificação, determinando a classe de um vetor de amostra usando dados de amostra.
|
||||
|
||||
Na classificação k-NN, a saída é uma associação de classe. Um objeto é classificado por uma pluralidade de votos de seus vizinhos, com o objeto sendo atribuído à classe mais comum entre seus `k` vizinhos mais próximos (`k` é um inteiro positivo, tipicamente pequeno). Se `k = 1`, então o objeto é simplesmente atribuído à classe daquele único vizinho mais próximo.
|
||||
|
||||
The idea is to calculate the similarity between two data points on the basis of a distance metric. [Distância Euclidiana](https://github.com/trekhleb/javascript-algorithms/tree/master/src/algorithms/math/euclidean-distance) é usado principalmente para esta tarefa.
|
||||
|
||||

|
||||
|
||||
_Fonte: [Wikipedia](https://en.wikipedia.org/wiki/Euclidean_distance)_
|
||||
|
||||
O algoritmo é o seguinte:
|
||||
|
||||
1. Verifique se há erros como dados/rótulos inválidos.
|
||||
2. Calcule a distância euclidiana de todos os pontos de dados nos dados de treinamento com o ponto de classificação
|
||||
3. Classifique as distâncias dos pontos junto com suas classes em ordem crescente
|
||||
4. Pegue as classes iniciais `K` e encontre o modo para obter a classe mais semelhante
|
||||
5. Informe a classe mais semelhante
|
||||
|
||||
Aqui está uma visualização da classificação k-NN para melhor compreensão:
|
||||
|
||||

|
||||
|
||||
_Fonte: [Wikipedia](https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm)_
|
||||
|
||||
A amostra de teste (ponto verde) deve ser classificada em quadrados azuis ou em triângulos vermelhos. Se `k = 3` (círculo de linha sólida) é atribuído aos triângulos vermelhos porque existem `2` triângulos e apenas `1` quadrado dentro do círculo interno. Se `k = 5` (círculo de linha tracejada) é atribuído aos quadrados azuis (`3` quadrados vs. `2` triângulos dentro do círculo externo).
|
||||
|
||||
Outro exemplo de classificação k-NN:
|
||||
|
||||
|
||||
|
||||
_Fonte: [GeeksForGeeks](https://media.geeksforgeeks.org/wp-content/uploads/graph2-2.png)_
|
||||
|
||||
Aqui, como podemos ver, a classificação dos pontos desconhecidos será julgada pela proximidade com outros pontos.
|
||||
|
||||
É importante notar que `K` é preferível ter valores ímpares para desempate. Normalmente `K` é tomado como `3` ou `5`.
|
||||
|
||||
## Referências
|
||||
|
||||
- [k-nearest neighbors algorithm on Wikipedia](https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm)
|
||||
@ -11,7 +11,7 @@ import Comparator from '../../../utils/comparator/Comparator';
|
||||
|
||||
export default function binarySearch(sortedArray, seekElement, comparatorCallback) {
|
||||
// Let's create comparator from the comparatorCallback function.
|
||||
// Comparator object will give us common comparison methods like equal() and lessThen().
|
||||
// Comparator object will give us common comparison methods like equal() and lessThan().
|
||||
const comparator = new Comparator(comparatorCallback);
|
||||
|
||||
// These two indices will contain current array (sub-array) boundaries.
|
||||
|
||||
@ -5,14 +5,14 @@ When the order doesn't matter, it is a **Combination**.
|
||||
When the order **does** matter it is a **Permutation**.
|
||||
|
||||
**"My fruit salad is a combination of apples, grapes and bananas"**
|
||||
We don't care what order the fruits are in, they could also be
|
||||
"bananas, grapes and apples" or "grapes, apples and bananas",
|
||||
We don't care what order the fruits are in, they could also be
|
||||
"bananas, grapes and apples" or "grapes, apples and bananas",
|
||||
its the same fruit salad.
|
||||
|
||||
## Combinations without repetitions
|
||||
|
||||
This is how lotteries work. The numbers are drawn one at a
|
||||
time, and if we have the lucky numbers (no matter what order)
|
||||
This is how lotteries work. The numbers are drawn one at a
|
||||
time, and if we have the lucky numbers (no matter what order)
|
||||
we win!
|
||||
|
||||
No Repetition: such as lottery numbers `(2,14,15,27,30,33)`
|
||||
@ -30,12 +30,12 @@ It is often called "n choose r" (such as "16 choose 3"). And is also known as th
|
||||
|
||||
Repetition is Allowed: such as coins in your pocket `(5,5,5,10,10)`
|
||||
|
||||
Or let us say there are five flavours of ice cream:
|
||||
Or let us say there are five flavours of ice cream:
|
||||
`banana`, `chocolate`, `lemon`, `strawberry` and `vanilla`.
|
||||
|
||||
We can have three scoops. How many variations will there be?
|
||||
|
||||
Let's use letters for the flavours: `{b, c, l, s, v}`.
|
||||
Let's use letters for the flavours: `{b, c, l, s, v}`.
|
||||
Example selections include:
|
||||
|
||||
- `{c, c, c}` (3 scoops of chocolate)
|
||||
@ -46,23 +46,21 @@ Example selections include:
|
||||
|
||||
|
||||
|
||||
Where `n` is the number of things to choose from, and we
|
||||
choose `r` of them. Repetition allowed,
|
||||
Where `n` is the number of things to choose from, and we
|
||||
choose `r` of them. Repetition allowed,
|
||||
order doesn't matter.
|
||||
|
||||
## Cheat Sheets
|
||||
## Cheatsheet
|
||||
|
||||
Permutations cheat sheet
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
Combinations cheat sheet
|
||||
| | |
|
||||
| --- | --- |
|
||||
| |  |
|
||||
|
||||

|
||||
|
||||
Permutations/combinations algorithm ideas.
|
||||
|
||||
|
||||
*Made with [okso.app](https://okso.app)*
|
||||
|
||||
## References
|
||||
|
||||
|
||||
{kind=link}
|
After Width: | Height: | Size: 345 KiB |
{kind=link}
|
After Width: | Height: | Size: 324 KiB |
{kind=link}
|
After Width: | Height: | Size: 302 KiB |
BIN
src/algorithms/sets/combinations/images/overview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
@ -0,0 +1,17 @@
|
||||
import longestCommonSubsequence from '../longestCommonSubsequenceRecursive';
|
||||
|
||||
describe('longestCommonSubsequenceRecursive', () => {
|
||||
it('should find longest common substring between two strings', () => {
|
||||
expect(longestCommonSubsequence('', '')).toBe('');
|
||||
expect(longestCommonSubsequence('ABC', '')).toBe('');
|
||||
expect(longestCommonSubsequence('', 'ABC')).toBe('');
|
||||
expect(longestCommonSubsequence('ABABC', 'BABCA')).toBe('BABC');
|
||||
expect(longestCommonSubsequence('BABCA', 'ABCBA')).toBe('ABCA');
|
||||
expect(longestCommonSubsequence('sea', 'eat')).toBe('ea');
|
||||
expect(longestCommonSubsequence('algorithms', 'rithm')).toBe('rithm');
|
||||
expect(longestCommonSubsequence(
|
||||
'Algorithms and data structures implemented in JavaScript',
|
||||
'Here you may find Algorithms and data structures that are implemented in JavaScript',
|
||||
)).toBe('Algorithms and data structures implemented in JavaScript');
|
||||
});
|
||||
});
|
||||
@ -0,0 +1,36 @@
|
||||
/* eslint-disable no-param-reassign */
|
||||
/**
|
||||
* Longest Common Subsequence (LCS) (Recursive Approach).
|
||||
*
|
||||
* @param {string} string1
|
||||
* @param {string} string2
|
||||
* @return {number}
|
||||
*/
|
||||
export default function longestCommonSubsequenceRecursive(string1, string2) {
|
||||
/**
|
||||
*
|
||||
* @param {string} s1
|
||||
* @param {string} s2
|
||||
* @return {string} - returns the LCS (Longest Common Subsequence)
|
||||
*/
|
||||
const lcs = (s1, s2, memo = {}) => {
|
||||
if (!s1 || !s2) return '';
|
||||
|
||||
if (memo[`${s1}:${s2}`]) return memo[`${s1}:${s2}`];
|
||||
|
||||
if (s1[0] === s2[0]) {
|
||||
return s1[0] + lcs(s1.substring(1), s2.substring(1), memo);
|
||||
}
|
||||
|
||||
const nextLcs1 = lcs(s1.substring(1), s2, memo);
|
||||
const nextLcs2 = lcs(s1, s2.substring(1), memo);
|
||||
|
||||
const nextLongest = nextLcs1.length >= nextLcs2.length ? nextLcs1 : nextLcs2;
|
||||
|
||||
memo[`${s1}:${s2}`] = nextLongest;
|
||||
|
||||
return nextLongest;
|
||||
};
|
||||
|
||||
return lcs(string1, string2);
|
||||
}
|
||||
@ -4,13 +4,13 @@ When the order doesn't matter, it is a **Combination**.
|
||||
|
||||
When the order **does** matter it is a **Permutation**.
|
||||
|
||||
**"The combination to the safe is 472"**. We do care about the order. `724` won't work, nor will `247`.
|
||||
**"The combination to the safe is 472"**. We do care about the order. `724` won't work, nor will `247`.
|
||||
It has to be exactly `4-7-2`.
|
||||
|
||||
## Permutations without repetitions
|
||||
|
||||
A permutation, also called an “arrangement number” or “order”, is a rearrangement of
|
||||
the elements of an ordered list `S` into a one-to-one correspondence with `S` itself.
|
||||
A permutation, also called an “arrangement number” or “order”, is a rearrangement of
|
||||
the elements of an ordered list `S` into a one-to-one correspondence with `S` itself.
|
||||
|
||||
Below are the permutations of string `ABC`.
|
||||
|
||||
@ -37,19 +37,17 @@ For example the the lock below: it could be `333`.
|
||||
n * n * n ... (r times) = n^r
|
||||
```
|
||||
|
||||
## Cheat Sheets
|
||||
## Cheatsheet
|
||||
|
||||
Permutations cheat sheet
|
||||

|
||||
|
||||

|
||||

|
||||
|
||||
Combinations cheat sheet
|
||||
| | |
|
||||
| --- | --- |
|
||||
| |  |
|
||||
|
||||

|
||||
|
||||
Permutations/combinations algorithm ideas.
|
||||
|
||||

|
||||
*Made with [okso.app](https://okso.app)*
|
||||
|
||||
## References
|
||||
|
||||
|
||||
BIN
src/algorithms/sets/permutations/images/overview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
{kind=link}
|
After Width: | Height: | Size: 307 KiB |
{kind=link}
|
After Width: | Height: | Size: 301 KiB |
{kind=link}
|
After Width: | Height: | Size: 364 KiB |
@ -1,7 +1,7 @@
|
||||
# Power Set
|
||||
|
||||
Power set of a set `S` is the set of all of the subsets of `S`, including the
|
||||
empty set and `S` itself. Power set of set `S` is denoted as `P(S)`.
|
||||
empty set and `S` itself. Power set of set `S` is denoted as `P(S)`.
|
||||
|
||||
For example for `{x, y, z}`, the subsets
|
||||
are:
|
||||
@ -21,37 +21,37 @@ are:
|
||||
|
||||

|
||||
|
||||
Here is how we may illustrate the elements of the power set of the set `{x, y, z}` ordered with respect to
|
||||
Here is how we may illustrate the elements of the power set of the set `{x, y, z}` ordered with respect to
|
||||
inclusion:
|
||||
|
||||

|
||||
|
||||
**Number of Subsets**
|
||||
|
||||
If `S` is a finite set with `|S| = n` elements, then the number of subsets
|
||||
of `S` is `|P(S)| = 2^n`. This fact, which is the motivation for the
|
||||
If `S` is a finite set with `|S| = n` elements, then the number of subsets
|
||||
of `S` is `|P(S)| = 2^n`. This fact, which is the motivation for the
|
||||
notation `2^S`, may be demonstrated simply as follows:
|
||||
|
||||
> First, order the elements of `S` in any manner. We write any subset of `S` in
|
||||
the format `{γ1, γ2, ..., γn}` where `γi , 1 ≤ i ≤ n`, can take the value
|
||||
> First, order the elements of `S` in any manner. We write any subset of `S` in
|
||||
the format `{γ1, γ2, ..., γn}` where `γi , 1 ≤ i ≤ n`, can take the value
|
||||
of `0` or `1`. If `γi = 1`, the `i`-th element of `S` is in the subset;
|
||||
otherwise, the `i`-th element is not in the subset. Clearly the number of
|
||||
otherwise, the `i`-th element is not in the subset. Clearly the number of
|
||||
distinct subsets that can be constructed this way is `2^n` as `γi ∈ {0, 1}`.
|
||||
|
||||
## Algorithms
|
||||
|
||||
### Bitwise Solution
|
||||
|
||||
Each number in binary representation in a range from `0` to `2^n` does exactly
|
||||
what we need: it shows by its bits (`0` or `1`) whether to include related
|
||||
element from the set or not. For example, for the set `{1, 2, 3}` the binary
|
||||
Each number in binary representation in a range from `0` to `2^n` does exactly
|
||||
what we need: it shows by its bits (`0` or `1`) whether to include related
|
||||
element from the set or not. For example, for the set `{1, 2, 3}` the binary
|
||||
number of `0b010` would mean that we need to include only `2` to the current set.
|
||||
|
||||
| | `abc` | Subset |
|
||||
| :---: | :---: | :-----------: |
|
||||
| `0` | `000` | `{}` |
|
||||
| `1` | `001` | `{c}` |
|
||||
| `2` | `010` | `{b}` |
|
||||
| `2` | `010` | `{b}` |
|
||||
| `3` | `011` | `{c, b}` |
|
||||
| `4` | `100` | `{a}` |
|
||||
| `5` | `101` | `{a, c}` |
|
||||
@ -68,6 +68,44 @@ element.
|
||||
|
||||
> See [btPowerSet.js](./btPowerSet.js) file for backtracking solution.
|
||||
|
||||
### Cascading Solution
|
||||
|
||||
This is, arguably, the simplest solution to generate a Power Set.
|
||||
|
||||
We start with an empty set:
|
||||
|
||||
```text
|
||||
powerSets = [[]]
|
||||
```
|
||||
|
||||
Now, let's say:
|
||||
|
||||
```text
|
||||
originalSet = [1, 2, 3]
|
||||
```
|
||||
|
||||
Let's add the 1st element from the originalSet to all existing sets:
|
||||
|
||||
```text
|
||||
[[]] ← 1 = [[], [1]]
|
||||
```
|
||||
|
||||
Adding the 2nd element to all existing sets:
|
||||
|
||||
```text
|
||||
[[], [1]] ← 2 = [[], [1], [2], [1, 2]]
|
||||
```
|
||||
|
||||
Adding the 3nd element to all existing sets:
|
||||
|
||||
```
|
||||
[[], [1], [2], [1, 2]] ← 3 = [[], [1], [2], [1, 2], [3], [1, 3], [2, 3], [1, 2, 3]]
|
||||
```
|
||||
|
||||
And so on, for the rest of the elements from the `originalSet`. On every iteration the number of sets is doubled, so we'll get `2^n` sets.
|
||||
|
||||
> See [caPowerSet.js](./caPowerSet.js) file for cascading solution.
|
||||
|
||||
## References
|
||||
|
||||
* [Wikipedia](https://en.wikipedia.org/wiki/Power_set)
|
||||
|
||||
28
src/algorithms/sets/power-set/__test__/caPowerSet.test.js
Normal file
@ -0,0 +1,28 @@
|
||||
import caPowerSet from '../caPowerSet';
|
||||
|
||||
describe('caPowerSet', () => {
|
||||
it('should calculate power set of given set using cascading approach', () => {
|
||||
expect(caPowerSet([1])).toEqual([
|
||||
[],
|
||||
[1],
|
||||
]);
|
||||
|
||||
expect(caPowerSet([1, 2])).toEqual([
|
||||
[],
|
||||
[1],
|
||||
[2],
|
||||
[1, 2],
|
||||
]);
|
||||
|
||||
expect(caPowerSet([1, 2, 3])).toEqual([
|
||||
[],
|
||||
[1],
|
||||
[2],
|
||||
[1, 2],
|
||||
[3],
|
||||
[1, 3],
|
||||
[2, 3],
|
||||
[1, 2, 3],
|
||||
]);
|
||||
});
|
||||
});
|
||||
37
src/algorithms/sets/power-set/caPowerSet.js
Normal file
@ -0,0 +1,37 @@
|
||||
/**
|
||||
* Find power-set of a set using CASCADING approach.
|
||||
*
|
||||
* @param {*[]} originalSet
|
||||
* @return {*[][]}
|
||||
*/
|
||||
export default function caPowerSet(originalSet) {
|
||||
// Let's start with an empty set.
|
||||
const sets = [[]];
|
||||
|
||||
/*
|
||||
Now, let's say:
|
||||
originalSet = [1, 2, 3].
|
||||
|
||||
Let's add the first element from the originalSet to all existing sets:
|
||||
[[]] ← 1 = [[], [1]]
|
||||
|
||||
Adding the 2nd element to all existing sets:
|
||||
[[], [1]] ← 2 = [[], [1], [2], [1, 2]]
|
||||
|
||||
Adding the 3nd element to all existing sets:
|
||||
[[], [1], [2], [1, 2]] ← 3 = [[], [1], [2], [1, 2], [3], [1, 3], [2, 3], [1, 2, 3]]
|
||||
|
||||
And so on for the rest of the elements from originalSet.
|
||||
On every iteration the number of sets is doubled, so we'll get 2^n sets.
|
||||
*/
|
||||
for (let numIdx = 0; numIdx < originalSet.length; numIdx += 1) {
|
||||
const existingSetsNum = sets.length;
|
||||
|
||||
for (let setIdx = 0; setIdx < existingSetsNum; setIdx += 1) {
|
||||
const set = [...sets[setIdx], originalSet[numIdx]];
|
||||
sets.push(set);
|
||||
}
|
||||
}
|
||||
|
||||
return sets;
|
||||
}
|
||||
@ -1,16 +1,19 @@
|
||||
# Bubble Sort
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md)
|
||||
|
||||
O bubble sort, ou ordenação por flutuação (literalmente "por bolha"), é um algoritmo de ordenação dos mais simples. A ideia é percorrer o vetor diversas vezes, e a cada passagem fazer flutuar para o topo o maior elemento da sequência. Essa movimentação lembra a forma como as bolhas em um tanque de água procuram seu próprio nível, e disso vem o nome do algoritmo.
|
||||
|
||||

|
||||
|
||||
## Complexity
|
||||
## Complexidade
|
||||
|
||||
| Name | Best | Average | Worst | Memory | Stable | Comments |
|
||||
| Nome | Melhor | Média | Pior | Memória | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
| **Bubble sort** | n | n<sup>2</sup> | n<sup>2</sup> | 1 | Yes | |
|
||||
| **Bubble sort** | n | n<sup>2</sup> | n<sup>2</sup> | 1 | Sim | |
|
||||
|
||||
## References
|
||||
## Referências
|
||||
|
||||
- [Wikipedia](https://pt.wikipedia.org/wiki/Bubble_sort)
|
||||
- [YouTube](https://www.youtube.com/watch?v=6Gv8vg0kcHc&index=27&t=0s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
|
||||
46
src/algorithms/sorting/bucket-sort/BucketSort.js
Normal file
@ -0,0 +1,46 @@
|
||||
import RadixSort from '../radix-sort/RadixSort';
|
||||
|
||||
/**
|
||||
* Bucket Sort
|
||||
*
|
||||
* @param {number[]} arr
|
||||
* @param {number} bucketsNum
|
||||
* @return {number[]}
|
||||
*/
|
||||
export default function BucketSort(arr, bucketsNum = 1) {
|
||||
const buckets = new Array(bucketsNum).fill(null).map(() => []);
|
||||
|
||||
const minValue = Math.min(...arr);
|
||||
const maxValue = Math.max(...arr);
|
||||
|
||||
const bucketSize = Math.ceil(Math.max(1, (maxValue - minValue) / bucketsNum));
|
||||
|
||||
// Place elements into buckets.
|
||||
for (let i = 0; i < arr.length; i += 1) {
|
||||
const currValue = arr[i];
|
||||
const bucketIndex = Math.floor((currValue - minValue) / bucketSize);
|
||||
|
||||
// Edge case for max value.
|
||||
if (bucketIndex === bucketsNum) {
|
||||
buckets[bucketsNum - 1].push(currValue);
|
||||
} else {
|
||||
buckets[bucketIndex].push(currValue);
|
||||
}
|
||||
}
|
||||
|
||||
// Sort individual buckets.
|
||||
for (let i = 0; i < buckets.length; i += 1) {
|
||||
// Let's use the Radix Sorter here. This may give us
|
||||
// the average O(n + k) time complexity to sort one bucket
|
||||
// (where k is a number of digits in the longest number).
|
||||
buckets[i] = new RadixSort().sort(buckets[i]);
|
||||
}
|
||||
|
||||
// Merge sorted buckets into final output.
|
||||
const sortedArr = [];
|
||||
for (let i = 0; i < buckets.length; i += 1) {
|
||||
sortedArr.push(...buckets[i]);
|
||||
}
|
||||
|
||||
return sortedArr;
|
||||
}
|
||||
35
src/algorithms/sorting/bucket-sort/README.md
Normal file
@ -0,0 +1,35 @@
|
||||
# Bucket Sort
|
||||
|
||||
**Bucket sort**, or **bin sort**, is a sorting algorithm that works by distributing the elements of an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm.
|
||||
|
||||
## Algorithm
|
||||
|
||||
Bucket sort works as follows:
|
||||
|
||||
1. Set up an array of initially empty `buckets`.
|
||||
2. **Scatter:** Go over the original array, putting each object in its `bucket`.
|
||||
3. Sort each non-empty `bucket`.
|
||||
4. **Gather:** Visit the `buckets` in order and put all elements back into the original array.
|
||||
|
||||
Elements are distributed among bins:
|
||||
|
||||

|
||||
|
||||
Then, elements are sorted within each bin:
|
||||
|
||||

|
||||
|
||||
|
||||
## Complexity
|
||||
|
||||
The computational complexity depends on the algorithm used to sort each bucket, the number of buckets to use, and whether the input is uniformly distributed.
|
||||
|
||||
The **worst-case** time complexity of bucket sort is
|
||||
`O(n^2)` if the sorting algorithm used on the bucket is *insertion sort*, which is the most common use case since the expectation is that buckets will not have too many elements relative to the entire list. In the worst case, all elements are placed in one bucket, causing the running time to reduce to the worst-case complexity of insertion sort (all elements are in reverse order). If the worst-case running time of the intermediate sort used is `O(n * log(n))`, then the worst-case running time of bucket sort will also be
|
||||
`O(n * log(n))`.
|
||||
|
||||
On **average**, when the distribution of elements across buckets is reasonably uniform, it can be shown that bucket sort runs on average `O(n + k)` for `k` buckets.
|
||||
|
||||
## References
|
||||
|
||||
- [Bucket Sort on Wikipedia](https://en.wikipedia.org/wiki/Bucket_sort)
|
||||
@ -0,0 +1,33 @@
|
||||
import BucketSort from '../BucketSort';
|
||||
import {
|
||||
equalArr,
|
||||
notSortedArr,
|
||||
reverseArr,
|
||||
sortedArr,
|
||||
} from '../../SortTester';
|
||||
|
||||
describe('BucketSort', () => {
|
||||
it('should sort the array of numbers with different buckets amounts', () => {
|
||||
expect(BucketSort(notSortedArr, 4)).toEqual(sortedArr);
|
||||
expect(BucketSort(equalArr, 4)).toEqual(equalArr);
|
||||
expect(BucketSort(reverseArr, 4)).toEqual(sortedArr);
|
||||
expect(BucketSort(sortedArr, 4)).toEqual(sortedArr);
|
||||
|
||||
expect(BucketSort(notSortedArr, 10)).toEqual(sortedArr);
|
||||
expect(BucketSort(equalArr, 10)).toEqual(equalArr);
|
||||
expect(BucketSort(reverseArr, 10)).toEqual(sortedArr);
|
||||
expect(BucketSort(sortedArr, 10)).toEqual(sortedArr);
|
||||
|
||||
expect(BucketSort(notSortedArr, 50)).toEqual(sortedArr);
|
||||
expect(BucketSort(equalArr, 50)).toEqual(equalArr);
|
||||
expect(BucketSort(reverseArr, 50)).toEqual(sortedArr);
|
||||
expect(BucketSort(sortedArr, 50)).toEqual(sortedArr);
|
||||
});
|
||||
|
||||
it('should sort the array of numbers with the default buckets of 1', () => {
|
||||
expect(BucketSort(notSortedArr)).toEqual(sortedArr);
|
||||
expect(BucketSort(equalArr)).toEqual(equalArr);
|
||||
expect(BucketSort(reverseArr)).toEqual(sortedArr);
|
||||
expect(BucketSort(sortedArr)).toEqual(sortedArr);
|
||||
});
|
||||
});
|
||||
BIN
src/algorithms/sorting/bucket-sort/images/bucket_sort_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
BIN
src/algorithms/sorting/bucket-sort/images/bucket_sort_2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
@ -1,5 +1,8 @@
|
||||
# Counting Sort
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
In computer science, **counting sort** is an algorithm for sorting
|
||||
a collection of objects according to keys that are small integers;
|
||||
that is, it is an integer sorting algorithm. It operates by
|
||||
|
||||
70
src/algorithms/sorting/counting-sort/README.pt-br.md
Normal file
@ -0,0 +1,70 @@
|
||||
# Counting Sort
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md)
|
||||
|
||||
Em ciência da computação, **counting sort** é um algoritmo para ordenar
|
||||
uma coleção de objetos de acordo com chaves que são pequenos inteiros;
|
||||
ou seja, é um algoritmo de ordenação de inteiros. Ele opera por
|
||||
contando o número de objetos que têm cada valor de chave distinto,
|
||||
e usando aritmética nessas contagens para determinar as posições
|
||||
de cada valor de chave na sequência de saída. Seu tempo de execução é
|
||||
linear no número de itens e a diferença entre o
|
||||
valores de chave máximo e mínimo, portanto, é adequado apenas para
|
||||
uso em situações em que a variação de tonalidades não é significativamente
|
||||
maior que o número de itens. No entanto, muitas vezes é usado como
|
||||
sub-rotina em outro algoritmo de ordenação, radix sort, que pode
|
||||
lidar com chaves maiores de forma mais eficiente.
|
||||
|
||||
Como a classificação por contagem usa valores-chave como índices em um vetor,
|
||||
não é uma ordenação por comparação, e o limite inferior `Ω(n log n)` para
|
||||
a ordenação por comparação não se aplica a ele. A classificação por bucket pode ser usada
|
||||
para muitas das mesmas tarefas que a ordenação por contagem, com um tempo semelhante
|
||||
análise; no entanto, em comparação com a classificação por contagem, a classificação por bucket requer
|
||||
listas vinculadas, arrays dinâmicos ou uma grande quantidade de pré-alocados
|
||||
memória para armazenar os conjuntos de itens dentro de cada bucket, enquanto
|
||||
A classificação por contagem armazena um único número (a contagem de itens)
|
||||
por balde.
|
||||
|
||||
A classificação por contagem funciona melhor quando o intervalo de números para cada
|
||||
elemento do vetor é muito pequeno.
|
||||
|
||||
## Algoritmo
|
||||
|
||||
**Passo I**
|
||||
|
||||
Na primeira etapa, calculamos a contagem de todos os elementos do
|
||||
vetor de entrada 'A'. Em seguida, armazene o resultado no vetor de contagem `C`.
|
||||
A maneira como contamos é descrita abaixo.
|
||||
|
||||
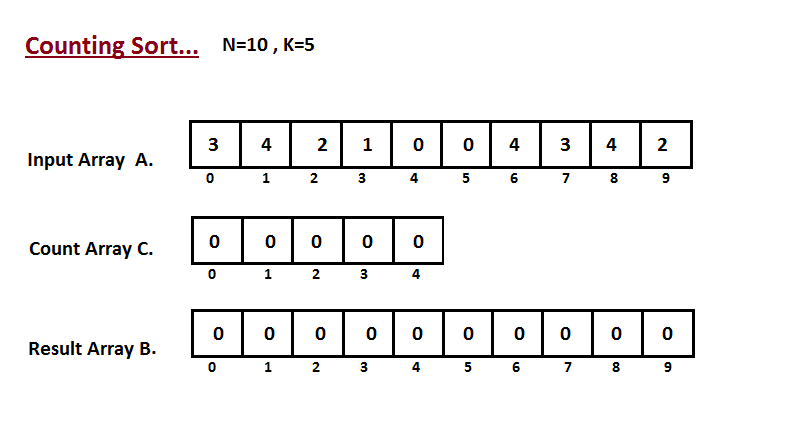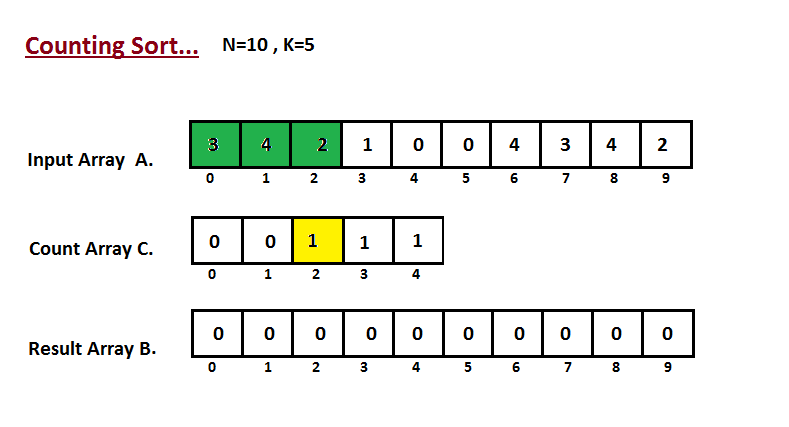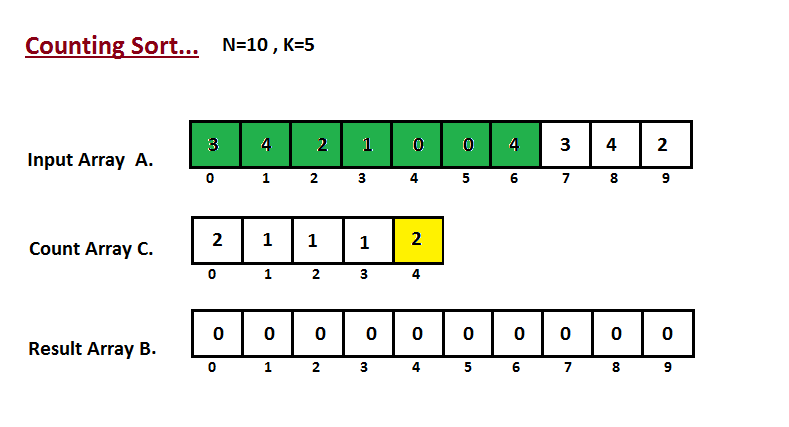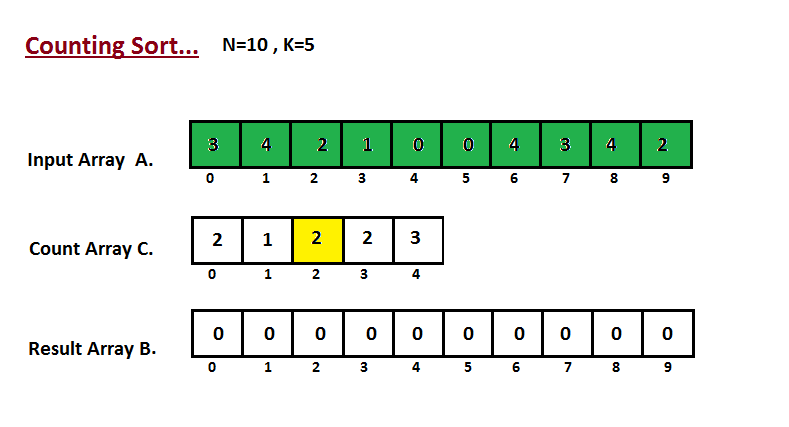
|
||||
|
||||
**Passo II**
|
||||
|
||||
Na segunda etapa, calculamos quantos elementos existem na entrada
|
||||
do vetor `A` que são menores ou iguais para o índice fornecido.
|
||||
`Ci` = números de elementos menores ou iguais a `i` no vetor de entrada.
|
||||
|
||||
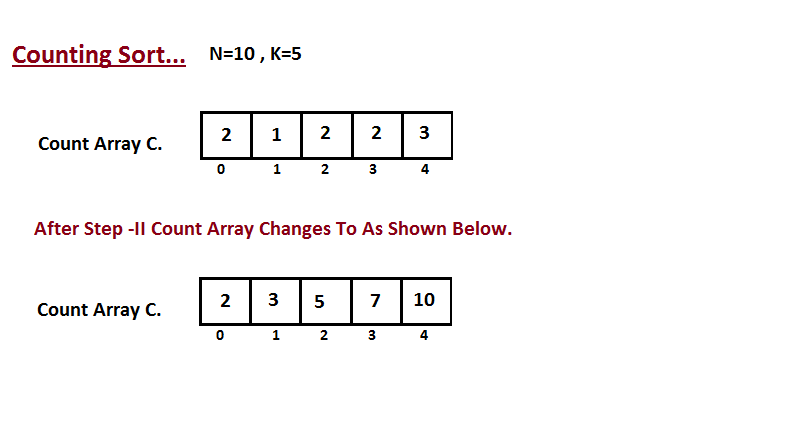
|
||||
|
||||
**Passo III**
|
||||
|
||||
Nesta etapa, colocamos o elemento `A` do vetor de entrada em classificado
|
||||
posição usando a ajuda do vetor de contagem construída `C`, ou seja, o que
|
||||
construímos no passo dois. Usamos o vetor de resultados `B` para armazenar
|
||||
os elementos ordenados. Aqui nós lidamos com o índice de `B` começando de
|
||||
zero.
|
||||
|
||||
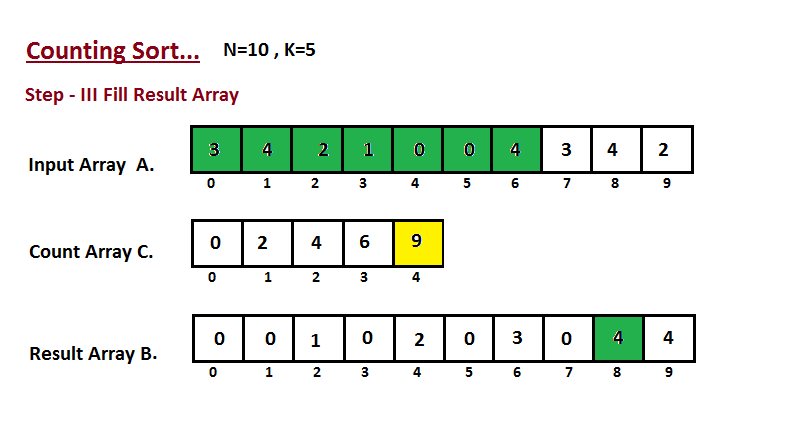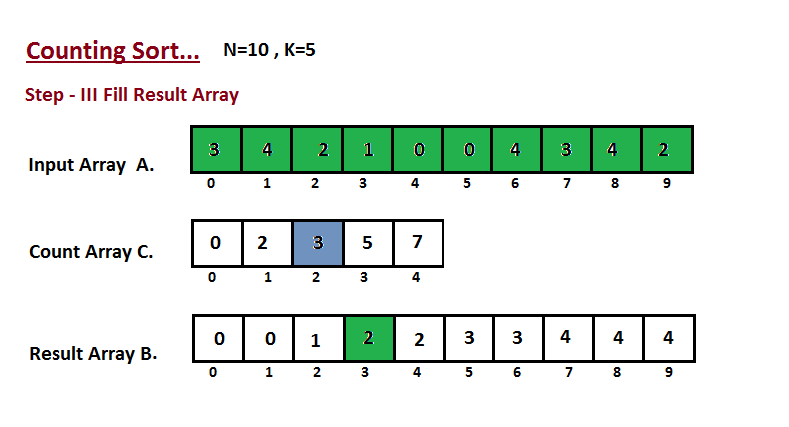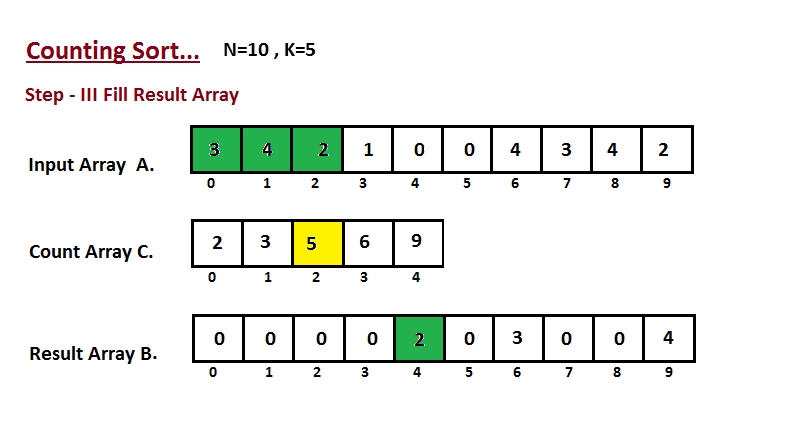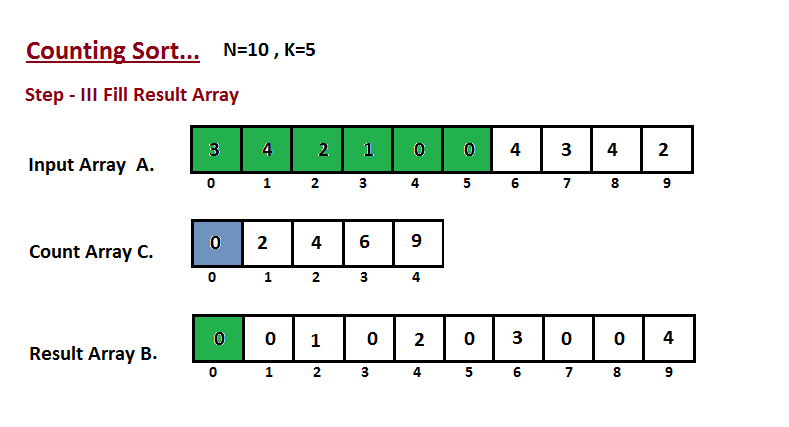
|
||||
|
||||
## Complexidade
|
||||
|
||||
| Nome | Melhor | Média | Pior | Memória | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
| **Counting sort** | n + r | n + r | n + r | n + r | Sim | r - Maior número no vetor |
|
||||
|
||||
## Referências
|
||||
|
||||
- [Wikipedia](https://en.wikipedia.org/wiki/Counting_sort)
|
||||
- [YouTube](https://www.youtube.com/watch?v=OKd534EWcdk&index=61&t=0s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
- [EfficientAlgorithms](https://efficientalgorithms.blogspot.com/2016/09/lenear-sorting-counting-sort.html)
|
||||
@ -1,5 +1,8 @@
|
||||
# Heap Sort
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
Heapsort is a comparison-based sorting algorithm.
|
||||
Heapsort can be thought of as an improved selection
|
||||
sort: like that algorithm, it divides its input into
|
||||
|
||||
20
src/algorithms/sorting/heap-sort/README.pt-BR.md
Normal file
@ -0,0 +1,20 @@
|
||||
# Heap Sort
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md)
|
||||
|
||||
Heapsort é um algoritmo de ordenação baseado em comparação. O Heapsort pode ser pensado como uma seleção aprimorada sort: como esse algoritmo, ele divide sua entrada em uma região classificada e uma região não classificada, e iterativamente encolhe a região não classificada extraindo o maior elemento e movendo-o para a região classificada. A melhoria consiste no uso de uma estrutura de dados heap em vez de uma busca em tempo linear para encontrar o máximo.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Complexidade
|
||||
|
||||
| Nome | Melhor | Média | Pior | Memória | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
| **Heap sort** | n log(n) | n log(n) | n log(n) | 1 | Não | |
|
||||
|
||||
## Referências
|
||||
|
||||
[Wikipedia](https://en.wikipedia.org/wiki/Heapsort)
|
||||
@ -1,5 +1,8 @@
|
||||
# Insertion Sort
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
Insertion sort is a simple sorting algorithm that builds
|
||||
the final sorted array (or list) one item at a time.
|
||||
It is much less efficient on large lists than more
|
||||
|
||||
22
src/algorithms/sorting/insertion-sort/README.pt-BR.md
Normal file
@ -0,0 +1,22 @@
|
||||
# Insertion Sort
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md)
|
||||
|
||||
A ordenação por inserção é um algoritmo de ordenação simples que criaa matriz classificada final (ou lista) um item de cada vez.
|
||||
É muito menos eficiente em grandes listas do que mais algoritmos avançados, como quicksort, heapsort ou merge
|
||||
ordenar.
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
## Complexidade
|
||||
|
||||
| Nome | Melhor | Média | Pior | Memória | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
| **Insertion sort** | n | n<sup>2</sup> | n<sup>2</sup> | 1 | Sim | |
|
||||
|
||||
## Referências
|
||||
|
||||
[Wikipedia](https://en.wikipedia.org/wiki/Insertion_sort)
|
||||
@ -1,7 +1,8 @@
|
||||
# Merge Sort
|
||||
|
||||
_Read this in other languages:_
|
||||
[_한국어_](README.ko-KR.md)
|
||||
[_한국어_](README.ko-KR.md),
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
In computer science, merge sort (also commonly spelled
|
||||
mergesort) is an efficient, general-purpose,
|
||||
|
||||
38
src/algorithms/sorting/merge-sort/README.pt-BR.md
Normal file
@ -0,0 +1,38 @@
|
||||
# Merge Sort
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_한국어_](README.ko-KR.md),
|
||||
[_English_](README.md)
|
||||
|
||||
Em ciência da computação, merge sort (também comumente escrito
|
||||
mergesort) é uma ferramenta eficiente, de propósito geral,
|
||||
algoritmo de ordenação baseado em comparação. A maioria das implementações
|
||||
produzir uma classificação estável, o que significa que a implementação
|
||||
preserva a ordem de entrada de elementos iguais na ordenação
|
||||
resultado. Mergesort é um algoritmo de divisão e conquista que
|
||||
foi inventado por John von Neumann em 1945.
|
||||
|
||||
Um exemplo de classificação de mesclagem. Primeiro divida a lista em
|
||||
a menor unidade (1 elemento), então compare cada
|
||||
elemento com a lista adjacente para classificar e mesclar o
|
||||
duas listas adjacentes. Finalmente todos os elementos são ordenados
|
||||
e mesclado.
|
||||
|
||||

|
||||
|
||||
Um algoritmo de classificação de mesclagem recursivo usado para classificar uma matriz de 7
|
||||
valores inteiros. Estes são os passos que um ser humano daria para
|
||||
emular merge sort (top-down).
|
||||
|
||||

|
||||
|
||||
## Complexidade
|
||||
|
||||
| Nome | Melhor | Média | Pior | Memória | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
| **Merge sort** | n log(n) | n log(n) | n log(n) | n | Sim | |
|
||||
|
||||
## Referências
|
||||
|
||||
- [Wikipedia](https://en.wikipedia.org/wiki/Merge_sort)
|
||||
- [YouTube](https://www.youtube.com/watch?v=KF2j-9iSf4Q&index=27&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
@ -4,7 +4,7 @@ export default class QuickSortInPlace extends Sort {
|
||||
/** Sorting in place avoids unnecessary use of additional memory, but modifies input array.
|
||||
*
|
||||
* This process is difficult to describe, but much clearer with a visualization:
|
||||
* @see: http://www.algomation.com/algorithm/quick-sort-visualization
|
||||
* @see: https://www.hackerearth.com/practice/algorithms/sorting/quick-sort/visualize/
|
||||
*
|
||||
* @param {*[]} originalArray - Not sorted array.
|
||||
* @param {number} inputLowIndex
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
# Quicksort
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Português_](README.pt-BR.md),
|
||||
[_简体中文_](README.zh-CN.md)
|
||||
[_简体中文_](README.zh-CN.md),
|
||||
[_Português_](README.pt-BR.md)
|
||||
|
||||
Quicksort is a divide and conquer algorithm.
|
||||
Quicksort first divides a large array into two smaller
|
||||
|
||||
@ -1,15 +1,19 @@
|
||||
# Quicksort
|
||||
|
||||
Quicksort é um algoritmo de dividir para conquistar é um algoritmo de divisão e conquista.
|
||||
_Leia isso em outros idiomas:_
|
||||
[_简体中文_](README.zh-CN.md),
|
||||
[_English_](README.md)
|
||||
|
||||
Quicksort é um algoritmo de dividir para conquistar.
|
||||
Quicksort primeiro divide uma grande matriz em duas menores
|
||||
submatrizes: os elementos baixos e os elementos altos.
|
||||
O Quicksort pode então classificar recursivamente as submatrizes
|
||||
O Quicksort pode então classificar recursivamente as submatrizes.
|
||||
|
||||
As etapas são:
|
||||
|
||||
1. Escolha um elemento, denominado pivô, na matriz.
|
||||
2. Particionamento: reordene a matriz para que todos os elementos com
|
||||
valores menores que o pivô vêm antes do pivô, enquanto todos
|
||||
valores menores que o pivô estejam antes do pivô, enquanto todos
|
||||
elementos com valores maiores do que o pivô vêm depois dele
|
||||
(valores iguais podem ser usados em qualquer direção). Após este particionamento,
|
||||
o pivô está em sua posição final. Isso é chamado de
|
||||
@ -27,7 +31,7 @@ As linhas horizontais são valores dinâmicos.
|
||||
|
||||
| Nome | Melhor | Média | Pior | Memória | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
| **Quick sort** | n log(n) | n log(n) | n<sup>2</sup> | log(n) | No | Quicksort geralmente é feito no local com espaço de pilha O(log(n)) |
|
||||
| **Quick sort** | n log(n) | n log(n) | n<sup>2</sup> | log(n) | Não | Quicksort geralmente é feito no local com espaço de pilha O(log(n)) |
|
||||
|
||||
## Referências
|
||||
|
||||
|
||||
@ -1,36 +1,39 @@
|
||||
# Radix Sort
|
||||
|
||||
In computer science, **radix sort** is a non-comparative integer sorting
|
||||
algorithm that sorts data with integer keys by grouping keys by the individual
|
||||
_Read this in other languages:_
|
||||
[_Português_](README.pt-BR.md),
|
||||
|
||||
In computer science, **radix sort** is a non-comparative integer sorting
|
||||
algorithm that sorts data with integer keys by grouping keys by the individual
|
||||
digits which share the same significant position and value. A positional notation
|
||||
is required, but because integers can represent strings of characters
|
||||
(e.g., names or dates) and specially formatted floating point numbers, radix
|
||||
is required, but because integers can represent strings of characters
|
||||
(e.g., names or dates) and specially formatted floating point numbers, radix
|
||||
sort is not limited to integers.
|
||||
|
||||
*Where does the name come from?*
|
||||
|
||||
In mathematical numeral systems, the *radix* or base is the number of unique digits,
|
||||
including the digit zero, used to represent numbers in a positional numeral system.
|
||||
For example, a binary system (using numbers 0 and 1) has a radix of 2 and a decimal
|
||||
including the digit zero, used to represent numbers in a positional numeral system.
|
||||
For example, a binary system (using numbers 0 and 1) has a radix of 2 and a decimal
|
||||
system (using numbers 0 to 9) has a radix of 10.
|
||||
|
||||
## Efficiency
|
||||
|
||||
The topic of the efficiency of radix sort compared to other sorting algorithms is
|
||||
somewhat tricky and subject to quite a lot of misunderstandings. Whether radix
|
||||
sort is equally efficient, less efficient or more efficient than the best
|
||||
comparison-based algorithms depends on the details of the assumptions made.
|
||||
Radix sort complexity is `O(wn)` for `n` keys which are integers of word size `w`.
|
||||
Sometimes `w` is presented as a constant, which would make radix sort better
|
||||
(for sufficiently large `n`) than the best comparison-based sorting algorithms,
|
||||
which all perform `O(n log n)` comparisons to sort `n` keys. However, in
|
||||
general `w` cannot be considered a constant: if all `n` keys are distinct,
|
||||
then `w` has to be at least `log n` for a random-access machine to be able to
|
||||
store them in memory, which gives at best a time complexity `O(n log n)`. That
|
||||
would seem to make radix sort at most equally efficient as the best
|
||||
The topic of the efficiency of radix sort compared to other sorting algorithms is
|
||||
somewhat tricky and subject to quite a lot of misunderstandings. Whether radix
|
||||
sort is equally efficient, less efficient or more efficient than the best
|
||||
comparison-based algorithms depends on the details of the assumptions made.
|
||||
Radix sort complexity is `O(wn)` for `n` keys which are integers of word size `w`.
|
||||
Sometimes `w` is presented as a constant, which would make radix sort better
|
||||
(for sufficiently large `n`) than the best comparison-based sorting algorithms,
|
||||
which all perform `O(n log n)` comparisons to sort `n` keys. However, in
|
||||
general `w` cannot be considered a constant: if all `n` keys are distinct,
|
||||
then `w` has to be at least `log n` for a random-access machine to be able to
|
||||
store them in memory, which gives at best a time complexity `O(n log n)`. That
|
||||
would seem to make radix sort at most equally efficient as the best
|
||||
comparison-based sorts (and worse if keys are much longer than `log n`).
|
||||
|
||||

|
||||

|
||||
|
||||
## Complexity
|
||||
|
||||
|
||||
48
src/algorithms/sorting/radix-sort/README.pt-BR.md
Normal file
@ -0,0 +1,48 @@
|
||||
# Radix Sort
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md)
|
||||
|
||||
Em ciência da computação, **radix sort** é uma classificação inteira não comparativa
|
||||
algoritmo que classifica os dados com chaves inteiras agrupando as chaves pelo indivíduo
|
||||
dígitos que compartilham a mesma posição e valor significativos. Uma notação posicional
|
||||
é necessário, mas porque os números inteiros podem representar cadeias de caracteres
|
||||
(por exemplo, nomes ou datas) e números de ponto flutuante especialmente formatados, base
|
||||
sort não está limitado a inteiros.
|
||||
|
||||
*De onde vem o nome?*
|
||||
|
||||
Em sistemas numéricos matemáticos, a *radix* ou base é o número de dígitos únicos,
|
||||
incluindo o dígito zero, usado para representar números em um sistema de numeração posicional.
|
||||
Por exemplo, um sistema binário (usando números 0 e 1) tem uma raiz de 2 e um decimal
|
||||
sistema (usando números de 0 a 9) tem uma raiz de 10.
|
||||
|
||||
## Eficiência
|
||||
|
||||
O tópico da eficiência do radix sort comparado a outros algoritmos de ordenação é
|
||||
um pouco complicado e sujeito a muitos mal-entendidos. Se raiz
|
||||
sort é igualmente eficiente, menos eficiente ou mais eficiente do que o melhor
|
||||
algoritmos baseados em comparação depende dos detalhes das suposições feitas.
|
||||
A complexidade de classificação de raiz é `O(wn)` para chaves `n` que são inteiros de tamanho de palavra `w`.
|
||||
Às vezes, `w` é apresentado como uma constante, o que tornaria a classificação radix melhor
|
||||
(para `n` suficientemente grande) do que os melhores algoritmos de ordenação baseados em comparação,
|
||||
que todos realizam comparações `O(n log n)` para classificar chaves `n`. No entanto, em
|
||||
geral `w` não pode ser considerado uma constante: se todas as chaves `n` forem distintas,
|
||||
então `w` tem que ser pelo menos `log n` para que uma máquina de acesso aleatório seja capaz de
|
||||
armazená-los na memória, o que dá na melhor das hipóteses uma complexidade de tempo `O(n log n)`. Este
|
||||
parece tornar a ordenação radix no máximo tão eficiente quanto a melhor
|
||||
ordenações baseadas em comparação (e pior se as chaves forem muito mais longas que `log n`).
|
||||
|
||||

|
||||
|
||||
## Complexidade
|
||||
|
||||
| Nome | Melhor | Média | Pior | Memória | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
| **Radix sort** | n * k | n * k | n * k | n + k | Sim | k - comprimento da chave mais longa |
|
||||
|
||||
## Referências
|
||||
|
||||
- [Wikipedia](https://en.wikipedia.org/wiki/Radix_sort)
|
||||
- [YouTube](https://www.youtube.com/watch?v=XiuSW_mEn7g&index=62&t=0s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
- [ResearchGate](https://www.researchgate.net/figure/Simplistic-illustration-of-the-steps-performed-in-a-radix-sort-In-this-example-the_fig1_291086231)
|
||||
BIN
src/algorithms/sorting/radix-sort/images/radix-sort.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
@ -1,7 +1,7 @@
|
||||
# Selection Sort
|
||||
|
||||
_Read this in other languages:_
|
||||
[Português brasileiro](README.pt-BR.md).
|
||||
[_Português_](README.pt-BR.md).
|
||||
|
||||
Selection sort is a sorting algorithm, specifically an
|
||||
in-place comparison sort. It has O(n2) time complexity,
|
||||
|
||||
@ -1,7 +1,7 @@
|
||||
# Selection Sort
|
||||
|
||||
_Leia isso em outras línguas:_
|
||||
[english](README.md).
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md).
|
||||
|
||||
Selection Sort é um algoritmo de ordenação, mais especificamente um algoritmo de ordenação por comparação in-place (requer uma quantidade constante de espaço de memória adicional). Tem complexidade O(n²), tornando-o ineficiente em listas grandes e, geralmente, tem desempenho inferior ao similar Insertion Sort. O Selection Sort é conhecido por sua simplicidade e tem vantagens de desempenho sobre algoritmos mais complexos em certas situações, particularmente quando a memória auxiliar é limitada.
|
||||
|
||||
|
||||
@ -1,5 +1,8 @@
|
||||
# Shellsort
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Português_](README.pt-BR.md).
|
||||
|
||||
Shellsort, also known as Shell sort or Shell's method,
|
||||
is an in-place comparison sort. It can be seen as either a
|
||||
generalization of sorting by exchange (bubble sort) or sorting
|
||||
|
||||
60
src/algorithms/sorting/shell-sort/README.pt-BR.md
Normal file
@ -0,0 +1,60 @@
|
||||
# Shellsort
|
||||
|
||||
_Leia isso em outros idiomas:_
|
||||
[_English_](README.md).
|
||||
|
||||
Shellsort, também conhecido como Shell sort ou método de Shell,
|
||||
é uma classificação de comparação in-loco. Pode ser visto tanto como um
|
||||
generalização da ordenação por troca (bubble sort) ou ordenação
|
||||
por inserção (ordenação por inserção). O método começa classificando
|
||||
pares de elementos distantes um do outro, então progressivamente
|
||||
reduzindo a distância entre os elementos a serem comparados. Iniciando
|
||||
com elementos distantes, pode mover alguns fora do lugar
|
||||
elementos em posição mais rápido do que um simples vizinho mais próximo
|
||||
intercâmbio
|
||||
|
||||

|
||||
|
||||
## Como o Shellsort funciona?
|
||||
|
||||
Para nosso exemplo e facilidade de compreensão, tomamos o intervalo
|
||||
de `4`. Faça uma sub-lista virtual de todos os valores localizados no
|
||||
intervalo de 4 posições. Aqui esses valores são
|
||||
`{35, 14}`, `{33, 19}`, `{42, 27}` e `{10, 44}`
|
||||
|
||||

|
||||
|
||||
Comparamos valores em cada sublista e os trocamos (se necessário)
|
||||
na matriz original. Após esta etapa, o novo array deve
|
||||
parece com isso
|
||||
|
||||

|
||||
|
||||
Então, pegamos o intervalo de 2 e essa lacuna gera duas sub-listas
|
||||
- `{14, 27, 35, 42}`, `{19, 10, 33, 44}`
|
||||
|
||||
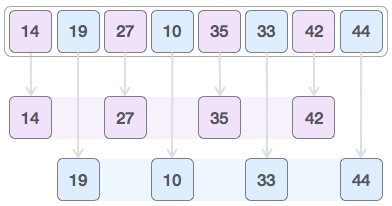
|
||||
|
||||
Comparamos e trocamos os valores, se necessário, no array original.
|
||||
Após esta etapa, a matriz deve ficar assim
|
||||
|
||||

|
||||
|
||||
> OBS: Na imagem abaixo há um erro de digitação e a matriz de resultados deve ser `[14, 10, 27, 19, 35, 33, 42, 44]`.
|
||||
|
||||
Finalmente, ordenamos o resto do array usando o intervalo de valor 1.
|
||||
A classificação de shell usa a classificação por inserção para classificar a matriz.
|
||||
|
||||
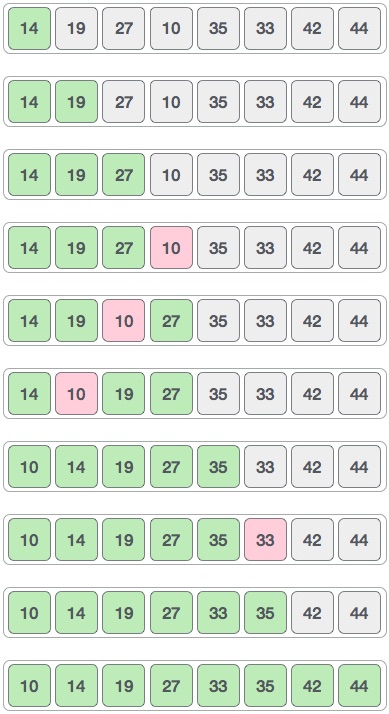
|
||||
|
||||
## Complexidade
|
||||
|
||||
| Nome | Melhor | Média | Pior | Memória | Estável | Comentários |
|
||||
| --------------------- | :-------------: | :-----------------: | :-----------------: | :-------: | :-------: | :-------- |
|
||||
| **Shell sort** | n log(n) | depends on gap sequence | n (log(n))<sup>2</sup> | 1 | Não | |
|
||||
|
||||
## Referências
|
||||
|
||||
- [Tutorials Point](https://www.tutorialspoint.com/data_structures_algorithms/shell_sort_algorithm.htm)
|
||||
- [Wikipedia](https://en.wikipedia.org/wiki/Shellsort)
|
||||
- [YouTube by Rob Edwards](https://www.youtube.com/watch?v=ddeLSDsYVp8&index=79&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||
@ -7,6 +7,8 @@ describe('longestCommonSubstring', () => {
|
||||
expect(longestCommonSubstring('', 'ABC')).toBe('');
|
||||
expect(longestCommonSubstring('ABABC', 'BABCA')).toBe('BABC');
|
||||
expect(longestCommonSubstring('BABCA', 'ABCBA')).toBe('ABC');
|
||||
expect(longestCommonSubstring('sea', 'eat')).toBe('ea');
|
||||
expect(longestCommonSubstring('algorithms', 'rithm')).toBe('rithm');
|
||||
expect(longestCommonSubstring(
|
||||
'Algorithms and data structures implemented in JavaScript',
|
||||
'Here you may find Algorithms and data structures that are implemented in JavaScript',
|
||||
|
||||
@ -1,4 +1,6 @@
|
||||
/**
|
||||
* Longest Common Substring (LCS) (Dynamic Programming Approach).
|
||||
*
|
||||
* @param {string} string1
|
||||
* @param {string} string2
|
||||
* @return {string}
|
||||
|
||||
@ -46,7 +46,7 @@ Let's say we have an array of prices `[7, 6, 4, 3, 1]` and we're on the _1st_ da
|
||||
1. _Option 1: Keep the money_ → profit would equal to the profit from buying/selling the rest of the stocks → `keepProfit = profit([6, 4, 3, 1])`.
|
||||
2. _Option 2: Buy/sell at current price_ → profit in this case would equal to the profit from buying/selling the rest of the stocks plus (or minus, depending on whether we're selling or buying) the current stock price → `buySellProfit = -7 + profit([6, 4, 3, 1])`.
|
||||
|
||||
The overall profit would be equal to → `overalProfit = Max(keepProfit, buySellProfit)`.
|
||||
The overall profit would be equal to → `overallProfit = Max(keepProfit, buySellProfit)`.
|
||||
|
||||
As you can see the `profit([6, 4, 3, 1])` task is being solved in the same recursive manner.
|
||||
|
||||
|
||||
@ -59,7 +59,7 @@ and return false.
|
||||
queen here leads to a solution.
|
||||
b) If placing queen in [row, column] leads to a solution then return
|
||||
true.
|
||||
c) If placing queen doesn't lead to a solution then umark this [row,
|
||||
c) If placing queen doesn't lead to a solution then unmark this [row,
|
||||
column] (Backtrack) and go to step (a) to try other rows.
|
||||
3) If all rows have been tried and nothing worked, return false to trigger
|
||||
backtracking.
|
||||
|
||||
@ -2,38 +2,39 @@
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Русский_](README.ru-RU.md),
|
||||
[_Português_](README.pt-BR.md)
|
||||
[_Português_](README.pt-BR.md),
|
||||
[_Українська_](README.uk-UA.md)
|
||||
|
||||
A **bloom filter** is a space-efficient probabilistic
|
||||
data structure designed to test whether an element
|
||||
is present in a set. It is designed to be blazingly
|
||||
A **bloom filter** is a space-efficient probabilistic
|
||||
data structure designed to test whether an element
|
||||
is present in a set. It is designed to be blazingly
|
||||
fast and use minimal memory at the cost of potential
|
||||
false positives. False positive matches are possible,
|
||||
but false negatives are not – in other words, a query
|
||||
returns either "possibly in set" or "definitely not in set".
|
||||
|
||||
Bloom proposed the technique for applications where the
|
||||
Bloom proposed the technique for applications where the
|
||||
amount of source data would require an impractically large
|
||||
amount of memory if "conventional" error-free hashing
|
||||
amount of memory if "conventional" error-free hashing
|
||||
techniques were applied.
|
||||
|
||||
## Algorithm description
|
||||
|
||||
An empty Bloom filter is a bit array of `m` bits, all
|
||||
An empty Bloom filter is a bit array of `m` bits, all
|
||||
set to `0`. There must also be `k` different hash functions
|
||||
defined, each of which maps or hashes some set element to
|
||||
one of the `m` array positions, generating a uniform random
|
||||
distribution. Typically, `k` is a constant, much smaller
|
||||
than `m`, which is proportional to the number of elements
|
||||
to be added; the precise choice of `k` and the constant of
|
||||
proportionality of `m` are determined by the intended
|
||||
defined, each of which maps or hashes some set element to
|
||||
one of the `m` array positions, generating a uniform random
|
||||
distribution. Typically, `k` is a constant, much smaller
|
||||
than `m`, which is proportional to the number of elements
|
||||
to be added; the precise choice of `k` and the constant of
|
||||
proportionality of `m` are determined by the intended
|
||||
false positive rate of the filter.
|
||||
|
||||
Here is an example of a Bloom filter, representing the
|
||||
set `{x, y, z}`. The colored arrows show the positions
|
||||
in the bit array that each set element is mapped to. The
|
||||
element `w` is not in the set `{x, y, z}`, because it
|
||||
hashes to one bit-array position containing `0`. For
|
||||
Here is an example of a Bloom filter, representing the
|
||||
set `{x, y, z}`. The colored arrows show the positions
|
||||
in the bit array that each set element is mapped to. The
|
||||
element `w` is not in the set `{x, y, z}`, because it
|
||||
hashes to one bit-array position containing `0`. For
|
||||
this figure, `m = 18` and `k = 3`.
|
||||
|
||||

|
||||
@ -92,7 +93,7 @@ three factors: the size of the bloom filter, the
|
||||
number of hash functions we use, and the number
|
||||
of items that have been inserted into the filter.
|
||||
|
||||
The formula to calculate probablity of a false positive is:
|
||||
The formula to calculate probability of a false positive is:
|
||||
|
||||
( 1 - e <sup>-kn/m</sup> ) <sup>k</sup>
|
||||
|
||||
|
||||
@ -3,7 +3,7 @@
|
||||
O **bloom filter** é uma estrutura de dados probabilística
|
||||
espaço-eficiente designada para testar se um elemento está
|
||||
ou não presente em um conjunto de dados. Foi projetado para ser
|
||||
incrivelmente rápido e utilizar o mínimo de memória ao
|
||||
incrivelmente rápida e utilizar o mínimo de memória ao
|
||||
potencial custo de um falso-positivo. Correspondências
|
||||
_falsas positivas_ são possíveis, contudo _falsos negativos_
|
||||
não são - em outras palavras, a consulta retorna
|
||||
@ -12,7 +12,7 @@ não são - em outras palavras, a consulta retorna
|
||||
Bloom propôs a técnica para aplicações onde a quantidade
|
||||
de entrada de dados exigiria uma alocação de memória
|
||||
impraticavelmente grande se as "convencionais" técnicas
|
||||
error-free hashing fossem aplicado.
|
||||
error-free hashing fossem aplicadas.
|
||||
|
||||
## Descrição do algoritmo
|
||||
|
||||
|
||||
54
src/data-structures/bloom-filter/README.uk-UA.md
Normal file
@ -0,0 +1,54 @@
|
||||
# Фільтр Блума
|
||||
|
||||
**Фільтр Блума** - це просторово-ефективна ймовірна структура даних, створена для перевірки наявності елемента
|
||||
у множині. Він спроектований неймовірно швидким за мінімального використання пам'яті ціною потенційних помилкових спрацьовувань.
|
||||
Існує можливість отримати хибнопозитивне спрацьовування (елемента в безлічі немає, але структура даних повідомляє,
|
||||
що він є), але не хибнонегативне. Іншими словами, черга повертає або "можливо в наборі", або "певно не
|
||||
у наборі". Фільтр Блума може використовувати будь-який обсяг пам'яті, проте чим він більший, тим менша вірогідність помилкового
|
||||
спрацьовування.
|
||||
|
||||
Блум запропонував цю техніку для застосування в областях, де кількість вихідних даних потребувала б непрактично багато
|
||||
пам'яті, у разі застосування умовно безпомилкових технік хешування.
|
||||
|
||||
## Опис алгоритму
|
||||
|
||||
Порожній фільтр Блума представлений бітовим масивом з `m` бітів, всі біти якого обнулені. Має бути визначено `k`
|
||||
незалежних хеш-функцій, що відображають кожен елемент множини в одну з `m` позицій у масиві, генеруючи однакове
|
||||
випадковий розподіл. Зазвичай `k` задана константою, яка набагато менше `m` і пропорційна
|
||||
кількості елементів, що додаються; точний вибір `k` та постійної пропорційності `m` визначаються рівнем хибних
|
||||
спрацьовувань фільтра.
|
||||
|
||||
Ось приклад Блум фільтра, що представляє набір `{x, y, z}`. Кольорові стрілки показують позиції в бітовому масиві,
|
||||
яким прив'язаний кожен елемент набору. Елемент `w` не в наборі `{x, y, z}`, тому що він прив'язаний до позиції в бітовому
|
||||
масиві, що дорівнює `0`. Для цієї форми, `m = 18`, а `k = 3`.
|
||||
|
||||
Фільтр Блума є бітовий масив з `m` біт. Спочатку, коли структура даних зберігає порожню множину, всі
|
||||
m біт обнулені. Користувач повинен визначити `k` незалежних хеш-функцій `h1`, …, `hk`,
|
||||
що відображають кожен елемент в одну з m позицій бітового масиву досить рівномірним чином.
|
||||
|
||||
Для додавання елемента e необхідно записати одиниці на кожну з позицій `h1(e)`, …, `hk(e)`
|
||||
бітового масиву.
|
||||
|
||||
Для перевірки приналежності елемента `e` до безлічі елементів, що зберігаються, необхідно перевірити стан бітів
|
||||
`h1(e)`, …, `hk(e)`. Якщо хоча б один з них дорівнює нулю, елемент не може належати множині
|
||||
(інакше при його додаванні всі ці біти були встановлені). Якщо вони рівні одиниці, то структура даних повідомляє,
|
||||
що `е` належить безлічі. При цьому може виникнути дві ситуації: або елемент дійсно належить множині,
|
||||
або всі ці біти виявилися встановлені випадково при додаванні інших елементів, що і є джерелом помилкових
|
||||
спрацьовувань у цій структурі даних.
|
||||
|
||||

|
||||
|
||||
## Застосування
|
||||
|
||||
Фільтр Блума може бути використаний для блогів. Якщо мета полягає в тому, щоб показати читачам лише ті статті,
|
||||
які вони ще не бачили, фільтр блуму ідеальний. Він може містити значення, що хешуються, відповідні статті. Після
|
||||
того, як користувач прочитав кілька статей, вони можуть бути поміщені у фільтр. Наступного разу, коли користувач
|
||||
відвідає сайт, ці статті можуть бути вилучені з результатів за допомогою фільтра.
|
||||
|
||||
Деякі статті неминуче будуть відфільтровані помилково, але ціна прийнятна. Те, що користувач не побачить дещо
|
||||
статей цілком прийнятно, беручи до уваги той факт, що йому завжди показуються інші нові статті при кожному
|
||||
новому відвідуванні.
|
||||
|
||||
## Посилання
|
||||
|
||||
- [Wikipedia](https://uk.wikipedia.org/wiki/%D0%A4%D1%96%D0%BB%D1%8C%D1%82%D1%80_%D0%91%D0%BB%D1%83%D0%BC%D0%B0)
|
||||
78
src/data-structures/disjoint-set/DisjointSetAdhoc.js
Normal file
@ -0,0 +1,78 @@
|
||||
/**
|
||||
* The minimalistic (ad hoc) version of a DisjointSet (or a UnionFind) data structure
|
||||
* that doesn't have external dependencies and that is easy to copy-paste and
|
||||
* use during the coding interview if allowed by the interviewer (since many
|
||||
* data structures in JS are missing).
|
||||
*
|
||||
* Time Complexity:
|
||||
*
|
||||
* - Constructor: O(N)
|
||||
* - Find: O(α(N))
|
||||
* - Union: O(α(N))
|
||||
* - Connected: O(α(N))
|
||||
*
|
||||
* Where N is the number of vertices in the graph.
|
||||
* α refers to the Inverse Ackermann function.
|
||||
* In practice, we assume it's a constant.
|
||||
* In other words, O(α(N)) is regarded as O(1) on average.
|
||||
*/
|
||||
class DisjointSetAdhoc {
|
||||
/**
|
||||
* Initializes the set of specified size.
|
||||
* @param {number} size
|
||||
*/
|
||||
constructor(size) {
|
||||
// The index of a cell is an id of the node in a set.
|
||||
// The value of a cell is an id (index) of the root node.
|
||||
// By default, the node is a parent of itself.
|
||||
this.roots = new Array(size).fill(0).map((_, i) => i);
|
||||
|
||||
// Using the heights array to record the height of each node.
|
||||
// By default each node has a height of 1 because it has no children.
|
||||
this.heights = new Array(size).fill(1);
|
||||
}
|
||||
|
||||
/**
|
||||
* Finds the root of node `a`
|
||||
* @param {number} a
|
||||
* @returns {number}
|
||||
*/
|
||||
find(a) {
|
||||
if (a === this.roots[a]) return a;
|
||||
this.roots[a] = this.find(this.roots[a]);
|
||||
return this.roots[a];
|
||||
}
|
||||
|
||||
/**
|
||||
* Joins the `a` and `b` nodes into same set.
|
||||
* @param {number} a
|
||||
* @param {number} b
|
||||
* @returns {number}
|
||||
*/
|
||||
union(a, b) {
|
||||
const aRoot = this.find(a);
|
||||
const bRoot = this.find(b);
|
||||
|
||||
if (aRoot === bRoot) return;
|
||||
|
||||
if (this.heights[aRoot] > this.heights[bRoot]) {
|
||||
this.roots[bRoot] = aRoot;
|
||||
} else if (this.heights[aRoot] < this.heights[bRoot]) {
|
||||
this.roots[aRoot] = bRoot;
|
||||
} else {
|
||||
this.roots[bRoot] = aRoot;
|
||||
this.heights[aRoot] += 1;
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* Checks if `a` and `b` belong to the same set.
|
||||
* @param {number} a
|
||||
* @param {number} b
|
||||
*/
|
||||
connected(a, b) {
|
||||
return this.find(a) === this.find(b);
|
||||
}
|
||||
}
|
||||
|
||||
export default DisjointSetAdhoc;
|
||||
@ -2,22 +2,27 @@
|
||||
|
||||
_Read this in other languages:_
|
||||
[_Русский_](README.ru-RU.md),
|
||||
[_Português_](README.pt-BR.md)
|
||||
[_Português_](README.pt-BR.md),
|
||||
[_Українська_](README.uk-UA.md)
|
||||
|
||||
|
||||
**Disjoint-set** data structure (also called a union–find data structure or merge–find set) is a data
|
||||
structure that tracks a set of elements partitioned into a number of disjoint (non-overlapping) subsets.
|
||||
It provides near-constant-time operations (bounded by the inverse Ackermann function) to *add new sets*,
|
||||
to *merge existing sets*, and to *determine whether elements are in the same set*.
|
||||
**Disjoint-set** data structure (also called a union–find data structure or merge–find set) is a data
|
||||
structure that tracks a set of elements partitioned into a number of disjoint (non-overlapping) subsets.
|
||||
It provides near-constant-time operations (bounded by the inverse Ackermann function) to _add new sets_,
|
||||
to _merge existing sets_, and to _determine whether elements are in the same set_.
|
||||
In addition to many other uses (see the Applications section), disjoint-sets play a key role in Kruskal's algorithm for finding the minimum spanning tree of a graph.
|
||||
|
||||

|
||||
|
||||
*MakeSet* creates 8 singletons.
|
||||
_MakeSet_ creates 8 singletons.
|
||||
|
||||

|
||||
|
||||
After some operations of *Union*, some sets are grouped together.
|
||||
After some operations of _Union_, some sets are grouped together.
|
||||
|
||||
## Implementation
|
||||
|
||||
- [DisjointSet.js](./DisjointSet.js)
|
||||
- [DisjointSetAdhoc.js](./DisjointSetAdhoc.js) - The minimalistic (ad hoc) version of a DisjointSet (or a UnionFind) data structure that doesn't have external dependencies and that is easy to copy-paste and use during the coding interview if allowed by the interviewer (since many data structures in JS are missing).
|
||||
|
||||
## References
|
||||
|
||||
|
||||
@ -1,8 +1,8 @@
|
||||
# Conjunto Disjuntor (Disjoint Set)
|
||||
# Conjunto Disjunto (Disjoint Set)
|
||||
|
||||
**Conjunto Disjuntor**
|
||||
**Conjunto Disjunto**
|
||||
|
||||
**Conjunto Disjuntor** é uma estrutura de dados (também chamado de
|
||||
**Conjunto Disjunto** é uma estrutura de dados (também chamado de
|
||||
estrutura de dados de union–find ou merge–find) é uma estrutura de dados
|
||||
que rastreia um conjunto de elementos particionados em um número de
|
||||
subconjuntos separados (sem sobreposição).
|
||||
@ -10,9 +10,9 @@ Ele fornece operações de tempo quase constante (limitadas pela função
|
||||
inversa de Ackermann) para *adicionar novos conjuntos*, para
|
||||
*mesclar/fundir conjuntos existentes* e para *determinar se os elementos
|
||||
estão no mesmo conjunto*.
|
||||
Além de muitos outros usos (veja a seção Applications), conjunto disjuntor
|
||||
Além de muitos outros usos (veja a seção Applications), conjuntos disjuntos
|
||||
desempenham um papel fundamental no algoritmo de Kruskal para encontrar a
|
||||
árvore geradora mínima de um gráfico (graph).
|
||||
árvore geradora mínima de um grafo (graph).
|
||||
|
||||

|
||||
|
||||
|
||||
22
src/data-structures/disjoint-set/README.uk-UA.md
Normal file
@ -0,0 +1,22 @@
|
||||
# Система неперетинних множин
|
||||
|
||||
**Система неперетинних множин** це структура даних (також звана структурою даної пошуку перетину або
|
||||
безліччю пошуку злиття), яка управляє безліччю елементів, розбитих на кілька підмножин, що не перетинаються.
|
||||
Вона надає близько-константний час виконання операцій (обмежений зворотною функцією Акерманна) за додаванням
|
||||
нових множин, *злиття існуючих множин і *випередження, чи відносяться елементи до одного і того ж безлічі.
|
||||
|
||||
Застосовується для зберігання компонентів зв'язності в графах, зокрема, алгоритму Фарбала необхідна подібна структура
|
||||
даних для ефективної реалізації.
|
||||
|
||||
Основні операції:
|
||||
|
||||
- _MakeSet(x)_ - створює одноелементне безліч {x},
|
||||
- _Find(x)_ - повертає ідентифікатор множини, що містить елемент x,
|
||||
- _Union(x,y)_ - об'єднання множин, що містять x та y.
|
||||
|
||||
Після деяких операцій _об'єднання_, деякі множини зібрані разом.
|
||||
|
||||
## Посилання
|
||||
|
||||
- [СНМ на Wikipedia](https://uk.wikipedia.org/wiki/%D0%A1%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%BD%D0%B5%D0%BF%D0%B5%D1%80%D0%B5%D1%82%D0%B8%D0%BD%D0%BD%D0%B8%D1%85_%D0%BC%D0%BD%D0%BE%D0%B6%D0%B8%D0%BD)
|
||||
- [СНМ на YouTube](https://www.youtube.com/watch?v=5XwRPwLnK6I)
|
||||
@ -0,0 +1,50 @@
|
||||
import DisjointSetAdhoc from '../DisjointSetAdhoc';
|
||||
|
||||
describe('DisjointSetAdhoc', () => {
|
||||
it('should create unions and find connected elements', () => {
|
||||
const set = new DisjointSetAdhoc(10);
|
||||
|
||||
// 1-2-5-6-7 3-8-9 4
|
||||
set.union(1, 2);
|
||||
set.union(2, 5);
|
||||
set.union(5, 6);
|
||||
set.union(6, 7);
|
||||
|
||||
set.union(3, 8);
|
||||
set.union(8, 9);
|
||||
|
||||
expect(set.connected(1, 5)).toBe(true);
|
||||
expect(set.connected(5, 7)).toBe(true);
|
||||
expect(set.connected(3, 8)).toBe(true);
|
||||
|
||||
expect(set.connected(4, 9)).toBe(false);
|
||||
expect(set.connected(4, 7)).toBe(false);
|
||||
|
||||
// 1-2-5-6-7 3-8-9-4
|
||||
set.union(9, 4);
|
||||
|
||||
expect(set.connected(4, 9)).toBe(true);
|
||||
expect(set.connected(4, 3)).toBe(true);
|
||||
expect(set.connected(8, 4)).toBe(true);
|
||||
|
||||
expect(set.connected(8, 7)).toBe(false);
|
||||
expect(set.connected(2, 3)).toBe(false);
|
||||
});
|
||||
|
||||
it('should keep the height of the tree small', () => {
|
||||
const set = new DisjointSetAdhoc(10);
|
||||
|
||||
// 1-2-6-7-9 1 3 4 5
|
||||
set.union(7, 6);
|
||||
set.union(1, 2);
|
||||
set.union(2, 6);
|
||||
set.union(1, 7);
|
||||
set.union(9, 1);
|
||||
|
||||
expect(set.connected(1, 7)).toBe(true);
|
||||
expect(set.connected(6, 9)).toBe(true);
|
||||
expect(set.connected(4, 9)).toBe(false);
|
||||
|
||||
expect(Math.max(...set.heights)).toBe(3);
|
||||
});
|
||||
});
|
||||
@ -9,7 +9,9 @@ _Lea esto en otros idiomas:_
|
||||
|
||||
En informática, una **lista doblemente enlazada** es una estructura de datos relacionados que consta de un conjunto de registros conectados secuencialmente llamados nodos. Cada nodo contiene dos campos, llamados enlaces, que son referencias al nodo anterior y al siguiente en la secuencia de nodos. Los enlaces anterior y siguiente de los nodos inicial y final, apuntan respectivamente a algún tipo de terminador (normalmente un nodo centinela o nulo), facilitando así el recorrido de la lista. Si solo hay un nodo nulo, la lista se enlaza circularmente a través este. Puede conceptualizarse como dos listas enlazadas individualmente formadas a partir de los mismos elementos de datos, pero en órdenes secuenciales opuestos.
|
||||
|
||||

|
||||

|
||||
|
||||
*Made with [okso.app](https://okso.app)*
|
||||
|
||||
Los dos enlaces de un nodo permiten recorrer la lista en cualquier dirección. Si bien agregar o eliminar un nodo en una lista doblemente enlazada requiere cambiar más enlaces que las mismas operaciones en una lista enlazada individualmente, las operaciones son más simples y potencialmente más eficientes (para nodos que no sean los primeros) porque no hay necesidad de realizar un seguimiento del nodo anterior durante el recorrido o no es necesario recorrer la lista para encontrar el nodo anterior, de modo que se pueda modificar su enlace.
|
||||
|
||||
|
||||
@ -2,7 +2,9 @@
|
||||
|
||||
コンピュータサイエンスにおいて、**双方向リスト**はノードと呼ばれる一連のリンクレコードからなる連結データ構造です。各ノードはリンクと呼ばれる2つのフィールドを持っていて、これらは一連のノード内における前のノードと次のノードを参照しています。最初のノードの前のリンクと最後のノードの次のリンクはある種の終端を示していて、一般的にはダミーノードやnullが格納され、リストのトラバースを容易に行えるようにしています。もしダミーノードが1つしかない場合、リストはその1つのノードを介して循環的にリンクされます。これは、それぞれ逆の順番の単方向のリンクリストが2つあるものとして考えることができます。
|
||||
|
||||

|
||||

|
||||
|
||||
*Made with [okso.app](https://okso.app)*
|
||||
|
||||
2つのリンクにより、リストをどちらの方向にもトラバースすることができます。双方向リストはノードの追加や削除の際に、片方向リンクリストと比べてより多くのリンクを変更する必要があります。しかし、その操作は簡単で、より効率的な(最初のノード以外の場合)可能性があります。前のノードのリンクを更新する際に前のノードを保持したり、前のノードを見つけるためにリストをトラバースする必要がありません。
|
||||
|
||||
@ -25,7 +27,7 @@ Add(value)
|
||||
end if
|
||||
end Add
|
||||
```
|
||||
|
||||
|
||||
### 削除
|
||||
|
||||
```text
|
||||
@ -62,7 +64,7 @@ Remove(head, value)
|
||||
return false
|
||||
end Remove
|
||||
```
|
||||
|
||||
|
||||
### 逆トラバース
|
||||
|
||||
```text
|
||||
@ -76,7 +78,7 @@ ReverseTraversal(tail)
|
||||
end while
|
||||
end Reverse Traversal
|
||||
```
|
||||
|
||||
|
||||
## 計算量
|
||||
|
||||
## 時間計算量
|
||||
|
||||