Compare commits
41 Commits
f459891437
...
3ad4e2bbb0
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
3ad4e2bbb0 | ||
|
|
6509304ff6 | ||
|
|
ed18c223aa | ||
|
|
09afeb58d8 | ||
|
|
d7a41a6461 | ||
|
|
9046d80bdb | ||
|
|
e5b5944c68 | ||
|
|
2c67b48c21 | ||
|
|
ac78353e3c | ||
|
|
8959566a36 | ||
|
|
729bc4d78a | ||
|
|
8d1f473610 | ||
|
|
111ea3dbd3 | ||
|
|
76617fa83a | ||
|
|
8c5e5f4f0d | ||
|
|
14c563619c | ||
|
|
bbbfd32a45 | ||
|
|
b9304f4787 | ||
|
|
1ad60dc510 | ||
|
|
e95d856e67 | ||
|
|
46aae1d708 | ||
|
|
5a41865787 | ||
|
|
af08253a95 | ||
|
|
5fc33c0f0a | ||
|
|
c9f1caf1ca | ||
|
|
bcd1cc1b00 | ||
|
|
1d6249d552 | ||
|
|
4b4d77071c | ||
|
|
69c3a16f75 | ||
|
|
fbd77551b3 | ||
|
|
f6a0ed42bc | ||
|
|
6c4aa1b6a2 | ||
|
|
3d8dd9a67f | ||
|
|
d408abd833 | ||
|
|
e4f2ccdbec | ||
|
|
6c335c5d83 | ||
|
|
65e4a7c8b3 | ||
|
|
a123b9017d | ||
|
|
2a6f724589 | ||
|
|
a6a4d01f95 | ||
|
|
025b9a390b |
@ -12,9 +12,10 @@
|
|||||||
"arrow-body-style": "off",
|
"arrow-body-style": "off",
|
||||||
"no-loop-func": "off"
|
"no-loop-func": "off"
|
||||||
},
|
},
|
||||||
|
"ignorePatterns": ["*.md", "*.png", "*.jpeg", "*.jpg"],
|
||||||
"settings": {
|
"settings": {
|
||||||
"react": {
|
"react": {
|
||||||
"version": "latest"
|
"version": "18.2.0"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
2
.github/workflows/CI.yml
vendored
@ -11,7 +11,7 @@ jobs:
|
|||||||
runs-on: ubuntu-latest
|
runs-on: ubuntu-latest
|
||||||
strategy:
|
strategy:
|
||||||
matrix:
|
matrix:
|
||||||
node-version: [ 14.x ]
|
node-version: [ 16.x ]
|
||||||
|
|
||||||
steps:
|
steps:
|
||||||
- name: Checkout repository
|
- name: Checkout repository
|
||||||
|
|||||||
18
BACKERS.md
@ -14,6 +14,24 @@
|
|||||||
|
|
||||||
`null`
|
`null`
|
||||||
|
|
||||||
|
<!--
|
||||||
|
<table>
|
||||||
|
<tr>
|
||||||
|
<td align="center">
|
||||||
|
<a href="[PROFILE_URL]">
|
||||||
|
<img
|
||||||
|
src="[PROFILE_IMG_SRC]"
|
||||||
|
width="50"
|
||||||
|
height="50"
|
||||||
|
/>
|
||||||
|
</a>
|
||||||
|
<br />
|
||||||
|
<a href="[PROFILE_URL]">[PROFILE_NAME]</a>
|
||||||
|
</td>
|
||||||
|
</tr>
|
||||||
|
</table>
|
||||||
|
-->
|
||||||
|
|
||||||
<!--
|
<!--
|
||||||
<ul>
|
<ul>
|
||||||
<li>
|
<li>
|
||||||
|
|||||||
@ -23,7 +23,8 @@ _اقرأ هذا في لغات أخرى:_
|
|||||||
[_Türk_](README.tr-TR.md),
|
[_Türk_](README.tr-TR.md),
|
||||||
[_Italiana_](README.it-IT.md),
|
[_Italiana_](README.it-IT.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
☝ ملاحضة هذا المشروع مخصص للاستخدام لأغراض التعلم والبحث
|
☝ ملاحضة هذا المشروع مخصص للاستخدام لأغراض التعلم والبحث
|
||||||
فقط ، و ** ليست ** معدة للاستخدام في **الإنتاج**
|
فقط ، و ** ليست ** معدة للاستخدام في **الإنتاج**
|
||||||
|
|||||||
@ -24,7 +24,8 @@ _Lies dies in anderen Sprachen:_
|
|||||||
[_Italiana_](README.it-IT.md),
|
[_Italiana_](README.it-IT.md),
|
||||||
[_Bahasa Indonesia_](README.id-ID.md),
|
[_Bahasa Indonesia_](README.id-ID.md),
|
||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md)
|
[_Arabic_](README.ar-AR.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
_☝ Beachte, dass dieses Projekt nur für Lern- und Forschungszwecke gedacht ist und **nicht** für den produktiven Einsatz verwendet werden soll_
|
_☝ Beachte, dass dieses Projekt nur für Lern- und Forschungszwecke gedacht ist und **nicht** für den produktiven Einsatz verwendet werden soll_
|
||||||
|
|
||||||
|
|||||||
@ -25,7 +25,8 @@ _Léelo en otros idiomas:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
*☝ Nótese que este proyecto está pensado con fines de aprendizaje e investigación,
|
*☝ Nótese que este proyecto está pensado con fines de aprendizaje e investigación,
|
||||||
y **no** para ser usado en producción.*
|
y **no** para ser usado en producción.*
|
||||||
|
|||||||
@ -26,7 +26,8 @@ _Lisez ceci dans d'autres langues:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
## Data Structures
|
## Data Structures
|
||||||
|
|
||||||
|
|||||||
@ -23,7 +23,8 @@ _Baca ini dalam bahasa yang lain:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
_☝ Perhatikan bahwa proyek ini hanya dimaksudkan untuk tujuan pembelajaran dan riset, dan **tidak** dimaksudkan untuk digunakan sebagai produksi._
|
_☝ Perhatikan bahwa proyek ini hanya dimaksudkan untuk tujuan pembelajaran dan riset, dan **tidak** dimaksudkan untuk digunakan sebagai produksi._
|
||||||
|
|
||||||
|
|||||||
@ -22,7 +22,8 @@ _Leggilo in altre lingue:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
*☝ Si noti che questo progetto è destinato ad essere utilizzato solo per l'apprendimento e la ricerca e non è destinato ad essere utilizzato per il commercio.*
|
*☝ Si noti che questo progetto è destinato ad essere utilizzato solo per l'apprendimento e la ricerca e non è destinato ad essere utilizzato per il commercio.*
|
||||||
|
|
||||||
|
|||||||
@ -25,7 +25,8 @@ _Read this in other languages:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
## データ構造
|
## データ構造
|
||||||
|
|
||||||
|
|||||||
@ -24,7 +24,8 @@ _Read this in other languages:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
## 자료 구조
|
## 자료 구조
|
||||||
|
|
||||||
|
|||||||
30
README.md
@ -1,14 +1,17 @@
|
|||||||
# JavaScript Algorithms and Data Structures
|
# JavaScript Algorithms and Data Structures
|
||||||
|
|
||||||
> 🇺🇦 UKRAINE [IS BEING ATTACKED](https://war.ukraine.ua/) BY RUSSIAN ARMY. CIVILIANS ARE GETTING KILLED. RESIDENTIAL AREAS ARE GETTING BOMBED.
|
> 🇺🇦 UKRAINE [IS BEING ATTACKED](https://war.ukraine.ua/) BY RUSSIAN ARMY. CIVILIANS ARE GETTING KILLED. RESIDENTIAL AREAS ARE GETTING BOMBED.
|
||||||
> - Help Ukraine via [National Bank of Ukraine](https://bank.gov.ua/en/news/all/natsionalniy-bank-vidkriv-spetsrahunok-dlya-zboru-koshtiv-na-potrebi-armiyi)
|
> - Help Ukraine via:
|
||||||
> - Help Ukraine via [SaveLife](https://savelife.in.ua/en/donate-en/) fund
|
> - [Serhiy Prytula Charity Foundation](https://prytulafoundation.org/en/)
|
||||||
|
> - [Come Back Alive Charity Foundation](https://savelife.in.ua/en/donate-en/)
|
||||||
|
> - [National Bank of Ukraine](https://bank.gov.ua/en/news/all/natsionalniy-bank-vidkriv-spetsrahunok-dlya-zboru-koshtiv-na-potrebi-armiyi)
|
||||||
> - More info on [war.ukraine.ua](https://war.ukraine.ua/) and [MFA of Ukraine](https://twitter.com/MFA_Ukraine)
|
> - More info on [war.ukraine.ua](https://war.ukraine.ua/) and [MFA of Ukraine](https://twitter.com/MFA_Ukraine)
|
||||||
|
|
||||||
<hr/>
|
<hr/>
|
||||||
|
|
||||||
[](https://github.com/trekhleb/javascript-algorithms/actions?query=workflow%3ACI+branch%3Amaster)
|
[](https://github.com/trekhleb/javascript-algorithms/actions?query=workflow%3ACI+branch%3Amaster)
|
||||||
[](https://codecov.io/gh/trekhleb/javascript-algorithms)
|
[](https://codecov.io/gh/trekhleb/javascript-algorithms)
|
||||||
|

|
||||||
|
|
||||||
This repository contains JavaScript based examples of many
|
This repository contains JavaScript based examples of many
|
||||||
popular algorithms and data structures.
|
popular algorithms and data structures.
|
||||||
@ -33,7 +36,8 @@ _Read this in other languages:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
*☝ Note that this project is meant to be used for learning and researching purposes
|
*☝ Note that this project is meant to be used for learning and researching purposes
|
||||||
only, and it is **not** meant to be used for production.*
|
only, and it is **not** meant to be used for production.*
|
||||||
@ -45,6 +49,8 @@ be accessed and modified efficiently. More precisely, a data structure is a coll
|
|||||||
values, the relationships among them, and the functions or operations that can be applied to
|
values, the relationships among them, and the functions or operations that can be applied to
|
||||||
the data.
|
the data.
|
||||||
|
|
||||||
|
Remember that each data has its own trade-offs. And you need to pay attention more to why you're choosing a certain data structure than to how to implement it.
|
||||||
|
|
||||||
`B` - Beginner, `A` - Advanced
|
`B` - Beginner, `A` - Advanced
|
||||||
|
|
||||||
* `B` [Linked List](src/data-structures/linked-list)
|
* `B` [Linked List](src/data-structures/linked-list)
|
||||||
@ -62,8 +68,9 @@ the data.
|
|||||||
* `A` [Segment Tree](src/data-structures/tree/segment-tree) - with min/max/sum range queries examples
|
* `A` [Segment Tree](src/data-structures/tree/segment-tree) - with min/max/sum range queries examples
|
||||||
* `A` [Fenwick Tree](src/data-structures/tree/fenwick-tree) (Binary Indexed Tree)
|
* `A` [Fenwick Tree](src/data-structures/tree/fenwick-tree) (Binary Indexed Tree)
|
||||||
* `A` [Graph](src/data-structures/graph) (both directed and undirected)
|
* `A` [Graph](src/data-structures/graph) (both directed and undirected)
|
||||||
* `A` [Disjoint Set](src/data-structures/disjoint-set)
|
* `A` [Disjoint Set](src/data-structures/disjoint-set) - a union–find data structure or merge–find set
|
||||||
* `A` [Bloom Filter](src/data-structures/bloom-filter)
|
* `A` [Bloom Filter](src/data-structures/bloom-filter)
|
||||||
|
* `A` [LRU Cache](src/data-structures/lru-cache/) - Least Recently Used (LRU) cache
|
||||||
|
|
||||||
## Algorithms
|
## Algorithms
|
||||||
|
|
||||||
@ -99,7 +106,7 @@ a set of rules that precisely define a sequence of operations.
|
|||||||
* **Sets**
|
* **Sets**
|
||||||
* `B` [Cartesian Product](src/algorithms/sets/cartesian-product) - product of multiple sets
|
* `B` [Cartesian Product](src/algorithms/sets/cartesian-product) - product of multiple sets
|
||||||
* `B` [Fisher–Yates Shuffle](src/algorithms/sets/fisher-yates) - random permutation of a finite sequence
|
* `B` [Fisher–Yates Shuffle](src/algorithms/sets/fisher-yates) - random permutation of a finite sequence
|
||||||
* `A` [Power Set](src/algorithms/sets/power-set) - all subsets of a set (bitwise and backtracking solutions)
|
* `A` [Power Set](src/algorithms/sets/power-set) - all subsets of a set (bitwise, backtracking, and cascading solutions)
|
||||||
* `A` [Permutations](src/algorithms/sets/permutations) (with and without repetitions)
|
* `A` [Permutations](src/algorithms/sets/permutations) (with and without repetitions)
|
||||||
* `A` [Combinations](src/algorithms/sets/combinations) (with and without repetitions)
|
* `A` [Combinations](src/algorithms/sets/combinations) (with and without repetitions)
|
||||||
* `A` [Longest Common Subsequence](src/algorithms/sets/longest-common-subsequence) (LCS)
|
* `A` [Longest Common Subsequence](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||||
@ -132,6 +139,7 @@ a set of rules that precisely define a sequence of operations.
|
|||||||
* `B` [Shellsort](src/algorithms/sorting/shell-sort)
|
* `B` [Shellsort](src/algorithms/sorting/shell-sort)
|
||||||
* `B` [Counting Sort](src/algorithms/sorting/counting-sort)
|
* `B` [Counting Sort](src/algorithms/sorting/counting-sort)
|
||||||
* `B` [Radix Sort](src/algorithms/sorting/radix-sort)
|
* `B` [Radix Sort](src/algorithms/sorting/radix-sort)
|
||||||
|
* `B` [Bucket Sort](src/algorithms/sorting/bucket-sort)
|
||||||
* **Linked Lists**
|
* **Linked Lists**
|
||||||
* `B` [Straight Traversal](src/algorithms/linked-list/traversal)
|
* `B` [Straight Traversal](src/algorithms/linked-list/traversal)
|
||||||
* `B` [Reverse Traversal](src/algorithms/linked-list/reverse-traversal)
|
* `B` [Reverse Traversal](src/algorithms/linked-list/reverse-traversal)
|
||||||
@ -279,14 +287,14 @@ npm test -- 'LinkedList'
|
|||||||
|
|
||||||
**Troubleshooting**
|
**Troubleshooting**
|
||||||
|
|
||||||
In case if linting or testing is failing try to delete the `node_modules` folder and re-install npm packages:
|
If linting or testing is failing, try to delete the `node_modules` folder and re-install npm packages:
|
||||||
|
|
||||||
```
|
```
|
||||||
rm -rf ./node_modules
|
rm -rf ./node_modules
|
||||||
npm i
|
npm i
|
||||||
```
|
```
|
||||||
|
|
||||||
Also make sure that you're using a correct Node version (`>=14.16.0`). If you're using [nvm](https://github.com/nvm-sh/nvm) for Node version management you may run `nvm use` from the root folder of the project and the correct version will be picked up.
|
Also make sure that you're using a correct Node version (`>=16`). If you're using [nvm](https://github.com/nvm-sh/nvm) for Node version management you may run `nvm use` from the root folder of the project and the correct version will be picked up.
|
||||||
|
|
||||||
**Playground**
|
**Playground**
|
||||||
|
|
||||||
@ -360,10 +368,10 @@ Below is the list of some of the most used Big O notations and their performance
|
|||||||
|
|
||||||
> You may support this project via ❤️️ [GitHub](https://github.com/sponsors/trekhleb) or ❤️️ [Patreon](https://www.patreon.com/trekhleb).
|
> You may support this project via ❤️️ [GitHub](https://github.com/sponsors/trekhleb) or ❤️️ [Patreon](https://www.patreon.com/trekhleb).
|
||||||
|
|
||||||
[Folks who are backing this project](https://github.com/trekhleb/javascript-algorithms/blob/master/BACKERS.md) `∑ = 0`
|
[Folks who are backing this project](https://github.com/trekhleb/javascript-algorithms/blob/master/BACKERS.md) `∑ = 1`
|
||||||
|
|
||||||
> ℹ️ A few more [projects](https://trekhleb.dev/projects/) and [articles](https://trekhleb.dev/blog/) about JavaScript and algorithms on [trekhleb.dev](https://trekhleb.dev)
|
|
||||||
|
|
||||||
## Author
|
## Author
|
||||||
|
|
||||||
- [@trekhleb](https://trekhleb.dev)
|
[@trekhleb](https://trekhleb.dev)
|
||||||
|
|
||||||
|
A few more [projects](https://trekhleb.dev/projects/) and [articles](https://trekhleb.dev/blog/) about JavaScript and algorithms on [trekhleb.dev](https://trekhleb.dev)
|
||||||
|
|||||||
@ -26,7 +26,8 @@ _Read this in other languages:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
## Struktury Danych
|
## Struktury Danych
|
||||||
|
|
||||||
|
|||||||
@ -26,7 +26,8 @@ _Leia isto em outros idiomas:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
## Estrutura de Dados
|
## Estrutura de Dados
|
||||||
|
|
||||||
|
|||||||
@ -23,7 +23,8 @@ _Читать на других языках:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
*☝ Замечание: этот репозиторий предназначен для учебно-исследовательских целей (**не** для использования в продакшн-системах).*
|
*☝ Замечание: этот репозиторий предназначен для учебно-исследовательских целей (**не** для использования в продакшн-системах).*
|
||||||
|
|
||||||
|
|||||||
@ -23,7 +23,8 @@ _Read this in other languages:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
*☝ Not, bu proje araştırma ve öğrenme amacı ile yapılmış
|
*☝ Not, bu proje araştırma ve öğrenme amacı ile yapılmış
|
||||||
olup üretim için **yapılmamıştır**.*
|
olup üretim için **yapılmamıştır**.*
|
||||||
|
|||||||
@ -23,7 +23,8 @@ _Вивчення матеріалу на інших мовах:_
|
|||||||
[_Bahasa Indonesia_](README.id-ID.md),
|
[_Bahasa Indonesia_](README.id-ID.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
*☝ Зверніть увагу! Даний проект призначений лише для навчальних та дослідницьких цілей, і він **не** призначений для виробництва (продакшн).*
|
*☝ Зверніть увагу! Даний проект призначений лише для навчальних та дослідницьких цілей, і він **не** призначений для виробництва (продакшн).*
|
||||||
|
|
||||||
|
|||||||
358
README.uz-UZ.md
Normal file
@ -0,0 +1,358 @@
|
|||||||
|
# JavaScript algoritmlari va ma'lumotlar tuzilmalari
|
||||||
|
|
||||||
|
[](https://github.com/trekhleb/javascript-algorithms/actions?query=workflow%3ACI+branch%3Amaster)
|
||||||
|
[](https://codecov.io/gh/trekhleb/javascript-algorithms)
|
||||||
|

|
||||||
|
|
||||||
|
Bu repozitoriyada JavaScript-ga asoslangan ko'plab mashhur algoritmlar
|
||||||
|
va ma'lumotlar tuzilmalarining namunalari mavjud.
|
||||||
|
|
||||||
|
Har bir algoritm va ma'lumotlar tuzilmasining alohida README fayli
|
||||||
|
bo'lib, unda tegishli tushuntirishlar va qo'shimcha o'qish uchun
|
||||||
|
havolalar (shu jumladan YouTube videolariga ham havolalar) mavjud.
|
||||||
|
|
||||||
|
_Read this in other languages:_
|
||||||
|
[_简体中文_](README.zh-CN.md),
|
||||||
|
[_繁體中文_](README.zh-TW.md),
|
||||||
|
[_한국어_](README.ko-KR.md),
|
||||||
|
[_日本語_](README.ja-JP.md),
|
||||||
|
[_Polski_](README.pl-PL.md),
|
||||||
|
[_Français_](README.fr-FR.md),
|
||||||
|
[_Español_](README.es-ES.md),
|
||||||
|
[_Português_](README.pt-BR.md),
|
||||||
|
[_Русский_](README.ru-RU.md),
|
||||||
|
[_Türkçe_](README.tr-TR.md),
|
||||||
|
[_Italiana_](README.it-IT.md),
|
||||||
|
[_Bahasa Indonesia_](README.id-ID.md),
|
||||||
|
[_Українська_](README.uk-UA.md),
|
||||||
|
[_Arabic_](README.ar-AR.md),
|
||||||
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
|
Yodda tuting, bu loyiha faqat o'quv va tadqiqot maqsadida ishlatilishi
|
||||||
|
uchun mo'ljallangan va ishlab chiqarishda ishlatilishi **mumkin emas**.
|
||||||
|
|
||||||
|
## Ma'lumotlar tuzilmalari
|
||||||
|
|
||||||
|
Ma'lumotlar tuzilmasi - bu kompyuterda ma'lumotlarni samarali tarzda
|
||||||
|
olish va o'zgartirish uchun ularni tashkil etish va saqlashning ma'lum
|
||||||
|
bir usuli. Ayniqsa, ma'lumotlar tuzilmasi ma'lumot qiymatlarining
|
||||||
|
to'plami, ular orasidagi munosabatlar va ma'lumotlarga qo'llanilishi
|
||||||
|
mumkin bo'lgan funksiyalar yoki operatsiyalardir.
|
||||||
|
|
||||||
|
`B` - Boshlang'ich, `A` - Ilg'or
|
||||||
|
|
||||||
|
- `B` [Bog'langan ro'yxat](src/data-structures/linked-list)
|
||||||
|
- `B` [Ikki marta bog'langan ro'yxat](src/data-structures/doubly-linked-list)
|
||||||
|
- `B` [Navbat](src/data-structures/queue)
|
||||||
|
- `B` [Stek](src/data-structures/stack)
|
||||||
|
- `B` [Hash jadvali](src/data-structures/hash-table)
|
||||||
|
- `B` [Heap](src/data-structures/heap) - maksimal va minimal heap versiyalari
|
||||||
|
- `B` [Ustuvor navbat](src/data-structures/priority-queue)
|
||||||
|
- `A` [Trie](src/data-structures/trie)
|
||||||
|
- `A` [Daraxt](src/data-structures/tree)
|
||||||
|
- `A` [Ikkilik qidiruv daraxt](src/data-structures/tree/binary-search-tree)
|
||||||
|
- `A` [AVL daraxt](src/data-structures/tree/avl-tree)
|
||||||
|
- `A` [Qizil-qora daraxt](src/data-structures/tree/red-black-tree)
|
||||||
|
- `A` [Segment daraxt](src/data-structures/tree/segment-tree) - min/max/sum diapazon so'rovlari bilan misollar
|
||||||
|
- `A` [Fenwick daraxt](src/data-structures/tree/fenwick-tree) (ikkilik indeksli daraxt)
|
||||||
|
- `A` [Graf](src/data-structures/graph) (yo'naltirilgan hamda yo'naltirilmagan)
|
||||||
|
- `A` [Ajratilgan to'plam](src/data-structures/disjoint-set) - union-find ma'lumotlar strukturasi yoki merge-find to'plami
|
||||||
|
- `A` [Bloom filtri](src/data-structures/bloom-filter)
|
||||||
|
- `A` [LRU keshi](src/data-structures/lru-cache/) - Eng kam ishlatilgan (LRU) keshi
|
||||||
|
|
||||||
|
## Algoritmlar
|
||||||
|
|
||||||
|
Algoritm muammolar sinfini qanday hal qilishning aniq spetsifikatsiyasi. Bu operatsiyalar ketma-ketligini aniqlaydigan qoidalar to'plami.
|
||||||
|
|
||||||
|
`B` - Boshlang'ich, `A` - Ilg'or
|
||||||
|
|
||||||
|
### Mavzu bo'yicha algoritmlar
|
||||||
|
|
||||||
|
- **Matematika**
|
||||||
|
- `B` [Bit manipulatsiyasi](src/algorithms/math/bits) - bitlarni qo'yish/olish/yangilash/tozalash, ikkilikka ko'paytirish/bo'lish, manfiy qilish va hokazo.
|
||||||
|
- `B` [Ikkilik suzuvchi nuqta](src/algorithms/math/binary-floating-point) - suzuvchi nuqtali sonlarning ikkilik tasviri.
|
||||||
|
- `B` [Faktorial](src/algorithms/math/factorial)
|
||||||
|
- `B` [Fibonachchi raqam](src/algorithms/math/fibonacci) - klassik va yopiq shakldagi versiyalar
|
||||||
|
- `B` [Asosiy omillar](src/algorithms/math/prime-factors) - tub omillarni topish va ularni Xardi-Ramanujan teoremasi yordamida sanash
|
||||||
|
- `B` [Birlamchilik testi](src/algorithms/math/primality-test) (sinov bo'linish usuli)
|
||||||
|
- `B` [Evklid algoritmi](src/algorithms/math/euclidean-algorithm) - eng katta umumiy bo'luvchini (EKUB) hisoblash
|
||||||
|
- `B` [Eng kichik umumiy karrali](src/algorithms/math/least-common-multiple) (EKUK)
|
||||||
|
- `B` [Eratosfen elagi](src/algorithms/math/sieve-of-eratosthenes) - berilgan chegaragacha barcha tub sonlarni topish
|
||||||
|
- `B` [Ikkining darajasimi](src/algorithms/math/is-power-of-two) - raqamning ikkining darajasi ekanligini tekshirish (sodda va bitli algoritmlar)
|
||||||
|
- `B` [Paskal uchburchagi](src/algorithms/math/pascal-triangle)
|
||||||
|
- `B` [Kompleks sonlar](src/algorithms/math/complex-number) - kompleks sonlar va ular bilan asosiy amallar
|
||||||
|
- `B` [Radian & Daraja](src/algorithms/math/radian) - radianlarni darajaga va orqaga aylantirish
|
||||||
|
- `B` [Tez ko'tarish](src/algorithms/math/fast-powering)
|
||||||
|
- `B` [Horner metodi](src/algorithms/math/horner-method) - polinomlarni baholash
|
||||||
|
- `B` [Matritsalar](src/algorithms/math/matrix) - matritsalar va asosiy matritsa operatsiyalari (ko'paytirish, transpozitsiya va boshqalar).
|
||||||
|
- `B` [Evklid masofasi](src/algorithms/math/euclidean-distance) - ikki nuqta/vektor/matritsa orasidagi masofa
|
||||||
|
- `A` [Butun sonlarni bo'lish](src/algorithms/math/integer-partition)
|
||||||
|
- `A` [Kvadrat ildiz](src/algorithms/math/square-root) - Nyuton metodi
|
||||||
|
- `A` [Liu Hui π algoritmi](src/algorithms/math/liu-hui) - N-gonlarga asoslangan π ning taxminiy hisoblari
|
||||||
|
- `A` [Diskret Furye transformatsiyasi](src/algorithms/math/fourier-transform) - vaqt funksiyasini (signalni) uni tashkil etuvchi chastotalarga ajratish
|
||||||
|
- **Sets**
|
||||||
|
- `B` [Karteziya maxsuloti](src/algorithms/sets/cartesian-product) - bir nechta to'plamlarning ko'paytmasi
|
||||||
|
- `B` [Fisher–Yates Shuffle](src/algorithms/sets/fisher-yates) - chekli ketma-ketlikni tasodifiy almashtirish
|
||||||
|
- `A` [Power Set](src/algorithms/sets/power-set) - to'plamning barcha kichik to'plamlari (bitwise, backtracking va kaskadli echimlar)
|
||||||
|
- `A` [Permutatsiyalar](src/algorithms/sets/permutations) (takroriyalash bilan va takroriyalashsiz)
|
||||||
|
- `A` [Kombinatsiyalar](src/algorithms/sets/combinations) (takroriyalash bilan va takroriyalashsiz)
|
||||||
|
- `A` [Eng uzun umumiy ketma-ketlik](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||||
|
- `A` [Eng uzun ortib boruvchi ketma-ketlik](src/algorithms/sets/longest-increasing-subsequence)
|
||||||
|
- `A` [Eng qisqa umumiy ketma-ketlik](src/algorithms/sets/shortest-common-supersequence) (SCS)
|
||||||
|
- `A` [Knapsack muammosi](src/algorithms/sets/knapsack-problem) - "0/1" va "Bir-biriga bog'lanmagan"
|
||||||
|
- `A` [Maksimal kichik massiv](src/algorithms/sets/maximum-subarray) - Toʻliq kuch va dinamik dasturlash (Kadane usuli) versiyalari
|
||||||
|
- `A` [Kombinatsiya yig'indisi](src/algorithms/sets/combination-sum) - ma'lum summani tashkil etuvchi barcha kombinatsiyalarni topish
|
||||||
|
- **Stringlar**
|
||||||
|
- `B` [Hamming masofasi](src/algorithms/string/hamming-distance) - belgilarning bir-biridan farq qiladigan pozitsiyalar soni
|
||||||
|
- `B` [Palindrom](src/algorithms/string/palindrome) - satrning teskari tomoni ham bir xil ekanligini tekshirish
|
||||||
|
- `A` [Levenshtein masofasi](src/algorithms/string/levenshtein-distance) - ikki ketma-ketlik o'rtasidagi minimal tahrirlash masofasi
|
||||||
|
- `A` [Knuth–Morris–Pratt Algoritmi](src/algorithms/string/knuth-morris-pratt) (KMP Algoritmi) - kichik qatorlarni qidirish (mosh keluvchi naqshni qidirish)
|
||||||
|
- `A` [Z Algoritmi](src/algorithms/string/z-algorithm) - kichik qatorlarni qidirish (mosh keluvchi naqshni qidirish)
|
||||||
|
- `A` [Rabin Karp Algoritmi](src/algorithms/string/rabin-karp) - kichik qatorlarni qidirish
|
||||||
|
- `A` [Eng uzun umumiy kichik matn](src/algorithms/string/longest-common-substring)
|
||||||
|
- `A` [Regulyar ifoda moslashuvi](src/algorithms/string/regular-expression-matching) (RegEx)
|
||||||
|
- **Qidiruvlar**
|
||||||
|
- `B` [Linear qidirish](src/algorithms/search/linear-search)
|
||||||
|
- `B` [Jump qidirish](src/algorithms/search/jump-search) (yoki Blok qidirish) - saralangan qatorda qidirish
|
||||||
|
- `B` [Ikkilik qidirish](src/algorithms/search/binary-search) - saralangan qatorda qidirish
|
||||||
|
- `B` [Interpolatsiya qidirish](src/algorithms/search/interpolation-search) - bir tekis taqsimlangan saralangan qatorda qidirish
|
||||||
|
- **Tartiblash**
|
||||||
|
- `B` [Pufakcha tartiblash](src/algorithms/sorting/bubble-sort)
|
||||||
|
- `B` [Tanlash tartibi](src/algorithms/sorting/selection-sort)
|
||||||
|
- `B` [Kiritish tartibi](src/algorithms/sorting/insertion-sort)
|
||||||
|
- `B` [Heap tartibi](src/algorithms/sorting/heap-sort)
|
||||||
|
- `B` [Birlashtirish tartibi](src/algorithms/sorting/merge-sort)
|
||||||
|
- `B` [Tezkor saralash](src/algorithms/sorting/quick-sort) - joyida va joyida bo'lmagan amalga oshirish
|
||||||
|
- `B` [Shell tartiblash](src/algorithms/sorting/shell-sort)
|
||||||
|
- `B` [Sanash tartibi](src/algorithms/sorting/counting-sort)
|
||||||
|
- `B` [Radiksli tartiblash](src/algorithms/sorting/radix-sort)
|
||||||
|
- `B` [Bucket tartiblash](src/algorithms/sorting/bucket-sort)
|
||||||
|
- **Bog'langan ro'yhatlar**
|
||||||
|
- `B` [To'g'ri traversal](src/algorithms/linked-list/traversal)
|
||||||
|
- `B` [Teskari traversal](src/algorithms/linked-list/reverse-traversal)
|
||||||
|
- **Daraxtlar**
|
||||||
|
- `B` [Birinchi-pastga qarab qidirish](src/algorithms/tree/depth-first-search) (Depth-First Search)
|
||||||
|
- `B` [Birinchi-yonga qarab qidirish](src/algorithms/tree/breadth-first-search) (Breadth-First Search)
|
||||||
|
- **Grafiklar**
|
||||||
|
- `B` [Birinchi-pastga qarab qidirish](src/algorithms/graph/depth-first-search) (Depth-First Search)
|
||||||
|
- `B` [Birinchi-yonga qarab qidirish](src/algorithms/graph/breadth-first-search) (Breadth-First Search)
|
||||||
|
- `B` [Kruskal Algoritmi](src/algorithms/graph/kruskal) - og'irlikdagi yo'naltirilmagan grafik uchun Minimal kengayuvchi daraxtni (MST) topish
|
||||||
|
- `A` [Dijkstra Algoritmi](src/algorithms/graph/dijkstra) - grafikning bir cho'qqisidan qolgan barcha nuqtalarga eng qisqa yo'llarni topish
|
||||||
|
- `A` [Bellman-Ford Algoritmi](src/algorithms/graph/bellman-ford) - grafikning bir cho'qqisidan qolgan barcha nuqtalarga eng qisqa yo'llarni topish
|
||||||
|
- `A` [Floyd-Warshall Algoritmi](src/algorithms/graph/floyd-warshall) - grafikning barcha uchlari orasidagi eng qisqa masofalarni topish
|
||||||
|
- `A` [Siklni aniqlash](src/algorithms/graph/detect-cycle) - yo'naltirilgan va yo'naltirilmagan grafiklar uchun (DFS va Disjoint Set-ga asoslangan versiyalar)
|
||||||
|
- `A` [Prim Algoritmi](src/algorithms/graph/prim) - og'irlikdagi yo'naltirilmagan grafik uchun Minimal kengayuvchi daraxtni (MST) topish
|
||||||
|
- `A` [Topologik saralash](src/algorithms/graph/topological-sorting) - DFS metodi
|
||||||
|
- `A` [Artikulyatsiya nuqtalari](src/algorithms/graph/articulation-points) - Tarjan algoritmi (DFS asosida)
|
||||||
|
- `A` [Ko'priklar](src/algorithms/graph/bridges) - DFS asosidagi algoritm
|
||||||
|
- `A` [Eyler yo'li va Eyler sxemasi](src/algorithms/graph/eulerian-path) - Fleury algoritmi - Har bir chekkaga bir marta tashrif buyurish
|
||||||
|
- `A` [Gamilton sikli](src/algorithms/graph/hamiltonian-cycle) - Har bir cho'qqiga bir marta tashrif buyurish
|
||||||
|
- `A` [Kuchli bog'langan komponentlar](src/algorithms/graph/strongly-connected-components) - Kosaraju algoritmi
|
||||||
|
- `A` [Sayohatchi sotuvchi muammosi](src/algorithms/graph/travelling-salesman) - har bir shaharga tashrif buyuradigan va kelib chiqqan shaharga qaytib keladigan eng qisqa yo'l
|
||||||
|
- **Kriptografiya**
|
||||||
|
- `B` [Polynomial Hash](src/algorithms/cryptography/polynomial-hash) - polinomga asoslangan hash funktsiyasi
|
||||||
|
- `B` [Rail Fence Cipher](src/algorithms/cryptography/rail-fence-cipher) - xabarlarni kodlash uchun transpozitsiya shifrlash algoritmi
|
||||||
|
- `B` [Caesar Cipher](src/algorithms/cryptography/caesar-cipher) - oddiy almashtirish shifridir
|
||||||
|
- `B` [Hill Cipher](src/algorithms/cryptography/hill-cipher) - chiziqli algebraga asoslangan almashtirish shifri
|
||||||
|
- **Machine Learning**
|
||||||
|
- `B` [NanoNeuron](https://github.com/trekhleb/nano-neuron) - Mashinalar aslida qanday o'rganishi mumkinligini ko'rsatadigan 7 ta oddiy JS funksiyasi (forward/backward tarqalish)
|
||||||
|
- `B` [k-NN](src/algorithms/ml/knn) - eng yaqin qo'shnilarni tasniflash algoritmi
|
||||||
|
- `B` [k-Means](src/algorithms/ml/k-means) - k-Means kalsterlash algoritmi
|
||||||
|
- **Tasvirga ishlov berish**
|
||||||
|
- `B` [Seam Carving](src/algorithms/image-processing/seam-carving) - kontentga moslashuvchan rasm o'lchamini o'zgartirish algoritmi
|
||||||
|
- **Statistikalar**
|
||||||
|
- `B` [Weighted Random](src/algorithms/statistics/weighted-random) - elementlarning og'irligi asosida ro'yxatdan tasodifiy elementni tanlash
|
||||||
|
- **Evolyutsion algoritmlar**
|
||||||
|
- `A` [Genetik algoritm](https://github.com/trekhleb/self-parking-car-evolution) - avtoturargohni o'rgatish uchun genetik algoritm qanday qo'llanilishiga misol.
|
||||||
|
- **Kategoriyasiz**
|
||||||
|
- `B` [Xanoy minorasi](src/algorithms/uncategorized/hanoi-tower)
|
||||||
|
- `B` [Kvadrat matritsaning aylanishi](src/algorithms/uncategorized/square-matrix-rotation) - joyidagi algoritm
|
||||||
|
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game) - orqaga qaytish, dinamik dasturlash (yuqoridan pastga + pastdan yuqoriga) va ochko'z misollar
|
||||||
|
- `B` [Noyob yo'llar](src/algorithms/uncategorized/unique-paths) - orqaga qaytish, dinamik dasturlash va Paskal uchburchagiga asoslangan misolla
|
||||||
|
- `B` [Yomg'ir teraslari](src/algorithms/uncategorized/rain-terraces) - yomg'ir suvini ushlab turish muammosi (dinamik dasturlash va qo'pol kuch versiyalari)
|
||||||
|
- `B` [Rekursiv zinapoya](src/algorithms/uncategorized/recursive-staircase) - yuqoriga chiqish yo'llari sonini hisoblash (4 ta echim)
|
||||||
|
- `B` [Aksiyalarni sotib olish va sotish uchun eng yaxshi vaqt](src/algorithms/uncategorized/best-time-to-buy-sell-stocks) - bo'linib-zabt etish va bir marta o'tish misollari
|
||||||
|
- `A` [N-Queens Muommosi](src/algorithms/uncategorized/n-queens)
|
||||||
|
- `A` [Ritsar sayohati](src/algorithms/uncategorized/knight-tour)
|
||||||
|
|
||||||
|
### Paradigma bo'yicha algoritmlar
|
||||||
|
|
||||||
|
Algorithmic paradigm - bu algoritmlar sinfini loyihalashtirishga asos bo'lib xizmat qiladigan umumiy usul yoki yondashuv. Bu algoritm tushunchasidan yuqori darajadagi abstraktsiya bo'lib, algoritm kompyuter dasturi tushunchasidan yuqori darajadagi abstraktsiya bo'lgani kabi.
|
||||||
|
|
||||||
|
- **Brute Force** - barcha imkoniyatlarni ko'rib chiqib va eng yaxshi echimni tanlash
|
||||||
|
- `B` [Chiziqli qidirish](src/algorithms/search/linear-search)
|
||||||
|
- `B` [Yomg'irli teraslar](src/algorithms/uncategorized/rain-terraces) - yomg'ir suvini to'plash muammosi
|
||||||
|
- `B` [Rekursiv zinapoya](src/algorithms/uncategorized/recursive-staircase) - cho'qqiga chiqish yo'llari sonini hisoblash
|
||||||
|
- `A` [Maksimal kichik massiv](src/algorithms/sets/maximum-subarray)
|
||||||
|
- `A` [Sayohatchi sotuvchi muammosi](src/algorithms/graph/travelling-salesman) - har bir shaharga tashrif buyuradigan va kelib chiqqan shaharga qaytib keladigan eng qisqa yo'l
|
||||||
|
- `A` [Diskret Furye transformatsiyasi](src/algorithms/math/fourier-transform) - vaqt funksiyasini (signalni) uni tashkil etuvchi chastotalarga ajratish
|
||||||
|
- **Greedy** - kelajakni o'ylamasdan, hozirgi vaqtda eng yaxshi variantni tanlash
|
||||||
|
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game)
|
||||||
|
- `A` [Bog'lanmagan yukxalta muammosi](src/algorithms/sets/knapsack-problem)
|
||||||
|
- `A` [Dijkstra Algoritmi](src/algorithms/graph/dijkstra) - grafikning bir cho'qqisidan qolgan barcha nuqtalarga eng qisqa yo'llarni topish
|
||||||
|
- `A` [Prim Algoritmi](src/algorithms/graph/prim) - og'irlikdagi yo'naltirilmagan grafik uchun Minimal kengayuvchi daraxtni (MST) topish
|
||||||
|
- `A` [Kruskal Algoritmi](src/algorithms/graph/kruskal) - og'irlikdagi yo'naltirilmagan grafik uchun Minimal kengayuvchi daraxtni (MST) topish
|
||||||
|
- **Divide and Conquer** - muammoni kichikroq qismlarga bo'lib va keyin bu qismlarni hal qilish
|
||||||
|
|
||||||
|
- `B` [Ikkilik qidiruv](src/algorithms/search/binary-search)
|
||||||
|
- `B` [Xanoy minorasi](src/algorithms/uncategorized/hanoi-tower)
|
||||||
|
- `B` [Paskal uchburchagi](src/algorithms/math/pascal-triangle)
|
||||||
|
- `B` [Evklid Algoritmi](src/algorithms/math/euclidean-algorithm) - eng katta umumiy bo'luvchini (EKUB) hisoblash
|
||||||
|
- `B` [Birlashtirish tartibi](src/algorithms/sorting/merge-sort)
|
||||||
|
- `B` [Tezkor saralash](src/algorithms/sorting/quick-sort)
|
||||||
|
- `B` [Birinchi-pastga qarab qidirish daraxti](src/algorithms/tree/depth-first-search) (DFS)
|
||||||
|
- `B` [Birinchi-pastga qarab qidirish grafigi](src/algorithms/graph/depth-first-search) (DFS)
|
||||||
|
- `B` [Matritsalar](src/algorithms/math/matrix) - turli shakldagi matritsalarni hosil qilish va kesib o'tish
|
||||||
|
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game)
|
||||||
|
- `B` [Tez ko'tarish](src/algorithms/math/fast-powering)
|
||||||
|
- `B` [Aksiyalarni sotib olish va sotish uchun eng yaxshi vaqt](src/algorithms/uncategorized/best-time-to-buy-sell-stocks) - bo'linib-zabt etish va bir marta o'tish misollari
|
||||||
|
- `A` [Permutatsiyalar](src/algorithms/sets/permutations) (takroriyalash bilan va takroriyalashsiz)
|
||||||
|
- `A` [Kombinatsiyalar](src/algorithms/sets/combinations) (takroriyalash bilan va takroriyalashsiz)
|
||||||
|
- `A` [Maksimal kichik massiv](src/algorithms/sets/maximum-subarray)
|
||||||
|
|
||||||
|
- **Dinamik dasturlash** - ilgari topilgan kichik yechimlar yordamida yechim yaratish
|
||||||
|
- `B` [Fibonachchi raqam](src/algorithms/math/fibonacci)
|
||||||
|
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game)
|
||||||
|
- `B` [Noyob yo'llar](src/algorithms/uncategorized/unique-paths)
|
||||||
|
- `B` [Yomg'ir teraslari](src/algorithms/uncategorized/rain-terraces) - yomg'ir suvini to'plash muammosi
|
||||||
|
- `B` [Recursive Staircase](src/algorithms/uncategorized/recursive-staircase) - count the number of ways to reach to the top
|
||||||
|
- `B` [Seam Carving](src/algorithms/image-processing/seam-carving) - kontentga moslashuvchan rasm o'lchamini o'zgartirish algoritmi
|
||||||
|
- `A` [Levenshtein masofasi](src/algorithms/string/levenshtein-distance) - ikki ketma-ketlik o'rtasidagi minimal tahrirlash masofasi
|
||||||
|
- `A` [Eng uzun umumiy ketma-ketlik](src/algorithms/sets/longest-common-subsequence) (LCS)
|
||||||
|
- `A` [Eng uzun umumiy kichik matn](src/algorithms/string/longest-common-substring)
|
||||||
|
- `A` [Eng uzun ortib boruvchi ketma-ketlik](src/algorithms/sets/longest-increasing-subsequence)
|
||||||
|
- `A` [Eng qisqa umumiy ketma-ketlik](src/algorithms/sets/shortest-common-supersequence)
|
||||||
|
- `A` [0/1 Knapsak muommosi](src/algorithms/sets/knapsack-problem)
|
||||||
|
- `A` [Butun sonlarni bo'lish](src/algorithms/math/integer-partition)
|
||||||
|
- `A` [Maksimal kichik massiv](src/algorithms/sets/maximum-subarray)
|
||||||
|
- `A` [Bellman-Ford Algoritmi](src/algorithms/graph/bellman-ford) - grafikning bir cho'qqisidan qolgan barcha nuqtalarga eng qisqa yo'llarni topish
|
||||||
|
- `A` [Floyd-Warshall Algoritmi](src/algorithms/graph/floyd-warshall) -grafikning barcha uchlari orasidagi eng qisqa masofalarni topish
|
||||||
|
- `A` [Regulyar ifoda moslashuvi](src/algorithms/string/regular-expression-matching)
|
||||||
|
- **Backtracking** - brute forcega o'xshab, barcha mumkin bo'lgan yechimlarni generatsiya qilishga harakat qiladi, lekin har safar keyingi yechimni yaratganingizda, yechim barcha shartlarga javob beradimi yoki yo'qligini tekshirasiz va shundan keyingina keyingi yechimlarni ishlab chiqarishni davom ettirasiz. Aks holda, orqaga qaytib, yechim topishning boshqa yo'liga o'tasiz. Odatda state-space ning DFS-qidiruvi ishlatiladi.
|
||||||
|
- `B` [Sakrash o'yini](src/algorithms/uncategorized/jump-game)
|
||||||
|
- `B` [Noyob yo'llar](src/algorithms/uncategorized/unique-paths)
|
||||||
|
- `B` [Power Set](src/algorithms/sets/power-set) - to'plamning barcha kichik to'plamlari
|
||||||
|
- `A` [Gamilton sikli](src/algorithms/graph/hamiltonian-cycle) - Har bir cho'qqiga bir marta tashrif buyurish
|
||||||
|
- `A` [N-Queens muommosi](src/algorithms/uncategorized/n-queens)
|
||||||
|
- `A` [Ritsar sayohati](src/algorithms/uncategorized/knight-tour)
|
||||||
|
- `A` [Kombinatsiya yig'indisi](src/algorithms/sets/combination-sum) - ma'lum summani tashkil etuvchi barcha kombinatsiyalarni topish
|
||||||
|
- **Branch & Bound** - shu paytgacha topilgan eng arzon echimdan kattaroq xarajatlarga ega qisman echimlarni bekor qilish uchun, backtracking qidiruvining har bir bosqichida topilgan eng arzon echimni eslab qoling va shu paytgacha topilgan eng arzon yechim narxidan muammoni eng kam xarajatli yechim narxining past chegarasi sifatida foydalaning. Odatda state-space daraxtining DFS o'tishi bilan birgalikda BFS traversal qo'llaniladi.
|
||||||
|
|
||||||
|
## Ushbu repozitoriyadan qanday foydalanish kerak
|
||||||
|
|
||||||
|
**Barcha dependensiylarni o'rnating**
|
||||||
|
|
||||||
|
```
|
||||||
|
npm install
|
||||||
|
```
|
||||||
|
|
||||||
|
**ESLint ni ishga tushiring**
|
||||||
|
|
||||||
|
Kod sifatini tekshirish uchun ESLint ni ishga tushirishingiz mumkin.
|
||||||
|
|
||||||
|
```
|
||||||
|
npm run lint
|
||||||
|
```
|
||||||
|
|
||||||
|
**Barcha testlarni ishga tushuring**
|
||||||
|
|
||||||
|
```
|
||||||
|
npm test
|
||||||
|
```
|
||||||
|
|
||||||
|
**Testlarni nom bo'yicha ishga tushirish**
|
||||||
|
|
||||||
|
```
|
||||||
|
npm test -- 'LinkedList'
|
||||||
|
```
|
||||||
|
|
||||||
|
**Muammolarni bartaraf qilish (Troubleshooting)**
|
||||||
|
|
||||||
|
Agar linting yoki sinov muvaffaqiyatsiz bo'lsa, `node_modules` papkasini o'chirib, npm paketlarini qayta o'rnatishga harakat qiling:
|
||||||
|
|
||||||
|
```
|
||||||
|
rm -rf ./node_modules
|
||||||
|
npm i
|
||||||
|
```
|
||||||
|
|
||||||
|
Shuningdek, to'g'ri Node versiyasidan foydalanayotganingizga ishonch hosil qiling (`>=16`). Agar Node versiyasini boshqarish uchun [nvm](https://github.com/nvm-sh/nvm) dan foydalanayotgan bo'lsangiz, loyihaning ildiz papkasidan `nvm use` ni ishga tushiring va to'g'ri versiya tanlanadi.
|
||||||
|
|
||||||
|
**O'yin maydoni (Playground)**
|
||||||
|
|
||||||
|
`./src/playground/playground.js` faylida ma'lumotlar strukturalari va algoritmlar bilan o'ynashingiz, `./src/playground/test/playground.test.js` faylida esa ular uchun testlar yozishingiz mumkin.
|
||||||
|
|
||||||
|
Shundan so'ng, playground kodingiz kutilgandek ishlashini tekshirish uchun quyidagi buyruqni ishga tushirishingiz kifoya:
|
||||||
|
|
||||||
|
```
|
||||||
|
npm test -- 'playground'
|
||||||
|
```
|
||||||
|
|
||||||
|
## Foydali ma'lumotlar
|
||||||
|
|
||||||
|
### Manbalar
|
||||||
|
|
||||||
|
- [▶ Data Structures and Algorithms on YouTube](https://www.youtube.com/playlist?list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||||
|
- [✍🏻 Data Structure Sketches](https://okso.app/showcase/data-structures)
|
||||||
|
|
||||||
|
### Big O Notation
|
||||||
|
|
||||||
|
_Big O notation_ algoritmlarni kirish hajmi oshgani sayin ularning ishlash vaqti yoki bo'sh joy talablari qanday o'sishiga qarab tasniflash uchun ishlatiladi. Quyidagi jadvalda siz Big O notatsiyasida ko'rsatilgan algoritmlarning o'sishining eng keng tarqalgan tartiblarini topishingiz mumkin.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Manba: [Big O Cheat Sheet](http://bigocheatsheet.com/).
|
||||||
|
|
||||||
|
Quyida eng ko'p qo'llaniladigan Big O notatsiyalarining ro'yxati va ularning kirish ma'lumotlarining turli o'lchamlariga nisbatan ishlashini taqqoslash keltirilgan.
|
||||||
|
|
||||||
|
| Big O Notatsiya | Turi | 10 ta element uchun hisob-kitoblar | 100 ta element uchun hisob-kitoblar | 1000 ta element uchun hisob-kitoblar |
|
||||||
|
| --------------- | ------------ | ---------------------------------- | ----------------------------------- | ------------------------------------ |
|
||||||
|
| **O(1)** | O'zgarmas | 1 | 1 | 1 |
|
||||||
|
| **O(log N)** | Logarifmik | 3 | 6 | 9 |
|
||||||
|
| **O(N)** | Chiziqli | 10 | 100 | 1000 |
|
||||||
|
| **O(N log N)** | n log(n) | 30 | 600 | 9000 |
|
||||||
|
| **O(N^2)** | Kvadrat | 100 | 10000 | 1000000 |
|
||||||
|
| **O(2^N)** | Eksponensial | 1024 | 1.26e+29 | 1.07e+301 |
|
||||||
|
| **O(N!)** | Faktorial | 3628800 | 9.3e+157 | 4.02e+2567 |
|
||||||
|
|
||||||
|
### Ma'lumotlar tuzilmalarining operatsiyalari murakkabligi
|
||||||
|
|
||||||
|
| Ma'lumotlar tuzilmalari | Kirish | Qidirish | Kiritish | O'chirish | Izohlar |
|
||||||
|
| --------------------------- | :----: | :------: | :------: | :-------: | :--------------------------------------------------------- |
|
||||||
|
| **Massiv** | 1 | n | n | n | |
|
||||||
|
| **Stak** | n | n | 1 | 1 | |
|
||||||
|
| **Navbat** | n | n | 1 | 1 | |
|
||||||
|
| **Bog'langan ro'yhat** | n | n | 1 | n | |
|
||||||
|
| **Hash jadval** | - | n | n | n | Mukammal xash funksiyasi bo'lsa, xarajatlar O (1) bo'ladi. |
|
||||||
|
| **Ikkilik qidiruv daraxti** | n | n | n | n | Balanslangan daraxt narxida O(log(n)) bo'ladi. |
|
||||||
|
| **B-daraxti** | log(n) | log(n) | log(n) | log(n) | |
|
||||||
|
| **Qizil-qora daraxt** | log(n) | log(n) | log(n) | log(n) | |
|
||||||
|
| **AVL Daraxt** | log(n) | log(n) | log(n) | log(n) | |
|
||||||
|
| **Bloom filtri** | - | 1 | 1 | - | Qidiruv paytida noto'g'ri pozitivlar bo'lishi mumkin |
|
||||||
|
|
||||||
|
### Massivlarni saralash algoritmlarining murakkabligi
|
||||||
|
|
||||||
|
| Nomi | Eng yaxshi | O'rta | Eng yomon | Xotira | Barqaror | Izohlar |
|
||||||
|
| ------------------------- | :-----------: | :---------------------: | :-------------------------: | :----: | :------: | :--------------------------------------------------------------------------- |
|
||||||
|
| **Pufakcha tartiblash** | n | n<sup>2</sup> | n<sup>2</sup> | 1 | Ha | |
|
||||||
|
| **Kiritish tartibi** | n | n<sup>2</sup> | n<sup>2</sup> | 1 | Ha | |
|
||||||
|
| **Tanlash tartibi** | n<sup>2</sup> | n<sup>2</sup> | n<sup>2</sup> | 1 | Yo'q | |
|
||||||
|
| **Heap tartibi** | n log(n) | n log(n) | n log(n) | 1 | Yo'q | |
|
||||||
|
| **Birlashtirish tartibi** | n log(n) | n log(n) | n log(n) | n | Ha | |
|
||||||
|
| **Tezkor saralash** | n log(n) | n log(n) | n<sup>2</sup> | log(n) | Yo'q | Tezkor saralash odatda O(log(n)) stek maydoni bilan joyida amalga oshiriladi |
|
||||||
|
| **Shell tartiblash** | n log(n) | depends on gap sequence | n (log(n))<sup>2</sup> | 1 | Yo'q | |
|
||||||
|
| **Sanash tartibi** | n + r | n + r | n + r | n + r | Ha | r - massivdagi eng katta raqam |
|
||||||
|
| **Radiksli tartiblash** | n \* k | n \* k | n \* k | n + k | Ha | k - eng uzun kalitning uzunligi |
|
||||||
|
|
||||||
|
## Loyihani qo'llab-quvvatlovchilar
|
||||||
|
|
||||||
|
> Siz ushbu loyihani ❤️️ [GitHub](https://github.com/sponsors/trekhleb) yoki ❤️️ [Patreon](https://www.patreon.com/trekhleb) orqali qo'llab-quvvatlashingiz mumkin.
|
||||||
|
|
||||||
|
[Ushbu loyihani qo'llab-quvvatlagan odamlar](https://github.com/trekhleb/javascript-algorithms/blob/master/BACKERS.md) `∑ = 1`
|
||||||
|
|
||||||
|
## Muallif
|
||||||
|
|
||||||
|
[@trekhleb](https://trekhleb.dev)
|
||||||
|
|
||||||
|
A few more [projects](https://trekhleb.dev/projects/) and [articles](https://trekhleb.dev/blog/) about JavaScript and algorithms on [trekhleb.dev](https://trekhleb.dev)
|
||||||
@ -23,7 +23,8 @@ _Read this in other languages:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
*注意:这个项目仅用于学习和研究,**不是**用于生产环境。*
|
*注意:这个项目仅用于学习和研究,**不是**用于生产环境。*
|
||||||
|
|
||||||
|
|||||||
@ -22,7 +22,8 @@ _Read this in other languages:_
|
|||||||
[_Українська_](README.uk-UA.md),
|
[_Українська_](README.uk-UA.md),
|
||||||
[_Arabic_](README.ar-AR.md),
|
[_Arabic_](README.ar-AR.md),
|
||||||
[_Tiếng Việt_](README.vi-VN.md),
|
[_Tiếng Việt_](README.vi-VN.md),
|
||||||
[_Deutsch_](README.de-DE.md)
|
[_Deutsch_](README.de-DE.md),
|
||||||
|
[_Uzbek_](README.uz-UZ.md)
|
||||||
|
|
||||||
## 資料結構
|
## 資料結構
|
||||||
|
|
||||||
|
|||||||
@ -24,7 +24,9 @@ module.exports = {
|
|||||||
// This option sets the URL for the jsdom environment.
|
// This option sets the URL for the jsdom environment.
|
||||||
// It is reflected in properties such as location.href.
|
// It is reflected in properties such as location.href.
|
||||||
// @see: https://github.com/facebook/jest/issues/6769
|
// @see: https://github.com/facebook/jest/issues/6769
|
||||||
testURL: 'http://localhost/',
|
testEnvironmentOptions: {
|
||||||
|
url: 'http://localhost/',
|
||||||
|
},
|
||||||
|
|
||||||
// @see: https://jestjs.io/docs/en/configuration#coveragethreshold-object
|
// @see: https://jestjs.io/docs/en/configuration#coveragethreshold-object
|
||||||
coverageThreshold: {
|
coverageThreshold: {
|
||||||
|
|||||||
14008
package-lock.json
generated
25
package.json
@ -35,21 +35,20 @@
|
|||||||
"prepare": "husky install"
|
"prepare": "husky install"
|
||||||
},
|
},
|
||||||
"devDependencies": {
|
"devDependencies": {
|
||||||
"@babel/cli": "7.16.8",
|
"@babel/cli": "7.20.7",
|
||||||
"@babel/preset-env": "7.16.11",
|
"@babel/preset-env": "7.20.2",
|
||||||
"@types/jest": "27.4.0",
|
"@types/jest": "29.4.0",
|
||||||
"canvas": "2.9.0",
|
"eslint": "8.33.0",
|
||||||
"eslint": "8.7.0",
|
|
||||||
"eslint-config-airbnb": "19.0.4",
|
"eslint-config-airbnb": "19.0.4",
|
||||||
"eslint-plugin-import": "2.25.4",
|
"eslint-plugin-import": "2.27.5",
|
||||||
"eslint-plugin-jest": "25.7.0",
|
"eslint-plugin-jest": "27.2.1",
|
||||||
"eslint-plugin-jsx-a11y": "6.5.1",
|
"eslint-plugin-jsx-a11y": "6.7.1",
|
||||||
"eslint-plugin-react": "7.28.0",
|
"husky": "8.0.3",
|
||||||
"husky": "7.0.4",
|
"jest": "29.4.1",
|
||||||
"jest": "27.4.7"
|
"pngjs": "^7.0.0"
|
||||||
},
|
},
|
||||||
"engines": {
|
"engines": {
|
||||||
"node": ">=14.16.0",
|
"node": ">=16.15.0",
|
||||||
"npm": ">=6.14.0"
|
"npm": ">=8.5.5"
|
||||||
}
|
}
|
||||||
}
|
}
|
||||||
|
|||||||
@ -1,7 +1,7 @@
|
|||||||
# Breadth-First Search (BFS)
|
# Breadth-First Search (BFS)
|
||||||
|
|
||||||
Breadth-first search (BFS) is an algorithm for traversing
|
Breadth-first search (BFS) is an algorithm for traversing,
|
||||||
or searching tree or graph data structures. It starts at
|
searching tree, or graph data structures. It starts at
|
||||||
the tree root (or some arbitrary node of a graph, sometimes
|
the tree root (or some arbitrary node of a graph, sometimes
|
||||||
referred to as a 'search key') and explores the neighbor
|
referred to as a 'search key') and explores the neighbor
|
||||||
nodes first, before moving to the next level neighbors.
|
nodes first, before moving to the next level neighbors.
|
||||||
|
|||||||
@ -0,0 +1,85 @@
|
|||||||
|
import fs from 'fs';
|
||||||
|
import { PNG } from 'pngjs';
|
||||||
|
|
||||||
|
import resizeImageWidth from '../resizeImageWidth';
|
||||||
|
|
||||||
|
const testImageBeforePath = './src/algorithms/image-processing/seam-carving/__tests__/test-image-before.png';
|
||||||
|
const testImageAfterPath = './src/algorithms/image-processing/seam-carving/__tests__/test-image-after.png';
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Compares two images and finds the number of different pixels.
|
||||||
|
*
|
||||||
|
* @param {ImageData} imgA - ImageData for the first image.
|
||||||
|
* @param {ImageData} imgB - ImageData for the second image.
|
||||||
|
* @param {number} threshold - Color difference threshold [0..255]. Smaller - stricter.
|
||||||
|
* @returns {number} - Number of different pixels.
|
||||||
|
*/
|
||||||
|
function pixelsDiff(imgA, imgB, threshold = 0) {
|
||||||
|
if (imgA.width !== imgB.width || imgA.height !== imgB.height) {
|
||||||
|
throw new Error('Images must have the same size');
|
||||||
|
}
|
||||||
|
|
||||||
|
let differentPixels = 0;
|
||||||
|
const numColorParams = 4; // RGBA
|
||||||
|
|
||||||
|
for (let pixelIndex = 0; pixelIndex < imgA.data.length; pixelIndex += numColorParams) {
|
||||||
|
// Get pixel's color for each image.
|
||||||
|
const [aR, aG, aB] = imgA.data.subarray(pixelIndex, pixelIndex + numColorParams);
|
||||||
|
const [bR, bG, bB] = imgB.data.subarray(pixelIndex, pixelIndex + numColorParams);
|
||||||
|
|
||||||
|
// Get average pixel's color for each image (make them greyscale).
|
||||||
|
const aAvgColor = Math.floor((aR + aG + aB) / 3);
|
||||||
|
const bAvgColor = Math.floor((bR + bG + bB) / 3);
|
||||||
|
|
||||||
|
// Compare pixel colors.
|
||||||
|
if (Math.abs(aAvgColor - bAvgColor) > threshold) {
|
||||||
|
differentPixels += 1;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return differentPixels;
|
||||||
|
}
|
||||||
|
|
||||||
|
const pngLoad = (path) => new Promise((resolve) => {
|
||||||
|
fs.createReadStream(path)
|
||||||
|
.pipe(new PNG())
|
||||||
|
.on('parsed', function Parsed() {
|
||||||
|
/** @type {ImageData} */
|
||||||
|
const imageData = {
|
||||||
|
colorSpace: 'srgb',
|
||||||
|
width: this.width,
|
||||||
|
height: this.height,
|
||||||
|
data: this.data,
|
||||||
|
};
|
||||||
|
resolve(imageData);
|
||||||
|
});
|
||||||
|
});
|
||||||
|
|
||||||
|
describe('resizeImageWidth', () => {
|
||||||
|
it('should perform content-aware image width reduction', async () => {
|
||||||
|
const imgBefore = await pngLoad(testImageBeforePath);
|
||||||
|
const imgAfter = await pngLoad(testImageAfterPath);
|
||||||
|
|
||||||
|
const toWidth = Math.floor(imgBefore.width / 2);
|
||||||
|
|
||||||
|
const {
|
||||||
|
img: imgResized,
|
||||||
|
size: resizedSize,
|
||||||
|
} = resizeImageWidth({ img: imgBefore, toWidth });
|
||||||
|
|
||||||
|
expect(imgResized).toBeDefined();
|
||||||
|
expect(resizedSize).toBeDefined();
|
||||||
|
|
||||||
|
expect(resizedSize).toEqual({ w: toWidth, h: imgBefore.height });
|
||||||
|
expect(imgResized.width).toBe(imgAfter.width);
|
||||||
|
expect(imgResized.height).toBe(imgAfter.height);
|
||||||
|
|
||||||
|
const colorThreshold = 50;
|
||||||
|
const differentPixels = pixelsDiff(imgResized, imgAfter, colorThreshold);
|
||||||
|
|
||||||
|
// Allow 10% of pixels to be different
|
||||||
|
const pixelsThreshold = Math.floor((imgAfter.width * imgAfter.height) / 10);
|
||||||
|
|
||||||
|
expect(differentPixels).toBeLessThanOrEqual(pixelsThreshold);
|
||||||
|
});
|
||||||
|
});
|
||||||
@ -1,91 +0,0 @@
|
|||||||
import { createCanvas, loadImage } from 'canvas';
|
|
||||||
import resizeImageWidth from '../resizeImageWidth';
|
|
||||||
|
|
||||||
const testImageBeforePath = './src/algorithms/image-processing/seam-carving/__tests__/test-image-before.jpg';
|
|
||||||
const testImageAfterPath = './src/algorithms/image-processing/seam-carving/__tests__/test-image-after.jpg';
|
|
||||||
|
|
||||||
/**
|
|
||||||
* Compares two images and finds the number of different pixels.
|
|
||||||
*
|
|
||||||
* @param {ImageData} imgA - ImageData for the first image.
|
|
||||||
* @param {ImageData} imgB - ImageData for the second image.
|
|
||||||
* @param {number} threshold - Color difference threshold [0..255]. Smaller - stricter.
|
|
||||||
* @returns {number} - Number of different pixels.
|
|
||||||
*/
|
|
||||||
function pixelsDiff(imgA, imgB, threshold = 0) {
|
|
||||||
if (imgA.width !== imgB.width || imgA.height !== imgB.height) {
|
|
||||||
throw new Error('Images must have the same size');
|
|
||||||
}
|
|
||||||
|
|
||||||
let differentPixels = 0;
|
|
||||||
const numColorParams = 4; // RGBA
|
|
||||||
|
|
||||||
for (let pixelIndex = 0; pixelIndex < imgA.data.length; pixelIndex += numColorParams) {
|
|
||||||
// Get pixel's color for each image.
|
|
||||||
const [aR, aG, aB] = imgA.data.subarray(pixelIndex, pixelIndex + numColorParams);
|
|
||||||
const [bR, bG, bB] = imgB.data.subarray(pixelIndex, pixelIndex + numColorParams);
|
|
||||||
|
|
||||||
// Get average pixel's color for each image (make them greyscale).
|
|
||||||
const aAvgColor = Math.floor((aR + aG + aB) / 3);
|
|
||||||
const bAvgColor = Math.floor((bR + bG + bB) / 3);
|
|
||||||
|
|
||||||
// Compare pixel colors.
|
|
||||||
if (Math.abs(aAvgColor - bAvgColor) > threshold) {
|
|
||||||
differentPixels += 1;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
return differentPixels;
|
|
||||||
}
|
|
||||||
|
|
||||||
describe('resizeImageWidth', () => {
|
|
||||||
it('should perform content-aware image width reduction', () => {
|
|
||||||
// @see: https://jestjs.io/docs/asynchronous
|
|
||||||
return Promise.all([
|
|
||||||
loadImage(testImageBeforePath),
|
|
||||||
loadImage(testImageAfterPath),
|
|
||||||
]).then(([imgBefore, imgAfter]) => {
|
|
||||||
// Original image.
|
|
||||||
const canvasBefore = createCanvas(imgBefore.width, imgBefore.height);
|
|
||||||
const ctxBefore = canvasBefore.getContext('2d');
|
|
||||||
ctxBefore.drawImage(imgBefore, 0, 0, imgBefore.width, imgBefore.height);
|
|
||||||
const imgDataBefore = ctxBefore.getImageData(0, 0, imgBefore.width, imgBefore.height);
|
|
||||||
|
|
||||||
// Resized image saved.
|
|
||||||
const canvasAfter = createCanvas(imgAfter.width, imgAfter.height);
|
|
||||||
const ctxAfter = canvasAfter.getContext('2d');
|
|
||||||
ctxAfter.drawImage(imgAfter, 0, 0, imgAfter.width, imgAfter.height);
|
|
||||||
const imgDataAfter = ctxAfter.getImageData(0, 0, imgAfter.width, imgAfter.height);
|
|
||||||
|
|
||||||
const toWidth = Math.floor(imgBefore.width / 2);
|
|
||||||
|
|
||||||
const {
|
|
||||||
img: resizedImg,
|
|
||||||
size: resizedSize,
|
|
||||||
} = resizeImageWidth({ img: imgDataBefore, toWidth });
|
|
||||||
|
|
||||||
expect(resizedImg).toBeDefined();
|
|
||||||
expect(resizedSize).toBeDefined();
|
|
||||||
|
|
||||||
// Resized image generated.
|
|
||||||
const canvasTest = createCanvas(resizedSize.w, resizedSize.h);
|
|
||||||
const ctxTest = canvasTest.getContext('2d');
|
|
||||||
ctxTest.putImageData(resizedImg, 0, 0, 0, 0, resizedSize.w, resizedSize.h);
|
|
||||||
const imgDataTest = ctxTest.getImageData(0, 0, resizedSize.w, resizedSize.h);
|
|
||||||
|
|
||||||
expect(resizedSize).toEqual({ w: toWidth, h: imgBefore.height });
|
|
||||||
expect(imgDataTest.width).toBe(toWidth);
|
|
||||||
expect(imgDataTest.height).toBe(imgBefore.height);
|
|
||||||
expect(imgDataTest.width).toBe(imgAfter.width);
|
|
||||||
expect(imgDataTest.height).toBe(imgAfter.height);
|
|
||||||
|
|
||||||
const colorThreshold = 50;
|
|
||||||
const differentPixels = pixelsDiff(imgDataTest, imgDataAfter, colorThreshold);
|
|
||||||
|
|
||||||
// Allow 10% of pixels to be different
|
|
||||||
const pixelsThreshold = Math.floor((imgAfter.width * imgAfter.height) / 10);
|
|
||||||
|
|
||||||
expect(differentPixels).toBeLessThanOrEqual(pixelsThreshold);
|
|
||||||
});
|
|
||||||
});
|
|
||||||
});
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 5.9 KiB |
{kind=link}
|
After Width: | Height: | Size: 6.6 KiB |
{kind=link}
|
Before Width: | Height: | Size: 3.3 KiB |
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
@ -1,7 +1,7 @@
|
|||||||
# Factorial
|
# Factorial
|
||||||
|
|
||||||
_Read this in other languages:_
|
_Read this in other languages:_
|
||||||
[_简体中文_](README.zh-CN.md), [français](README.fr-FR.md), [turkish](README.tr-TR.md), [ქართული](README.ka-GE.md).
|
[_简体中文_](README.zh-CN.md), [_Français_](README.fr-FR.md), [_Türkçe_](README.tr-TR.md), [_ქართული_](README.ka-GE.md), [_Українська_](README.uk-UA.md).
|
||||||
|
|
||||||
In mathematics, the factorial of a non-negative integer `n`,
|
In mathematics, the factorial of a non-negative integer `n`,
|
||||||
denoted by `n!`, is the product of all positive integers less
|
denoted by `n!`, is the product of all positive integers less
|
||||||
|
|||||||
33
src/algorithms/math/factorial/README.uk-UA.md
Normal file
@ -0,0 +1,33 @@
|
|||||||
|
# Факторіал
|
||||||
|
|
||||||
|
_Прочитайте це іншими мовами:_
|
||||||
|
[_English_](README.md), [_简体中文_](README.zh-CN.md), [_Français_](README.fr-FR.md), [_Türkçe_](README.tr-TR.md), [_ქართული_](README.ka-GE.md).
|
||||||
|
|
||||||
|
У математиці факторіал невід'ємного цілого числа `n`, позначений `n!`, є добутком усіх натуральних чисел, менших або рівних `n`. Наприклад:
|
||||||
|
|
||||||
|
```
|
||||||
|
5! = 5 * 4 * 3 * 2 * 1 = 120
|
||||||
|
```
|
||||||
|
|
||||||
|
| n | n! |
|
||||||
|
| --- | ----------------: |
|
||||||
|
| 0 | 1 |
|
||||||
|
| 1 | 1 |
|
||||||
|
| 2 | 2 |
|
||||||
|
| 3 | 6 |
|
||||||
|
| 4 | 24 |
|
||||||
|
| 5 | 120 |
|
||||||
|
| 6 | 720 |
|
||||||
|
| 7 | 5 040 |
|
||||||
|
| 8 | 40 320 |
|
||||||
|
| 9 | 362 880 |
|
||||||
|
| 10 | 3 628 800 |
|
||||||
|
| 11 | 39 916 800 |
|
||||||
|
| 12 | 479 001 600 |
|
||||||
|
| 13 | 6 227 020 800 |
|
||||||
|
| 14 | 87 178 291 200 |
|
||||||
|
| 15 | 1 307 674 368 000 |
|
||||||
|
|
||||||
|
## Посилання
|
||||||
|
|
||||||
|
[Wikipedia](https://uk.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BA%D1%82%D0%BE%D1%80%D1%96%D0%B0%D0%BB)
|
||||||
@ -30,6 +30,11 @@ _Image source: [Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering)_
|
|||||||
|
|
||||||
The centroids are moving continuously in order to create better distinction between the different set of data points. As we can see, after a few iterations, the difference in centroids is quite low between iterations. For example between iterations `13` and `14` the difference is quite small because there the optimizer is tuning boundary cases.
|
The centroids are moving continuously in order to create better distinction between the different set of data points. As we can see, after a few iterations, the difference in centroids is quite low between iterations. For example between iterations `13` and `14` the difference is quite small because there the optimizer is tuning boundary cases.
|
||||||
|
|
||||||
|
## Code Examples
|
||||||
|
|
||||||
|
- [kMeans.js](./kMeans.js)
|
||||||
|
- [kMeans.test.js](./__test__/kMeans.test.js) (test cases)
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
- [k-Means neighbors algorithm on Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering)
|
- [k-Means neighbors algorithm on Wikipedia](https://en.wikipedia.org/wiki/K-means_clustering)
|
||||||
|
|||||||
@ -11,7 +11,7 @@ import Comparator from '../../../utils/comparator/Comparator';
|
|||||||
|
|
||||||
export default function binarySearch(sortedArray, seekElement, comparatorCallback) {
|
export default function binarySearch(sortedArray, seekElement, comparatorCallback) {
|
||||||
// Let's create comparator from the comparatorCallback function.
|
// Let's create comparator from the comparatorCallback function.
|
||||||
// Comparator object will give us common comparison methods like equal() and lessThen().
|
// Comparator object will give us common comparison methods like equal() and lessThan().
|
||||||
const comparator = new Comparator(comparatorCallback);
|
const comparator = new Comparator(comparatorCallback);
|
||||||
|
|
||||||
// These two indices will contain current array (sub-array) boundaries.
|
// These two indices will contain current array (sub-array) boundaries.
|
||||||
|
|||||||
@ -5,14 +5,14 @@ When the order doesn't matter, it is a **Combination**.
|
|||||||
When the order **does** matter it is a **Permutation**.
|
When the order **does** matter it is a **Permutation**.
|
||||||
|
|
||||||
**"My fruit salad is a combination of apples, grapes and bananas"**
|
**"My fruit salad is a combination of apples, grapes and bananas"**
|
||||||
We don't care what order the fruits are in, they could also be
|
We don't care what order the fruits are in, they could also be
|
||||||
"bananas, grapes and apples" or "grapes, apples and bananas",
|
"bananas, grapes and apples" or "grapes, apples and bananas",
|
||||||
its the same fruit salad.
|
its the same fruit salad.
|
||||||
|
|
||||||
## Combinations without repetitions
|
## Combinations without repetitions
|
||||||
|
|
||||||
This is how lotteries work. The numbers are drawn one at a
|
This is how lotteries work. The numbers are drawn one at a
|
||||||
time, and if we have the lucky numbers (no matter what order)
|
time, and if we have the lucky numbers (no matter what order)
|
||||||
we win!
|
we win!
|
||||||
|
|
||||||
No Repetition: such as lottery numbers `(2,14,15,27,30,33)`
|
No Repetition: such as lottery numbers `(2,14,15,27,30,33)`
|
||||||
@ -30,12 +30,12 @@ It is often called "n choose r" (such as "16 choose 3"). And is also known as th
|
|||||||
|
|
||||||
Repetition is Allowed: such as coins in your pocket `(5,5,5,10,10)`
|
Repetition is Allowed: such as coins in your pocket `(5,5,5,10,10)`
|
||||||
|
|
||||||
Or let us say there are five flavours of ice cream:
|
Or let us say there are five flavours of ice cream:
|
||||||
`banana`, `chocolate`, `lemon`, `strawberry` and `vanilla`.
|
`banana`, `chocolate`, `lemon`, `strawberry` and `vanilla`.
|
||||||
|
|
||||||
We can have three scoops. How many variations will there be?
|
We can have three scoops. How many variations will there be?
|
||||||
|
|
||||||
Let's use letters for the flavours: `{b, c, l, s, v}`.
|
Let's use letters for the flavours: `{b, c, l, s, v}`.
|
||||||
Example selections include:
|
Example selections include:
|
||||||
|
|
||||||
- `{c, c, c}` (3 scoops of chocolate)
|
- `{c, c, c}` (3 scoops of chocolate)
|
||||||
@ -46,23 +46,21 @@ Example selections include:
|
|||||||
|
|
||||||
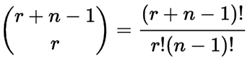
|
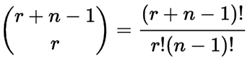
|
||||||
|
|
||||||
Where `n` is the number of things to choose from, and we
|
Where `n` is the number of things to choose from, and we
|
||||||
choose `r` of them. Repetition allowed,
|
choose `r` of them. Repetition allowed,
|
||||||
order doesn't matter.
|
order doesn't matter.
|
||||||
|
|
||||||
## Cheat Sheets
|
## Cheatsheet
|
||||||
|
|
||||||
Permutations cheat sheet
|

|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Combinations cheat sheet
|
| | |
|
||||||
|
| --- | --- |
|
||||||
|
| |  |
|
||||||
|
|
||||||

|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
Permutations/combinations algorithm ideas.
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
After Width: | Height: | Size: 345 KiB |
{kind=link}
|
After Width: | Height: | Size: 324 KiB |
{kind=link}
|
After Width: | Height: | Size: 302 KiB |
BIN
src/algorithms/sets/combinations/images/overview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
@ -0,0 +1,17 @@
|
|||||||
|
import longestCommonSubsequence from '../longestCommonSubsequenceRecursive';
|
||||||
|
|
||||||
|
describe('longestCommonSubsequenceRecursive', () => {
|
||||||
|
it('should find longest common substring between two strings', () => {
|
||||||
|
expect(longestCommonSubsequence('', '')).toBe('');
|
||||||
|
expect(longestCommonSubsequence('ABC', '')).toBe('');
|
||||||
|
expect(longestCommonSubsequence('', 'ABC')).toBe('');
|
||||||
|
expect(longestCommonSubsequence('ABABC', 'BABCA')).toBe('BABC');
|
||||||
|
expect(longestCommonSubsequence('BABCA', 'ABCBA')).toBe('ABCA');
|
||||||
|
expect(longestCommonSubsequence('sea', 'eat')).toBe('ea');
|
||||||
|
expect(longestCommonSubsequence('algorithms', 'rithm')).toBe('rithm');
|
||||||
|
expect(longestCommonSubsequence(
|
||||||
|
'Algorithms and data structures implemented in JavaScript',
|
||||||
|
'Here you may find Algorithms and data structures that are implemented in JavaScript',
|
||||||
|
)).toBe('Algorithms and data structures implemented in JavaScript');
|
||||||
|
});
|
||||||
|
});
|
||||||
@ -0,0 +1,36 @@
|
|||||||
|
/* eslint-disable no-param-reassign */
|
||||||
|
/**
|
||||||
|
* Longest Common Subsequence (LCS) (Recursive Approach).
|
||||||
|
*
|
||||||
|
* @param {string} string1
|
||||||
|
* @param {string} string2
|
||||||
|
* @return {number}
|
||||||
|
*/
|
||||||
|
export default function longestCommonSubsequenceRecursive(string1, string2) {
|
||||||
|
/**
|
||||||
|
*
|
||||||
|
* @param {string} s1
|
||||||
|
* @param {string} s2
|
||||||
|
* @return {string} - returns the LCS (Longest Common Subsequence)
|
||||||
|
*/
|
||||||
|
const lcs = (s1, s2, memo = {}) => {
|
||||||
|
if (!s1 || !s2) return '';
|
||||||
|
|
||||||
|
if (memo[`${s1}:${s2}`]) return memo[`${s1}:${s2}`];
|
||||||
|
|
||||||
|
if (s1[0] === s2[0]) {
|
||||||
|
return s1[0] + lcs(s1.substring(1), s2.substring(1), memo);
|
||||||
|
}
|
||||||
|
|
||||||
|
const nextLcs1 = lcs(s1.substring(1), s2, memo);
|
||||||
|
const nextLcs2 = lcs(s1, s2.substring(1), memo);
|
||||||
|
|
||||||
|
const nextLongest = nextLcs1.length >= nextLcs2.length ? nextLcs1 : nextLcs2;
|
||||||
|
|
||||||
|
memo[`${s1}:${s2}`] = nextLongest;
|
||||||
|
|
||||||
|
return nextLongest;
|
||||||
|
};
|
||||||
|
|
||||||
|
return lcs(string1, string2);
|
||||||
|
}
|
||||||
@ -4,13 +4,13 @@ When the order doesn't matter, it is a **Combination**.
|
|||||||
|
|
||||||
When the order **does** matter it is a **Permutation**.
|
When the order **does** matter it is a **Permutation**.
|
||||||
|
|
||||||
**"The combination to the safe is 472"**. We do care about the order. `724` won't work, nor will `247`.
|
**"The combination to the safe is 472"**. We do care about the order. `724` won't work, nor will `247`.
|
||||||
It has to be exactly `4-7-2`.
|
It has to be exactly `4-7-2`.
|
||||||
|
|
||||||
## Permutations without repetitions
|
## Permutations without repetitions
|
||||||
|
|
||||||
A permutation, also called an “arrangement number” or “order”, is a rearrangement of
|
A permutation, also called an “arrangement number” or “order”, is a rearrangement of
|
||||||
the elements of an ordered list `S` into a one-to-one correspondence with `S` itself.
|
the elements of an ordered list `S` into a one-to-one correspondence with `S` itself.
|
||||||
|
|
||||||
Below are the permutations of string `ABC`.
|
Below are the permutations of string `ABC`.
|
||||||
|
|
||||||
@ -37,19 +37,17 @@ For example the the lock below: it could be `333`.
|
|||||||
n * n * n ... (r times) = n^r
|
n * n * n ... (r times) = n^r
|
||||||
```
|
```
|
||||||
|
|
||||||
## Cheat Sheets
|
## Cheatsheet
|
||||||
|
|
||||||
Permutations cheat sheet
|

|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
Combinations cheat sheet
|
| | |
|
||||||
|
| --- | --- |
|
||||||
|
| |  |
|
||||||
|
|
||||||

|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
Permutations/combinations algorithm ideas.
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
|
|||||||
BIN
src/algorithms/sets/permutations/images/overview.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
{kind=link}
|
After Width: | Height: | Size: 307 KiB |
{kind=link}
|
After Width: | Height: | Size: 301 KiB |
{kind=link}
|
After Width: | Height: | Size: 364 KiB |
@ -1,7 +1,7 @@
|
|||||||
# Power Set
|
# Power Set
|
||||||
|
|
||||||
Power set of a set `S` is the set of all of the subsets of `S`, including the
|
Power set of a set `S` is the set of all of the subsets of `S`, including the
|
||||||
empty set and `S` itself. Power set of set `S` is denoted as `P(S)`.
|
empty set and `S` itself. Power set of set `S` is denoted as `P(S)`.
|
||||||
|
|
||||||
For example for `{x, y, z}`, the subsets
|
For example for `{x, y, z}`, the subsets
|
||||||
are:
|
are:
|
||||||
@ -21,37 +21,37 @@ are:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
Here is how we may illustrate the elements of the power set of the set `{x, y, z}` ordered with respect to
|
Here is how we may illustrate the elements of the power set of the set `{x, y, z}` ordered with respect to
|
||||||
inclusion:
|
inclusion:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**Number of Subsets**
|
**Number of Subsets**
|
||||||
|
|
||||||
If `S` is a finite set with `|S| = n` elements, then the number of subsets
|
If `S` is a finite set with `|S| = n` elements, then the number of subsets
|
||||||
of `S` is `|P(S)| = 2^n`. This fact, which is the motivation for the
|
of `S` is `|P(S)| = 2^n`. This fact, which is the motivation for the
|
||||||
notation `2^S`, may be demonstrated simply as follows:
|
notation `2^S`, may be demonstrated simply as follows:
|
||||||
|
|
||||||
> First, order the elements of `S` in any manner. We write any subset of `S` in
|
> First, order the elements of `S` in any manner. We write any subset of `S` in
|
||||||
the format `{γ1, γ2, ..., γn}` where `γi , 1 ≤ i ≤ n`, can take the value
|
the format `{γ1, γ2, ..., γn}` where `γi , 1 ≤ i ≤ n`, can take the value
|
||||||
of `0` or `1`. If `γi = 1`, the `i`-th element of `S` is in the subset;
|
of `0` or `1`. If `γi = 1`, the `i`-th element of `S` is in the subset;
|
||||||
otherwise, the `i`-th element is not in the subset. Clearly the number of
|
otherwise, the `i`-th element is not in the subset. Clearly the number of
|
||||||
distinct subsets that can be constructed this way is `2^n` as `γi ∈ {0, 1}`.
|
distinct subsets that can be constructed this way is `2^n` as `γi ∈ {0, 1}`.
|
||||||
|
|
||||||
## Algorithms
|
## Algorithms
|
||||||
|
|
||||||
### Bitwise Solution
|
### Bitwise Solution
|
||||||
|
|
||||||
Each number in binary representation in a range from `0` to `2^n` does exactly
|
Each number in binary representation in a range from `0` to `2^n` does exactly
|
||||||
what we need: it shows by its bits (`0` or `1`) whether to include related
|
what we need: it shows by its bits (`0` or `1`) whether to include related
|
||||||
element from the set or not. For example, for the set `{1, 2, 3}` the binary
|
element from the set or not. For example, for the set `{1, 2, 3}` the binary
|
||||||
number of `0b010` would mean that we need to include only `2` to the current set.
|
number of `0b010` would mean that we need to include only `2` to the current set.
|
||||||
|
|
||||||
| | `abc` | Subset |
|
| | `abc` | Subset |
|
||||||
| :---: | :---: | :-----------: |
|
| :---: | :---: | :-----------: |
|
||||||
| `0` | `000` | `{}` |
|
| `0` | `000` | `{}` |
|
||||||
| `1` | `001` | `{c}` |
|
| `1` | `001` | `{c}` |
|
||||||
| `2` | `010` | `{b}` |
|
| `2` | `010` | `{b}` |
|
||||||
| `3` | `011` | `{c, b}` |
|
| `3` | `011` | `{c, b}` |
|
||||||
| `4` | `100` | `{a}` |
|
| `4` | `100` | `{a}` |
|
||||||
| `5` | `101` | `{a, c}` |
|
| `5` | `101` | `{a, c}` |
|
||||||
@ -68,6 +68,44 @@ element.
|
|||||||
|
|
||||||
> See [btPowerSet.js](./btPowerSet.js) file for backtracking solution.
|
> See [btPowerSet.js](./btPowerSet.js) file for backtracking solution.
|
||||||
|
|
||||||
|
### Cascading Solution
|
||||||
|
|
||||||
|
This is, arguably, the simplest solution to generate a Power Set.
|
||||||
|
|
||||||
|
We start with an empty set:
|
||||||
|
|
||||||
|
```text
|
||||||
|
powerSets = [[]]
|
||||||
|
```
|
||||||
|
|
||||||
|
Now, let's say:
|
||||||
|
|
||||||
|
```text
|
||||||
|
originalSet = [1, 2, 3]
|
||||||
|
```
|
||||||
|
|
||||||
|
Let's add the 1st element from the originalSet to all existing sets:
|
||||||
|
|
||||||
|
```text
|
||||||
|
[[]] ← 1 = [[], [1]]
|
||||||
|
```
|
||||||
|
|
||||||
|
Adding the 2nd element to all existing sets:
|
||||||
|
|
||||||
|
```text
|
||||||
|
[[], [1]] ← 2 = [[], [1], [2], [1, 2]]
|
||||||
|
```
|
||||||
|
|
||||||
|
Adding the 3nd element to all existing sets:
|
||||||
|
|
||||||
|
```
|
||||||
|
[[], [1], [2], [1, 2]] ← 3 = [[], [1], [2], [1, 2], [3], [1, 3], [2, 3], [1, 2, 3]]
|
||||||
|
```
|
||||||
|
|
||||||
|
And so on, for the rest of the elements from the `originalSet`. On every iteration the number of sets is doubled, so we'll get `2^n` sets.
|
||||||
|
|
||||||
|
> See [caPowerSet.js](./caPowerSet.js) file for cascading solution.
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
* [Wikipedia](https://en.wikipedia.org/wiki/Power_set)
|
* [Wikipedia](https://en.wikipedia.org/wiki/Power_set)
|
||||||
|
|||||||
28
src/algorithms/sets/power-set/__test__/caPowerSet.test.js
Normal file
@ -0,0 +1,28 @@
|
|||||||
|
import caPowerSet from '../caPowerSet';
|
||||||
|
|
||||||
|
describe('caPowerSet', () => {
|
||||||
|
it('should calculate power set of given set using cascading approach', () => {
|
||||||
|
expect(caPowerSet([1])).toEqual([
|
||||||
|
[],
|
||||||
|
[1],
|
||||||
|
]);
|
||||||
|
|
||||||
|
expect(caPowerSet([1, 2])).toEqual([
|
||||||
|
[],
|
||||||
|
[1],
|
||||||
|
[2],
|
||||||
|
[1, 2],
|
||||||
|
]);
|
||||||
|
|
||||||
|
expect(caPowerSet([1, 2, 3])).toEqual([
|
||||||
|
[],
|
||||||
|
[1],
|
||||||
|
[2],
|
||||||
|
[1, 2],
|
||||||
|
[3],
|
||||||
|
[1, 3],
|
||||||
|
[2, 3],
|
||||||
|
[1, 2, 3],
|
||||||
|
]);
|
||||||
|
});
|
||||||
|
});
|
||||||
37
src/algorithms/sets/power-set/caPowerSet.js
Normal file
@ -0,0 +1,37 @@
|
|||||||
|
/**
|
||||||
|
* Find power-set of a set using CASCADING approach.
|
||||||
|
*
|
||||||
|
* @param {*[]} originalSet
|
||||||
|
* @return {*[][]}
|
||||||
|
*/
|
||||||
|
export default function caPowerSet(originalSet) {
|
||||||
|
// Let's start with an empty set.
|
||||||
|
const sets = [[]];
|
||||||
|
|
||||||
|
/*
|
||||||
|
Now, let's say:
|
||||||
|
originalSet = [1, 2, 3].
|
||||||
|
|
||||||
|
Let's add the first element from the originalSet to all existing sets:
|
||||||
|
[[]] ← 1 = [[], [1]]
|
||||||
|
|
||||||
|
Adding the 2nd element to all existing sets:
|
||||||
|
[[], [1]] ← 2 = [[], [1], [2], [1, 2]]
|
||||||
|
|
||||||
|
Adding the 3nd element to all existing sets:
|
||||||
|
[[], [1], [2], [1, 2]] ← 3 = [[], [1], [2], [1, 2], [3], [1, 3], [2, 3], [1, 2, 3]]
|
||||||
|
|
||||||
|
And so on for the rest of the elements from originalSet.
|
||||||
|
On every iteration the number of sets is doubled, so we'll get 2^n sets.
|
||||||
|
*/
|
||||||
|
for (let numIdx = 0; numIdx < originalSet.length; numIdx += 1) {
|
||||||
|
const existingSetsNum = sets.length;
|
||||||
|
|
||||||
|
for (let setIdx = 0; setIdx < existingSetsNum; setIdx += 1) {
|
||||||
|
const set = [...sets[setIdx], originalSet[numIdx]];
|
||||||
|
sets.push(set);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return sets;
|
||||||
|
}
|
||||||
46
src/algorithms/sorting/bucket-sort/BucketSort.js
Normal file
@ -0,0 +1,46 @@
|
|||||||
|
import RadixSort from '../radix-sort/RadixSort';
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Bucket Sort
|
||||||
|
*
|
||||||
|
* @param {number[]} arr
|
||||||
|
* @param {number} bucketsNum
|
||||||
|
* @return {number[]}
|
||||||
|
*/
|
||||||
|
export default function BucketSort(arr, bucketsNum = 1) {
|
||||||
|
const buckets = new Array(bucketsNum).fill(null).map(() => []);
|
||||||
|
|
||||||
|
const minValue = Math.min(...arr);
|
||||||
|
const maxValue = Math.max(...arr);
|
||||||
|
|
||||||
|
const bucketSize = Math.ceil(Math.max(1, (maxValue - minValue) / bucketsNum));
|
||||||
|
|
||||||
|
// Place elements into buckets.
|
||||||
|
for (let i = 0; i < arr.length; i += 1) {
|
||||||
|
const currValue = arr[i];
|
||||||
|
const bucketIndex = Math.floor((currValue - minValue) / bucketSize);
|
||||||
|
|
||||||
|
// Edge case for max value.
|
||||||
|
if (bucketIndex === bucketsNum) {
|
||||||
|
buckets[bucketsNum - 1].push(currValue);
|
||||||
|
} else {
|
||||||
|
buckets[bucketIndex].push(currValue);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Sort individual buckets.
|
||||||
|
for (let i = 0; i < buckets.length; i += 1) {
|
||||||
|
// Let's use the Radix Sorter here. This may give us
|
||||||
|
// the average O(n + k) time complexity to sort one bucket
|
||||||
|
// (where k is a number of digits in the longest number).
|
||||||
|
buckets[i] = new RadixSort().sort(buckets[i]);
|
||||||
|
}
|
||||||
|
|
||||||
|
// Merge sorted buckets into final output.
|
||||||
|
const sortedArr = [];
|
||||||
|
for (let i = 0; i < buckets.length; i += 1) {
|
||||||
|
sortedArr.push(...buckets[i]);
|
||||||
|
}
|
||||||
|
|
||||||
|
return sortedArr;
|
||||||
|
}
|
||||||
35
src/algorithms/sorting/bucket-sort/README.md
Normal file
@ -0,0 +1,35 @@
|
|||||||
|
# Bucket Sort
|
||||||
|
|
||||||
|
**Bucket sort**, or **bin sort**, is a sorting algorithm that works by distributing the elements of an array into a number of buckets. Each bucket is then sorted individually, either using a different sorting algorithm, or by recursively applying the bucket sorting algorithm.
|
||||||
|
|
||||||
|
## Algorithm
|
||||||
|
|
||||||
|
Bucket sort works as follows:
|
||||||
|
|
||||||
|
1. Set up an array of initially empty `buckets`.
|
||||||
|
2. **Scatter:** Go over the original array, putting each object in its `bucket`.
|
||||||
|
3. Sort each non-empty `bucket`.
|
||||||
|
4. **Gather:** Visit the `buckets` in order and put all elements back into the original array.
|
||||||
|
|
||||||
|
Elements are distributed among bins:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Then, elements are sorted within each bin:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
|
## Complexity
|
||||||
|
|
||||||
|
The computational complexity depends on the algorithm used to sort each bucket, the number of buckets to use, and whether the input is uniformly distributed.
|
||||||
|
|
||||||
|
The **worst-case** time complexity of bucket sort is
|
||||||
|
`O(n^2)` if the sorting algorithm used on the bucket is *insertion sort*, which is the most common use case since the expectation is that buckets will not have too many elements relative to the entire list. In the worst case, all elements are placed in one bucket, causing the running time to reduce to the worst-case complexity of insertion sort (all elements are in reverse order). If the worst-case running time of the intermediate sort used is `O(n * log(n))`, then the worst-case running time of bucket sort will also be
|
||||||
|
`O(n * log(n))`.
|
||||||
|
|
||||||
|
On **average**, when the distribution of elements across buckets is reasonably uniform, it can be shown that bucket sort runs on average `O(n + k)` for `k` buckets.
|
||||||
|
|
||||||
|
## References
|
||||||
|
|
||||||
|
- [Bucket Sort on Wikipedia](https://en.wikipedia.org/wiki/Bucket_sort)
|
||||||
@ -0,0 +1,33 @@
|
|||||||
|
import BucketSort from '../BucketSort';
|
||||||
|
import {
|
||||||
|
equalArr,
|
||||||
|
notSortedArr,
|
||||||
|
reverseArr,
|
||||||
|
sortedArr,
|
||||||
|
} from '../../SortTester';
|
||||||
|
|
||||||
|
describe('BucketSort', () => {
|
||||||
|
it('should sort the array of numbers with different buckets amounts', () => {
|
||||||
|
expect(BucketSort(notSortedArr, 4)).toEqual(sortedArr);
|
||||||
|
expect(BucketSort(equalArr, 4)).toEqual(equalArr);
|
||||||
|
expect(BucketSort(reverseArr, 4)).toEqual(sortedArr);
|
||||||
|
expect(BucketSort(sortedArr, 4)).toEqual(sortedArr);
|
||||||
|
|
||||||
|
expect(BucketSort(notSortedArr, 10)).toEqual(sortedArr);
|
||||||
|
expect(BucketSort(equalArr, 10)).toEqual(equalArr);
|
||||||
|
expect(BucketSort(reverseArr, 10)).toEqual(sortedArr);
|
||||||
|
expect(BucketSort(sortedArr, 10)).toEqual(sortedArr);
|
||||||
|
|
||||||
|
expect(BucketSort(notSortedArr, 50)).toEqual(sortedArr);
|
||||||
|
expect(BucketSort(equalArr, 50)).toEqual(equalArr);
|
||||||
|
expect(BucketSort(reverseArr, 50)).toEqual(sortedArr);
|
||||||
|
expect(BucketSort(sortedArr, 50)).toEqual(sortedArr);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should sort the array of numbers with the default buckets of 1', () => {
|
||||||
|
expect(BucketSort(notSortedArr)).toEqual(sortedArr);
|
||||||
|
expect(BucketSort(equalArr)).toEqual(equalArr);
|
||||||
|
expect(BucketSort(reverseArr)).toEqual(sortedArr);
|
||||||
|
expect(BucketSort(sortedArr)).toEqual(sortedArr);
|
||||||
|
});
|
||||||
|
});
|
||||||
BIN
src/algorithms/sorting/bucket-sort/images/bucket_sort_1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 11 KiB |
BIN
src/algorithms/sorting/bucket-sort/images/bucket_sort_2.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
@ -4,7 +4,7 @@ export default class QuickSortInPlace extends Sort {
|
|||||||
/** Sorting in place avoids unnecessary use of additional memory, but modifies input array.
|
/** Sorting in place avoids unnecessary use of additional memory, but modifies input array.
|
||||||
*
|
*
|
||||||
* This process is difficult to describe, but much clearer with a visualization:
|
* This process is difficult to describe, but much clearer with a visualization:
|
||||||
* @see: http://www.algomation.com/algorithm/quick-sort-visualization
|
* @see: https://www.hackerearth.com/practice/algorithms/sorting/quick-sort/visualize/
|
||||||
*
|
*
|
||||||
* @param {*[]} originalArray - Not sorted array.
|
* @param {*[]} originalArray - Not sorted array.
|
||||||
* @param {number} inputLowIndex
|
* @param {number} inputLowIndex
|
||||||
|
|||||||
@ -3,37 +3,37 @@
|
|||||||
_Read this in other languages:_
|
_Read this in other languages:_
|
||||||
[_Português_](README.pt-BR.md),
|
[_Português_](README.pt-BR.md),
|
||||||
|
|
||||||
In computer science, **radix sort** is a non-comparative integer sorting
|
In computer science, **radix sort** is a non-comparative integer sorting
|
||||||
algorithm that sorts data with integer keys by grouping keys by the individual
|
algorithm that sorts data with integer keys by grouping keys by the individual
|
||||||
digits which share the same significant position and value. A positional notation
|
digits which share the same significant position and value. A positional notation
|
||||||
is required, but because integers can represent strings of characters
|
is required, but because integers can represent strings of characters
|
||||||
(e.g., names or dates) and specially formatted floating point numbers, radix
|
(e.g., names or dates) and specially formatted floating point numbers, radix
|
||||||
sort is not limited to integers.
|
sort is not limited to integers.
|
||||||
|
|
||||||
*Where does the name come from?*
|
*Where does the name come from?*
|
||||||
|
|
||||||
In mathematical numeral systems, the *radix* or base is the number of unique digits,
|
In mathematical numeral systems, the *radix* or base is the number of unique digits,
|
||||||
including the digit zero, used to represent numbers in a positional numeral system.
|
including the digit zero, used to represent numbers in a positional numeral system.
|
||||||
For example, a binary system (using numbers 0 and 1) has a radix of 2 and a decimal
|
For example, a binary system (using numbers 0 and 1) has a radix of 2 and a decimal
|
||||||
system (using numbers 0 to 9) has a radix of 10.
|
system (using numbers 0 to 9) has a radix of 10.
|
||||||
|
|
||||||
## Efficiency
|
## Efficiency
|
||||||
|
|
||||||
The topic of the efficiency of radix sort compared to other sorting algorithms is
|
The topic of the efficiency of radix sort compared to other sorting algorithms is
|
||||||
somewhat tricky and subject to quite a lot of misunderstandings. Whether radix
|
somewhat tricky and subject to quite a lot of misunderstandings. Whether radix
|
||||||
sort is equally efficient, less efficient or more efficient than the best
|
sort is equally efficient, less efficient or more efficient than the best
|
||||||
comparison-based algorithms depends on the details of the assumptions made.
|
comparison-based algorithms depends on the details of the assumptions made.
|
||||||
Radix sort complexity is `O(wn)` for `n` keys which are integers of word size `w`.
|
Radix sort complexity is `O(wn)` for `n` keys which are integers of word size `w`.
|
||||||
Sometimes `w` is presented as a constant, which would make radix sort better
|
Sometimes `w` is presented as a constant, which would make radix sort better
|
||||||
(for sufficiently large `n`) than the best comparison-based sorting algorithms,
|
(for sufficiently large `n`) than the best comparison-based sorting algorithms,
|
||||||
which all perform `O(n log n)` comparisons to sort `n` keys. However, in
|
which all perform `O(n log n)` comparisons to sort `n` keys. However, in
|
||||||
general `w` cannot be considered a constant: if all `n` keys are distinct,
|
general `w` cannot be considered a constant: if all `n` keys are distinct,
|
||||||
then `w` has to be at least `log n` for a random-access machine to be able to
|
then `w` has to be at least `log n` for a random-access machine to be able to
|
||||||
store them in memory, which gives at best a time complexity `O(n log n)`. That
|
store them in memory, which gives at best a time complexity `O(n log n)`. That
|
||||||
would seem to make radix sort at most equally efficient as the best
|
would seem to make radix sort at most equally efficient as the best
|
||||||
comparison-based sorts (and worse if keys are much longer than `log n`).
|
comparison-based sorts (and worse if keys are much longer than `log n`).
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
## Complexity
|
## Complexity
|
||||||
|
|
||||||
|
|||||||
BIN
src/algorithms/sorting/radix-sort/images/radix-sort.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 12 KiB |
@ -7,6 +7,8 @@ describe('longestCommonSubstring', () => {
|
|||||||
expect(longestCommonSubstring('', 'ABC')).toBe('');
|
expect(longestCommonSubstring('', 'ABC')).toBe('');
|
||||||
expect(longestCommonSubstring('ABABC', 'BABCA')).toBe('BABC');
|
expect(longestCommonSubstring('ABABC', 'BABCA')).toBe('BABC');
|
||||||
expect(longestCommonSubstring('BABCA', 'ABCBA')).toBe('ABC');
|
expect(longestCommonSubstring('BABCA', 'ABCBA')).toBe('ABC');
|
||||||
|
expect(longestCommonSubstring('sea', 'eat')).toBe('ea');
|
||||||
|
expect(longestCommonSubstring('algorithms', 'rithm')).toBe('rithm');
|
||||||
expect(longestCommonSubstring(
|
expect(longestCommonSubstring(
|
||||||
'Algorithms and data structures implemented in JavaScript',
|
'Algorithms and data structures implemented in JavaScript',
|
||||||
'Here you may find Algorithms and data structures that are implemented in JavaScript',
|
'Here you may find Algorithms and data structures that are implemented in JavaScript',
|
||||||
|
|||||||
@ -1,4 +1,6 @@
|
|||||||
/**
|
/**
|
||||||
|
* Longest Common Substring (LCS) (Dynamic Programming Approach).
|
||||||
|
*
|
||||||
* @param {string} string1
|
* @param {string} string1
|
||||||
* @param {string} string2
|
* @param {string} string2
|
||||||
* @return {string}
|
* @return {string}
|
||||||
|
|||||||
@ -46,7 +46,7 @@ Let's say we have an array of prices `[7, 6, 4, 3, 1]` and we're on the _1st_ da
|
|||||||
1. _Option 1: Keep the money_ → profit would equal to the profit from buying/selling the rest of the stocks → `keepProfit = profit([6, 4, 3, 1])`.
|
1. _Option 1: Keep the money_ → profit would equal to the profit from buying/selling the rest of the stocks → `keepProfit = profit([6, 4, 3, 1])`.
|
||||||
2. _Option 2: Buy/sell at current price_ → profit in this case would equal to the profit from buying/selling the rest of the stocks plus (or minus, depending on whether we're selling or buying) the current stock price → `buySellProfit = -7 + profit([6, 4, 3, 1])`.
|
2. _Option 2: Buy/sell at current price_ → profit in this case would equal to the profit from buying/selling the rest of the stocks plus (or minus, depending on whether we're selling or buying) the current stock price → `buySellProfit = -7 + profit([6, 4, 3, 1])`.
|
||||||
|
|
||||||
The overall profit would be equal to → `overalProfit = Max(keepProfit, buySellProfit)`.
|
The overall profit would be equal to → `overallProfit = Max(keepProfit, buySellProfit)`.
|
||||||
|
|
||||||
As you can see the `profit([6, 4, 3, 1])` task is being solved in the same recursive manner.
|
As you can see the `profit([6, 4, 3, 1])` task is being solved in the same recursive manner.
|
||||||
|
|
||||||
|
|||||||
@ -59,7 +59,7 @@ and return false.
|
|||||||
queen here leads to a solution.
|
queen here leads to a solution.
|
||||||
b) If placing queen in [row, column] leads to a solution then return
|
b) If placing queen in [row, column] leads to a solution then return
|
||||||
true.
|
true.
|
||||||
c) If placing queen doesn't lead to a solution then umark this [row,
|
c) If placing queen doesn't lead to a solution then unmark this [row,
|
||||||
column] (Backtrack) and go to step (a) to try other rows.
|
column] (Backtrack) and go to step (a) to try other rows.
|
||||||
3) If all rows have been tried and nothing worked, return false to trigger
|
3) If all rows have been tried and nothing worked, return false to trigger
|
||||||
backtracking.
|
backtracking.
|
||||||
|
|||||||
@ -93,7 +93,7 @@ three factors: the size of the bloom filter, the
|
|||||||
number of hash functions we use, and the number
|
number of hash functions we use, and the number
|
||||||
of items that have been inserted into the filter.
|
of items that have been inserted into the filter.
|
||||||
|
|
||||||
The formula to calculate probablity of a false positive is:
|
The formula to calculate probability of a false positive is:
|
||||||
|
|
||||||
( 1 - e <sup>-kn/m</sup> ) <sup>k</sup>
|
( 1 - e <sup>-kn/m</sup> ) <sup>k</sup>
|
||||||
|
|
||||||
|
|||||||
78
src/data-structures/disjoint-set/DisjointSetAdhoc.js
Normal file
@ -0,0 +1,78 @@
|
|||||||
|
/**
|
||||||
|
* The minimalistic (ad hoc) version of a DisjointSet (or a UnionFind) data structure
|
||||||
|
* that doesn't have external dependencies and that is easy to copy-paste and
|
||||||
|
* use during the coding interview if allowed by the interviewer (since many
|
||||||
|
* data structures in JS are missing).
|
||||||
|
*
|
||||||
|
* Time Complexity:
|
||||||
|
*
|
||||||
|
* - Constructor: O(N)
|
||||||
|
* - Find: O(α(N))
|
||||||
|
* - Union: O(α(N))
|
||||||
|
* - Connected: O(α(N))
|
||||||
|
*
|
||||||
|
* Where N is the number of vertices in the graph.
|
||||||
|
* α refers to the Inverse Ackermann function.
|
||||||
|
* In practice, we assume it's a constant.
|
||||||
|
* In other words, O(α(N)) is regarded as O(1) on average.
|
||||||
|
*/
|
||||||
|
class DisjointSetAdhoc {
|
||||||
|
/**
|
||||||
|
* Initializes the set of specified size.
|
||||||
|
* @param {number} size
|
||||||
|
*/
|
||||||
|
constructor(size) {
|
||||||
|
// The index of a cell is an id of the node in a set.
|
||||||
|
// The value of a cell is an id (index) of the root node.
|
||||||
|
// By default, the node is a parent of itself.
|
||||||
|
this.roots = new Array(size).fill(0).map((_, i) => i);
|
||||||
|
|
||||||
|
// Using the heights array to record the height of each node.
|
||||||
|
// By default each node has a height of 1 because it has no children.
|
||||||
|
this.heights = new Array(size).fill(1);
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Finds the root of node `a`
|
||||||
|
* @param {number} a
|
||||||
|
* @returns {number}
|
||||||
|
*/
|
||||||
|
find(a) {
|
||||||
|
if (a === this.roots[a]) return a;
|
||||||
|
this.roots[a] = this.find(this.roots[a]);
|
||||||
|
return this.roots[a];
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Joins the `a` and `b` nodes into same set.
|
||||||
|
* @param {number} a
|
||||||
|
* @param {number} b
|
||||||
|
* @returns {number}
|
||||||
|
*/
|
||||||
|
union(a, b) {
|
||||||
|
const aRoot = this.find(a);
|
||||||
|
const bRoot = this.find(b);
|
||||||
|
|
||||||
|
if (aRoot === bRoot) return;
|
||||||
|
|
||||||
|
if (this.heights[aRoot] > this.heights[bRoot]) {
|
||||||
|
this.roots[bRoot] = aRoot;
|
||||||
|
} else if (this.heights[aRoot] < this.heights[bRoot]) {
|
||||||
|
this.roots[aRoot] = bRoot;
|
||||||
|
} else {
|
||||||
|
this.roots[bRoot] = aRoot;
|
||||||
|
this.heights[aRoot] += 1;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Checks if `a` and `b` belong to the same set.
|
||||||
|
* @param {number} a
|
||||||
|
* @param {number} b
|
||||||
|
*/
|
||||||
|
connected(a, b) {
|
||||||
|
return this.find(a) === this.find(b);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export default DisjointSetAdhoc;
|
||||||
@ -19,6 +19,11 @@ _MakeSet_ creates 8 singletons.
|
|||||||
|
|
||||||
After some operations of _Union_, some sets are grouped together.
|
After some operations of _Union_, some sets are grouped together.
|
||||||
|
|
||||||
|
## Implementation
|
||||||
|
|
||||||
|
- [DisjointSet.js](./DisjointSet.js)
|
||||||
|
- [DisjointSetAdhoc.js](./DisjointSetAdhoc.js) - The minimalistic (ad hoc) version of a DisjointSet (or a UnionFind) data structure that doesn't have external dependencies and that is easy to copy-paste and use during the coding interview if allowed by the interviewer (since many data structures in JS are missing).
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
- [Wikipedia](https://en.wikipedia.org/wiki/Disjoint-set_data_structure)
|
- [Wikipedia](https://en.wikipedia.org/wiki/Disjoint-set_data_structure)
|
||||||
|
|||||||
@ -0,0 +1,50 @@
|
|||||||
|
import DisjointSetAdhoc from '../DisjointSetAdhoc';
|
||||||
|
|
||||||
|
describe('DisjointSetAdhoc', () => {
|
||||||
|
it('should create unions and find connected elements', () => {
|
||||||
|
const set = new DisjointSetAdhoc(10);
|
||||||
|
|
||||||
|
// 1-2-5-6-7 3-8-9 4
|
||||||
|
set.union(1, 2);
|
||||||
|
set.union(2, 5);
|
||||||
|
set.union(5, 6);
|
||||||
|
set.union(6, 7);
|
||||||
|
|
||||||
|
set.union(3, 8);
|
||||||
|
set.union(8, 9);
|
||||||
|
|
||||||
|
expect(set.connected(1, 5)).toBe(true);
|
||||||
|
expect(set.connected(5, 7)).toBe(true);
|
||||||
|
expect(set.connected(3, 8)).toBe(true);
|
||||||
|
|
||||||
|
expect(set.connected(4, 9)).toBe(false);
|
||||||
|
expect(set.connected(4, 7)).toBe(false);
|
||||||
|
|
||||||
|
// 1-2-5-6-7 3-8-9-4
|
||||||
|
set.union(9, 4);
|
||||||
|
|
||||||
|
expect(set.connected(4, 9)).toBe(true);
|
||||||
|
expect(set.connected(4, 3)).toBe(true);
|
||||||
|
expect(set.connected(8, 4)).toBe(true);
|
||||||
|
|
||||||
|
expect(set.connected(8, 7)).toBe(false);
|
||||||
|
expect(set.connected(2, 3)).toBe(false);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should keep the height of the tree small', () => {
|
||||||
|
const set = new DisjointSetAdhoc(10);
|
||||||
|
|
||||||
|
// 1-2-6-7-9 1 3 4 5
|
||||||
|
set.union(7, 6);
|
||||||
|
set.union(1, 2);
|
||||||
|
set.union(2, 6);
|
||||||
|
set.union(1, 7);
|
||||||
|
set.union(9, 1);
|
||||||
|
|
||||||
|
expect(set.connected(1, 7)).toBe(true);
|
||||||
|
expect(set.connected(6, 9)).toBe(true);
|
||||||
|
expect(set.connected(4, 9)).toBe(false);
|
||||||
|
|
||||||
|
expect(Math.max(...set.heights)).toBe(3);
|
||||||
|
});
|
||||||
|
});
|
||||||
@ -4,7 +4,9 @@ _Read this in other languages:_
|
|||||||
[_简体中文_](README.zh-CN.md),
|
[_简体中文_](README.zh-CN.md),
|
||||||
[_Русский_](README.ru-RU.md),
|
[_Русский_](README.ru-RU.md),
|
||||||
[_Français_](README.fr-FR.md),
|
[_Français_](README.fr-FR.md),
|
||||||
[_Português_](README.pt-BR.md)
|
[_Português_](README.pt-BR.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
|
|
||||||
In computer science, a **graph** is an abstract data type
|
In computer science, a **graph** is an abstract data type
|
||||||
that is meant to implement the undirected graph and
|
that is meant to implement the undirected graph and
|
||||||
|
|||||||
24
src/data-structures/graph/README.uk-UA.md
Normal file
@ -0,0 +1,24 @@
|
|||||||
|
# Граф
|
||||||
|
|
||||||
|
**Граф** в інформатиці - абстрактний тип даних, який має реалізовувати концепції спрямованого та неспрямованого
|
||||||
|
графа у математиці, особливо у галузі теорії графів.
|
||||||
|
|
||||||
|
Структура даних графа складається з кінцевого (і можливо, що змінюється) набору вершин або вузлів, або точок, спільно з
|
||||||
|
набором ненаправлених пар цих вершин для ненаправленого графа або набором спрямованих пар для спрямованого графа.
|
||||||
|
Ці пари відомі як ребра, арки або лінії для ненаправленого графа та як стрілки, спрямовані ребра, спрямовані
|
||||||
|
арки чи спрямовані лінії для спрямованого графа. Ці вершини можуть бути частиною структури графа, або зовнішніми
|
||||||
|
сутностями, представленими цілими індексами або посиланнями.
|
||||||
|
|
||||||
|
Для різних областей застосування види графів можуть відрізнятися спрямованістю, обмеженнями на кількість зв'язків та
|
||||||
|
додатковими даними про вершини або ребра. Багато структур, що становлять практичний інтерес у математиці та
|
||||||
|
інформатики можуть бути представлені графами. Наприклад, будову Вікіпедії можна змоделювати за допомогою
|
||||||
|
орієнтованого графа, в якому вершини – це статті, а дуги (орієнтовані ребра) – гіперпосилання.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
## Посилання
|
||||||
|
|
||||||
|
- [Граф у математиці на Wikipedia](https://uk.wikipedia.org/wiki/%D0%93%D1%80%D0%B0%D1%84_(%D0%BC%D0%B0%D1%82%D0%B5%D0%BC%D0%B0%D1%82%D0%B8%D0%BA%D0%B0))
|
||||||
|
- [Структура даних Graph / Граф](https://www.youtube.com/watch?v=D0U8aFEhgKQ)
|
||||||
@ -279,7 +279,7 @@ export default class Heap {
|
|||||||
/* istanbul ignore next */
|
/* istanbul ignore next */
|
||||||
pairIsInCorrectOrder(firstElement, secondElement) {
|
pairIsInCorrectOrder(firstElement, secondElement) {
|
||||||
throw new Error(`
|
throw new Error(`
|
||||||
You have to implement heap pair comparision method
|
You have to implement heap pair comparison method
|
||||||
for ${firstElement} and ${secondElement} values.
|
for ${firstElement} and ${secondElement} values.
|
||||||
`);
|
`);
|
||||||
}
|
}
|
||||||
|
|||||||
115
src/data-structures/heap/MaxHeapAdhoc.js
Normal file
@ -0,0 +1,115 @@
|
|||||||
|
/**
|
||||||
|
* The minimalistic (ad hoc) version of a MaxHeap data structure that doesn't have
|
||||||
|
* external dependencies and that is easy to copy-paste and use during the
|
||||||
|
* coding interview if allowed by the interviewer (since many data
|
||||||
|
* structures in JS are missing).
|
||||||
|
*/
|
||||||
|
class MaxHeapAdhoc {
|
||||||
|
constructor(heap = []) {
|
||||||
|
this.heap = [];
|
||||||
|
heap.forEach(this.add);
|
||||||
|
}
|
||||||
|
|
||||||
|
add(num) {
|
||||||
|
this.heap.push(num);
|
||||||
|
this.heapifyUp();
|
||||||
|
}
|
||||||
|
|
||||||
|
peek() {
|
||||||
|
return this.heap[0];
|
||||||
|
}
|
||||||
|
|
||||||
|
poll() {
|
||||||
|
if (this.heap.length === 0) return undefined;
|
||||||
|
const top = this.heap[0];
|
||||||
|
this.heap[0] = this.heap[this.heap.length - 1];
|
||||||
|
this.heap.pop();
|
||||||
|
this.heapifyDown();
|
||||||
|
return top;
|
||||||
|
}
|
||||||
|
|
||||||
|
isEmpty() {
|
||||||
|
return this.heap.length === 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
toString() {
|
||||||
|
return this.heap.join(',');
|
||||||
|
}
|
||||||
|
|
||||||
|
heapifyUp() {
|
||||||
|
let nodeIndex = this.heap.length - 1;
|
||||||
|
while (nodeIndex > 0) {
|
||||||
|
const parentIndex = this.getParentIndex(nodeIndex);
|
||||||
|
if (this.heap[parentIndex] >= this.heap[nodeIndex]) break;
|
||||||
|
this.swap(parentIndex, nodeIndex);
|
||||||
|
nodeIndex = parentIndex;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
heapifyDown() {
|
||||||
|
let nodeIndex = 0;
|
||||||
|
|
||||||
|
while (
|
||||||
|
(
|
||||||
|
this.hasLeftChild(nodeIndex) && this.heap[nodeIndex] < this.leftChild(nodeIndex)
|
||||||
|
)
|
||||||
|
|| (
|
||||||
|
this.hasRightChild(nodeIndex) && this.heap[nodeIndex] < this.rightChild(nodeIndex)
|
||||||
|
)
|
||||||
|
) {
|
||||||
|
const leftIndex = this.getLeftChildIndex(nodeIndex);
|
||||||
|
const rightIndex = this.getRightChildIndex(nodeIndex);
|
||||||
|
const left = this.leftChild(nodeIndex);
|
||||||
|
const right = this.rightChild(nodeIndex);
|
||||||
|
|
||||||
|
if (this.hasLeftChild(nodeIndex) && this.hasRightChild(nodeIndex)) {
|
||||||
|
if (left >= right) {
|
||||||
|
this.swap(leftIndex, nodeIndex);
|
||||||
|
nodeIndex = leftIndex;
|
||||||
|
} else {
|
||||||
|
this.swap(rightIndex, nodeIndex);
|
||||||
|
nodeIndex = rightIndex;
|
||||||
|
}
|
||||||
|
} else if (this.hasLeftChild(nodeIndex)) {
|
||||||
|
this.swap(leftIndex, nodeIndex);
|
||||||
|
nodeIndex = leftIndex;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
getLeftChildIndex(parentIndex) {
|
||||||
|
return (2 * parentIndex) + 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
getRightChildIndex(parentIndex) {
|
||||||
|
return (2 * parentIndex) + 2;
|
||||||
|
}
|
||||||
|
|
||||||
|
getParentIndex(childIndex) {
|
||||||
|
return Math.floor((childIndex - 1) / 2);
|
||||||
|
}
|
||||||
|
|
||||||
|
hasLeftChild(parentIndex) {
|
||||||
|
return this.getLeftChildIndex(parentIndex) < this.heap.length;
|
||||||
|
}
|
||||||
|
|
||||||
|
hasRightChild(parentIndex) {
|
||||||
|
return this.getRightChildIndex(parentIndex) < this.heap.length;
|
||||||
|
}
|
||||||
|
|
||||||
|
leftChild(parentIndex) {
|
||||||
|
return this.heap[this.getLeftChildIndex(parentIndex)];
|
||||||
|
}
|
||||||
|
|
||||||
|
rightChild(parentIndex) {
|
||||||
|
return this.heap[this.getRightChildIndex(parentIndex)];
|
||||||
|
}
|
||||||
|
|
||||||
|
swap(indexOne, indexTwo) {
|
||||||
|
const tmp = this.heap[indexTwo];
|
||||||
|
this.heap[indexTwo] = this.heap[indexOne];
|
||||||
|
this.heap[indexOne] = tmp;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export default MaxHeapAdhoc;
|
||||||
117
src/data-structures/heap/MinHeapAdhoc.js
Normal file
@ -0,0 +1,117 @@
|
|||||||
|
/**
|
||||||
|
* The minimalistic (ad hoc) version of a MinHeap data structure that doesn't have
|
||||||
|
* external dependencies and that is easy to copy-paste and use during the
|
||||||
|
* coding interview if allowed by the interviewer (since many data
|
||||||
|
* structures in JS are missing).
|
||||||
|
*/
|
||||||
|
class MinHeapAdhoc {
|
||||||
|
constructor(heap = []) {
|
||||||
|
this.heap = [];
|
||||||
|
heap.forEach(this.add);
|
||||||
|
}
|
||||||
|
|
||||||
|
add(num) {
|
||||||
|
this.heap.push(num);
|
||||||
|
this.heapifyUp();
|
||||||
|
}
|
||||||
|
|
||||||
|
peek() {
|
||||||
|
return this.heap[0];
|
||||||
|
}
|
||||||
|
|
||||||
|
poll() {
|
||||||
|
if (this.heap.length === 0) return undefined;
|
||||||
|
const top = this.heap[0];
|
||||||
|
this.heap[0] = this.heap[this.heap.length - 1];
|
||||||
|
this.heap.pop();
|
||||||
|
this.heapifyDown();
|
||||||
|
return top;
|
||||||
|
}
|
||||||
|
|
||||||
|
isEmpty() {
|
||||||
|
return this.heap.length === 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
toString() {
|
||||||
|
return this.heap.join(',');
|
||||||
|
}
|
||||||
|
|
||||||
|
heapifyUp() {
|
||||||
|
let nodeIndex = this.heap.length - 1;
|
||||||
|
while (nodeIndex > 0) {
|
||||||
|
const parentIndex = this.getParentIndex(nodeIndex);
|
||||||
|
if (this.heap[parentIndex] <= this.heap[nodeIndex]) break;
|
||||||
|
this.swap(parentIndex, nodeIndex);
|
||||||
|
nodeIndex = parentIndex;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
heapifyDown() {
|
||||||
|
let nodeIndex = 0;
|
||||||
|
|
||||||
|
while (
|
||||||
|
(
|
||||||
|
this.hasLeftChild(nodeIndex)
|
||||||
|
&& this.heap[nodeIndex] > this.leftChild(nodeIndex)
|
||||||
|
)
|
||||||
|
|| (
|
||||||
|
this.hasRightChild(nodeIndex)
|
||||||
|
&& this.heap[nodeIndex] > this.rightChild(nodeIndex)
|
||||||
|
)
|
||||||
|
) {
|
||||||
|
const leftIndex = this.getLeftChildIndex(nodeIndex);
|
||||||
|
const rightIndex = this.getRightChildIndex(nodeIndex);
|
||||||
|
const left = this.leftChild(nodeIndex);
|
||||||
|
const right = this.rightChild(nodeIndex);
|
||||||
|
|
||||||
|
if (this.hasLeftChild(nodeIndex) && this.hasRightChild(nodeIndex)) {
|
||||||
|
if (left <= right) {
|
||||||
|
this.swap(leftIndex, nodeIndex);
|
||||||
|
nodeIndex = leftIndex;
|
||||||
|
} else {
|
||||||
|
this.swap(rightIndex, nodeIndex);
|
||||||
|
nodeIndex = rightIndex;
|
||||||
|
}
|
||||||
|
} else if (this.hasLeftChild(nodeIndex)) {
|
||||||
|
this.swap(leftIndex, nodeIndex);
|
||||||
|
nodeIndex = leftIndex;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
getLeftChildIndex(parentIndex) {
|
||||||
|
return 2 * parentIndex + 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
getRightChildIndex(parentIndex) {
|
||||||
|
return 2 * parentIndex + 2;
|
||||||
|
}
|
||||||
|
|
||||||
|
getParentIndex(childIndex) {
|
||||||
|
return Math.floor((childIndex - 1) / 2);
|
||||||
|
}
|
||||||
|
|
||||||
|
hasLeftChild(parentIndex) {
|
||||||
|
return this.getLeftChildIndex(parentIndex) < this.heap.length;
|
||||||
|
}
|
||||||
|
|
||||||
|
hasRightChild(parentIndex) {
|
||||||
|
return this.getRightChildIndex(parentIndex) < this.heap.length;
|
||||||
|
}
|
||||||
|
|
||||||
|
leftChild(parentIndex) {
|
||||||
|
return this.heap[this.getLeftChildIndex(parentIndex)];
|
||||||
|
}
|
||||||
|
|
||||||
|
rightChild(parentIndex) {
|
||||||
|
return this.heap[this.getRightChildIndex(parentIndex)];
|
||||||
|
}
|
||||||
|
|
||||||
|
swap(indexOne, indexTwo) {
|
||||||
|
const tmp = this.heap[indexTwo];
|
||||||
|
this.heap[indexTwo] = this.heap[indexOne];
|
||||||
|
this.heap[indexOne] = tmp;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export default MinHeapAdhoc;
|
||||||
@ -7,7 +7,9 @@ _Read this in other languages:_
|
|||||||
[_Français_](README.fr-FR.md),
|
[_Français_](README.fr-FR.md),
|
||||||
[_Português_](README.pt-BR.md),
|
[_Português_](README.pt-BR.md),
|
||||||
[_Türkçe_](README.tr-TR.md),
|
[_Türkçe_](README.tr-TR.md),
|
||||||
[_한국어_](README.ko-KR.md)
|
[_한국어_](README.ko-KR.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
|
|
||||||
In computer science, a **heap** is a specialized tree-based
|
In computer science, a **heap** is a specialized tree-based
|
||||||
data structure that satisfies the heap property described
|
data structure that satisfies the heap property described
|
||||||
@ -31,6 +33,36 @@ to the key of `C`
|
|||||||
The node at the "top" of the heap with no parents is
|
The node at the "top" of the heap with no parents is
|
||||||
called the root node.
|
called the root node.
|
||||||
|
|
||||||
|
## Time Complexities
|
||||||
|
|
||||||
|
Here are time complexities of various heap data structures. Function names assume a max-heap.
|
||||||
|
|
||||||
|
| Operation | find-max | delete-max | insert| increase-key| meld |
|
||||||
|
| --------- | -------- | ---------- | ----- | ----------- | ---- |
|
||||||
|
| [Binary](https://en.wikipedia.org/wiki/Binary_heap) | `Θ(1)` | `Θ(log n)` | `O(log n)` | `O(log n)` | `Θ(n)` |
|
||||||
|
| [Leftist](https://en.wikipedia.org/wiki/Leftist_tree) | `Θ(1)` | `Θ(log n)` | `Θ(log n)` | `O(log n)` | `Θ(log n)` |
|
||||||
|
| [Binomial](https://en.wikipedia.org/wiki/Binomial_heap) | `Θ(1)` | `Θ(log n)` | `Θ(1)` | `O(log n)` | `O(log n)` |
|
||||||
|
| [Fibonacci](https://en.wikipedia.org/wiki/Fibonacci_heap) | `Θ(1)` | `Θ(log n)` | `Θ(1)` | `Θ(1)` | `Θ(1)` |
|
||||||
|
| [Pairing](https://en.wikipedia.org/wiki/Pairing_heap) | `Θ(1)` | `Θ(log n)` | `Θ(1)` | `o(log n)` | `Θ(1)` |
|
||||||
|
| [Brodal](https://en.wikipedia.org/wiki/Brodal_queue) | `Θ(1)` | `Θ(log n)` | `Θ(1)` | `Θ(1)` | `Θ(1)` |
|
||||||
|
| [Rank-pairing](https://en.wikipedia.org/w/index.php?title=Rank-pairing_heap&action=edit&redlink=1) | `Θ(1)` | `Θ(log n)` | `Θ(1)` | `Θ(1)` | `Θ(1)` |
|
||||||
|
| [Strict Fibonacci](https://en.wikipedia.org/wiki/Fibonacci_heap) | `Θ(1)` | `Θ(log n)` | `Θ(1)` | `Θ(1)` | `Θ(1)` |
|
||||||
|
| [2-3 heap](https://en.wikipedia.org/wiki/2%E2%80%933_heap) | `O(log n)` | `O(log n)` | `O(log n)` | `Θ(1)` | `?` |
|
||||||
|
|
||||||
|
Where:
|
||||||
|
- **find-max (or find-min):** find a maximum item of a max-heap, or a minimum item of a min-heap, respectively (a.k.a. *peek*)
|
||||||
|
- **delete-max (or delete-min):** removing the root node of a max heap (or min heap), respectively
|
||||||
|
- **insert:** adding a new key to the heap (a.k.a., *push*)
|
||||||
|
- **increase-key or decrease-key:** updating a key within a max- or min-heap, respectively
|
||||||
|
- **meld:** joining two heaps to form a valid new heap containing all the elements of both, destroying the original heaps.
|
||||||
|
|
||||||
|
> In this repository, the [MaxHeap.js](./MaxHeap.js) and [MinHeap.js](./MinHeap.js) are examples of the **Binary** heap.
|
||||||
|
|
||||||
|
## Implementation
|
||||||
|
|
||||||
|
- [MaxHeap.js](./MaxHeap.js) and [MinHeap.js](./MinHeap.js)
|
||||||
|
- [MaxHeapAdhoc.js](./MaxHeapAdhoc.js) and [MinHeapAdhoc.js](./MinHeapAdhoc.js) - The minimalistic (ad hoc) version of a MinHeap/MaxHeap data structure that doesn't have external dependencies and that is easy to copy-paste and use during the coding interview if allowed by the interviewer (since many data structures in JS are missing).
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|
||||||
- [Wikipedia](https://en.wikipedia.org/wiki/Heap_(data_structure))
|
- [Wikipedia](https://en.wikipedia.org/wiki/Heap_(data_structure))
|
||||||
|
|||||||
25
src/data-structures/heap/README.uk-UA.md
Normal file
@ -0,0 +1,25 @@
|
|||||||
|
# Купа (структура даних)
|
||||||
|
|
||||||
|
У комп'ютерних науках купа - це спеціалізована структура даних на кшталт дерева, яка задовольняє властивості купи:
|
||||||
|
якщо B є вузлом-нащадком вузла A, то ключ (A) ≥ ключ (B). З цього випливає, що елемент із найбільшим ключем завжди
|
||||||
|
є кореневим вузлом купи, тому іноді такі купи називають max-купами.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
Якщо порівняння перевернути, то найменший елемент завжди буде кореневим вузлом, такі купи називають min-купами.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
Не існує жодних обмежень щодо того, скільки вузлів-нащадків має кожен вузол купи. На практиці їх
|
||||||
|
число зазвичай трохи більше двох. Купа є максимально ефективною реалізацією абстрактного типу даних, який
|
||||||
|
називається чергою із пріоритетом.
|
||||||
|
|
||||||
|
Вузол на вершині купи, який не має батьків, називається кореневим вузлом.
|
||||||
|
|
||||||
|
## Посилання
|
||||||
|
|
||||||
|
- [Wikipedia](https://uk.wikipedia.org/wiki/%D0%9A%D1%83%D0%BF%D0%B0_(%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D0%B4%D0%B0%D0%BD%D0%B8%D1%85))
|
||||||
91
src/data-structures/heap/__test__/MaxHeapAdhoc.test.js
Normal file
@ -0,0 +1,91 @@
|
|||||||
|
import MaxHeap from '../MaxHeapAdhoc';
|
||||||
|
|
||||||
|
describe('MaxHeapAdhoc', () => {
|
||||||
|
it('should create an empty max heap', () => {
|
||||||
|
const maxHeap = new MaxHeap();
|
||||||
|
|
||||||
|
expect(maxHeap).toBeDefined();
|
||||||
|
expect(maxHeap.peek()).toBe(undefined);
|
||||||
|
expect(maxHeap.isEmpty()).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should add items to the heap and heapify it up', () => {
|
||||||
|
const maxHeap = new MaxHeap();
|
||||||
|
|
||||||
|
maxHeap.add(5);
|
||||||
|
expect(maxHeap.isEmpty()).toBe(false);
|
||||||
|
expect(maxHeap.peek()).toBe(5);
|
||||||
|
expect(maxHeap.toString()).toBe('5');
|
||||||
|
|
||||||
|
maxHeap.add(3);
|
||||||
|
expect(maxHeap.peek()).toBe(5);
|
||||||
|
expect(maxHeap.toString()).toBe('5,3');
|
||||||
|
|
||||||
|
maxHeap.add(10);
|
||||||
|
expect(maxHeap.peek()).toBe(10);
|
||||||
|
expect(maxHeap.toString()).toBe('10,3,5');
|
||||||
|
|
||||||
|
maxHeap.add(1);
|
||||||
|
expect(maxHeap.peek()).toBe(10);
|
||||||
|
expect(maxHeap.toString()).toBe('10,3,5,1');
|
||||||
|
|
||||||
|
maxHeap.add(1);
|
||||||
|
expect(maxHeap.peek()).toBe(10);
|
||||||
|
expect(maxHeap.toString()).toBe('10,3,5,1,1');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(10);
|
||||||
|
expect(maxHeap.toString()).toBe('5,3,1,1');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(5);
|
||||||
|
expect(maxHeap.toString()).toBe('3,1,1');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(3);
|
||||||
|
expect(maxHeap.toString()).toBe('1,1');
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should poll items from the heap and heapify it down', () => {
|
||||||
|
const maxHeap = new MaxHeap();
|
||||||
|
|
||||||
|
maxHeap.add(5);
|
||||||
|
maxHeap.add(3);
|
||||||
|
maxHeap.add(10);
|
||||||
|
maxHeap.add(11);
|
||||||
|
maxHeap.add(1);
|
||||||
|
|
||||||
|
expect(maxHeap.toString()).toBe('11,10,5,3,1');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(11);
|
||||||
|
expect(maxHeap.toString()).toBe('10,3,5,1');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(10);
|
||||||
|
expect(maxHeap.toString()).toBe('5,3,1');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(5);
|
||||||
|
expect(maxHeap.toString()).toBe('3,1');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(3);
|
||||||
|
expect(maxHeap.toString()).toBe('1');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(1);
|
||||||
|
expect(maxHeap.toString()).toBe('');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(undefined);
|
||||||
|
expect(maxHeap.toString()).toBe('');
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should heapify down through the right branch as well', () => {
|
||||||
|
const maxHeap = new MaxHeap();
|
||||||
|
|
||||||
|
maxHeap.add(3);
|
||||||
|
maxHeap.add(12);
|
||||||
|
maxHeap.add(10);
|
||||||
|
|
||||||
|
expect(maxHeap.toString()).toBe('12,3,10');
|
||||||
|
|
||||||
|
maxHeap.add(11);
|
||||||
|
expect(maxHeap.toString()).toBe('12,11,10,3');
|
||||||
|
|
||||||
|
expect(maxHeap.poll()).toBe(12);
|
||||||
|
expect(maxHeap.toString()).toBe('11,3,10');
|
||||||
|
});
|
||||||
|
});
|
||||||
91
src/data-structures/heap/__test__/MinHeapAdhoc.test.js
Normal file
@ -0,0 +1,91 @@
|
|||||||
|
import MinHeapAdhoc from '../MinHeapAdhoc';
|
||||||
|
|
||||||
|
describe('MinHeapAdhoc', () => {
|
||||||
|
it('should create an empty min heap', () => {
|
||||||
|
const minHeap = new MinHeapAdhoc();
|
||||||
|
|
||||||
|
expect(minHeap).toBeDefined();
|
||||||
|
expect(minHeap.peek()).toBe(undefined);
|
||||||
|
expect(minHeap.isEmpty()).toBe(true);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should add items to the heap and heapify it up', () => {
|
||||||
|
const minHeap = new MinHeapAdhoc();
|
||||||
|
|
||||||
|
minHeap.add(5);
|
||||||
|
expect(minHeap.isEmpty()).toBe(false);
|
||||||
|
expect(minHeap.peek()).toBe(5);
|
||||||
|
expect(minHeap.toString()).toBe('5');
|
||||||
|
|
||||||
|
minHeap.add(3);
|
||||||
|
expect(minHeap.peek()).toBe(3);
|
||||||
|
expect(minHeap.toString()).toBe('3,5');
|
||||||
|
|
||||||
|
minHeap.add(10);
|
||||||
|
expect(minHeap.peek()).toBe(3);
|
||||||
|
expect(minHeap.toString()).toBe('3,5,10');
|
||||||
|
|
||||||
|
minHeap.add(1);
|
||||||
|
expect(minHeap.peek()).toBe(1);
|
||||||
|
expect(minHeap.toString()).toBe('1,3,10,5');
|
||||||
|
|
||||||
|
minHeap.add(1);
|
||||||
|
expect(minHeap.peek()).toBe(1);
|
||||||
|
expect(minHeap.toString()).toBe('1,1,10,5,3');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(1);
|
||||||
|
expect(minHeap.toString()).toBe('1,3,10,5');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(1);
|
||||||
|
expect(minHeap.toString()).toBe('3,5,10');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(3);
|
||||||
|
expect(minHeap.toString()).toBe('5,10');
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should poll items from the heap and heapify it down', () => {
|
||||||
|
const minHeap = new MinHeapAdhoc();
|
||||||
|
|
||||||
|
minHeap.add(5);
|
||||||
|
minHeap.add(3);
|
||||||
|
minHeap.add(10);
|
||||||
|
minHeap.add(11);
|
||||||
|
minHeap.add(1);
|
||||||
|
|
||||||
|
expect(minHeap.toString()).toBe('1,3,10,11,5');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(1);
|
||||||
|
expect(minHeap.toString()).toBe('3,5,10,11');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(3);
|
||||||
|
expect(minHeap.toString()).toBe('5,11,10');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(5);
|
||||||
|
expect(minHeap.toString()).toBe('10,11');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(10);
|
||||||
|
expect(minHeap.toString()).toBe('11');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(11);
|
||||||
|
expect(minHeap.toString()).toBe('');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(undefined);
|
||||||
|
expect(minHeap.toString()).toBe('');
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should heapify down through the right branch as well', () => {
|
||||||
|
const minHeap = new MinHeapAdhoc();
|
||||||
|
|
||||||
|
minHeap.add(3);
|
||||||
|
minHeap.add(12);
|
||||||
|
minHeap.add(10);
|
||||||
|
|
||||||
|
expect(minHeap.toString()).toBe('3,12,10');
|
||||||
|
|
||||||
|
minHeap.add(11);
|
||||||
|
expect(minHeap.toString()).toBe('3,11,10,12');
|
||||||
|
|
||||||
|
expect(minHeap.poll()).toBe(3);
|
||||||
|
expect(minHeap.toString()).toBe('10,11,12');
|
||||||
|
});
|
||||||
|
});
|
||||||
@ -7,7 +7,8 @@ _Read this in other languages:_
|
|||||||
[_Português_](README.pt-BR.md),
|
[_Português_](README.pt-BR.md),
|
||||||
[_한국어_](README.ko-KR.md),
|
[_한국어_](README.ko-KR.md),
|
||||||
[_Español_](README.es-ES.md),
|
[_Español_](README.es-ES.md),
|
||||||
[_Turkish_](README.tr-TR.md),
|
[_Türkçe_](README.tr-TR.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
In computer science, a **linked list** is a linear collection
|
In computer science, a **linked list** is a linear collection
|
||||||
of data elements, in which linear order is not given by
|
of data elements, in which linear order is not given by
|
||||||
|
|||||||
147
src/data-structures/linked-list/README.uk-UA.md
Normal file
@ -0,0 +1,147 @@
|
|||||||
|
# Зв'язаний список
|
||||||
|
|
||||||
|
Зв'язаний список — базова динамічна структура даних в інформатиці, що складається з вузлів, кожен з яких містить як дані, так і посилання («зв'язку») на наступний вузол списку. Ця структура даних дозволяє ефективно додавати та видаляти елементи на довільній позиції у послідовності у процесі ітерації. Більш складні варіанти включають додаткові посилання, що дозволяють ефективно додавати та видаляти довільні елементи.
|
||||||
|
|
||||||
|
Принциповою перевагою перед масивом є структурна гнучкість: порядок елементів зв'язаного списку може збігатися з порядком розташування елементів даних у пам'яті комп'ютера, а порядок обходу списку завжди явно задається його внутрішніми зв'язками. Це важливо, бо у багатьох мовах створення масиву вимагає вказати його розмір заздалегідь. Зв'язаний список дозволяє обійти це обмеження.
|
||||||
|
|
||||||
|
Недоліком зв'язаних списків є те, що час доступу є лінійним (і важко для реалізації конвеєрів). Неможливий швидкий доступ (випадковий).
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
## Псевдокод основних операцій
|
||||||
|
|
||||||
|
### Вставка
|
||||||
|
|
||||||
|
```text
|
||||||
|
Add(value)
|
||||||
|
Pre: value - значення, що додається
|
||||||
|
Post: value додано в кінець списку
|
||||||
|
n ← node(value)
|
||||||
|
if head = ø
|
||||||
|
head ← n
|
||||||
|
tail ← n
|
||||||
|
else
|
||||||
|
tail.next ← n
|
||||||
|
tail ← n
|
||||||
|
end if
|
||||||
|
end Add
|
||||||
|
```
|
||||||
|
|
||||||
|
```text
|
||||||
|
Prepend(value)
|
||||||
|
Pre: value - значення, що додається
|
||||||
|
Post: value додано на початку списку
|
||||||
|
n ← node(value)
|
||||||
|
n.next ← head
|
||||||
|
head ← n
|
||||||
|
if tail = ø
|
||||||
|
tail ← n
|
||||||
|
end
|
||||||
|
end Prepend
|
||||||
|
```
|
||||||
|
|
||||||
|
### Пошук
|
||||||
|
|
||||||
|
```text
|
||||||
|
Contains(head, value)
|
||||||
|
Pre: head - перший вузол у списку
|
||||||
|
value - значення, яке слід знайти
|
||||||
|
Post: true - value знайдено у списку, інакше false
|
||||||
|
n ← head
|
||||||
|
while n != ø and n.value != value
|
||||||
|
n ← n.next
|
||||||
|
end while
|
||||||
|
if n = ø
|
||||||
|
return false
|
||||||
|
end if
|
||||||
|
return true
|
||||||
|
end Contains
|
||||||
|
```
|
||||||
|
|
||||||
|
### Видалення
|
||||||
|
|
||||||
|
```text
|
||||||
|
Remove(head, value)
|
||||||
|
Pre: head - перший вузол у списку
|
||||||
|
value - значення, яке слід видалити
|
||||||
|
Post: true - value видалено зі списку, інакше false
|
||||||
|
if head = ø
|
||||||
|
return false
|
||||||
|
end if
|
||||||
|
n ← head
|
||||||
|
if n.value = value
|
||||||
|
if head = tail
|
||||||
|
head ← ø
|
||||||
|
tail ← ø
|
||||||
|
else
|
||||||
|
head ← head.next
|
||||||
|
end if
|
||||||
|
return true
|
||||||
|
end if
|
||||||
|
while n.next != ø and n.next.value != value
|
||||||
|
n ← n.next
|
||||||
|
end while
|
||||||
|
if n.next != ø
|
||||||
|
if n.next = tail
|
||||||
|
tail ← n
|
||||||
|
end if
|
||||||
|
n.next ← n.next.next
|
||||||
|
return true
|
||||||
|
end if
|
||||||
|
return false
|
||||||
|
end Remove
|
||||||
|
```
|
||||||
|
|
||||||
|
### Обхід
|
||||||
|
|
||||||
|
```text
|
||||||
|
Traverse(head)
|
||||||
|
Pre: head - перший вузол у списку
|
||||||
|
Post: елементи списку пройдені
|
||||||
|
n ← head
|
||||||
|
while n != ø
|
||||||
|
yield n.value
|
||||||
|
n ← n.next
|
||||||
|
end while
|
||||||
|
end Traverse
|
||||||
|
```
|
||||||
|
|
||||||
|
### Зворотній обхід
|
||||||
|
|
||||||
|
```text
|
||||||
|
ReverseTraversal(head, tail)
|
||||||
|
Pre: head і tail відносяться до одного списку
|
||||||
|
Post: елементи списку пройдено у зворотньому порядку
|
||||||
|
if tail != ø
|
||||||
|
curr ← tail
|
||||||
|
while curr != head
|
||||||
|
prev ← head
|
||||||
|
while prev.next != curr
|
||||||
|
prev ← prev.next
|
||||||
|
end while
|
||||||
|
yield curr.value
|
||||||
|
curr ← prev
|
||||||
|
end while
|
||||||
|
yield curr.value
|
||||||
|
end if
|
||||||
|
end ReverseTraversal
|
||||||
|
```
|
||||||
|
|
||||||
|
## Складність
|
||||||
|
|
||||||
|
### Часова складність
|
||||||
|
|
||||||
|
| Читання | Пошук | Вставка | Вилучення |
|
||||||
|
| :--------: | :-------: | :--------: | :-------: |
|
||||||
|
| O(n) | O(n) | O(1) | O(n) |
|
||||||
|
|
||||||
|
### Просторова складність
|
||||||
|
|
||||||
|
O(n)
|
||||||
|
|
||||||
|
## Посилання
|
||||||
|
|
||||||
|
- [Wikipedia](https://uk.wikipedia.org/wiki/Зв'язаний_список)
|
||||||
|
- [YouTube](https://www.youtube.com/watch?v=6snsMa4E1Os)
|
||||||
155
src/data-structures/linked-list/README.vi-VN.md
Normal file
@ -0,0 +1,155 @@
|
|||||||
|
# Danh sách liên kết (Linked List)
|
||||||
|
|
||||||
|
_Đọc bằng ngôn ngữ khác:_
|
||||||
|
[_简体中文_](README.zh-CN.md),
|
||||||
|
[_Русский_](README.ru-RU.md),
|
||||||
|
[_日本語_](README.ja-JP.md),
|
||||||
|
[_Português_](README.pt-BR.md),
|
||||||
|
[_한국어_](README.ko-KR.md),
|
||||||
|
[_Español_](README.es-ES.md),
|
||||||
|
[_Türkçe_](README.tr-TR.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
|
|
||||||
|
Trong khoa học máy tính, một danh sách liên kết là một bộ sưu tập tuyến tính
|
||||||
|
các phần tử dữ liệu, trong đó thứ tự tuyến tính không được xác định bởi
|
||||||
|
vị trí vật lý của chúng trong bộ nhớ. Thay vào đó, mỗi
|
||||||
|
phần tử trỏ đến phần tử tiếp theo. Đây là một cấu trúc dữ liệu
|
||||||
|
bao gồm một nhóm các nút cùng đại diện cho
|
||||||
|
một chuỗi. Dưới dạng đơn giản nhất, mỗi nút
|
||||||
|
bao gồm dữ liệu và một tham chiếu (nói cách khác,
|
||||||
|
một liên kết) đến nút tiếp theo trong chuỗi. Cấu trúc này
|
||||||
|
cho phép việc chèn hoặc loại bỏ các phần tử một cách hiệu quả
|
||||||
|
từ bất kỳ vị trí nào trong chuỗi trong quá trình lặp.
|
||||||
|
Các biến thể phức tạp hơn thêm các liên kết bổ sung, cho phép
|
||||||
|
việc chèn hoặc loại bỏ một cách hiệu quả từ bất kỳ phần tử nào
|
||||||
|
trong chuỗi dựa trên tham chiếu. Một nhược điểm của danh sách liên kết
|
||||||
|
là thời gian truy cập tuyến tính (và khó điều chỉnh). Truy cập nhanh hơn,
|
||||||
|
như truy cập ngẫu nhiên, là không khả thi. Mảng
|
||||||
|
có độ tương phản cache tốt hơn so với danh sách liên kết.
|
||||||
|
|
||||||
|

|
||||||
|
*Được làm từ [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
## Mã giải (Pseudocode) cho Các Hoạt Động Cơ Bản
|
||||||
|
*head = đầu,
|
||||||
|
*tail = đuôi,
|
||||||
|
*next = kế tiếp,
|
||||||
|
*node = nút,
|
||||||
|
*value = giá trị
|
||||||
|
|
||||||
|
### Chèn (Insert)
|
||||||
|
|
||||||
|
```
|
||||||
|
ThêmGiáTrị(giá trị) (Add(value))
|
||||||
|
Trước(Pre): giá trị là giá trị muốn thêm vào danh sách
|
||||||
|
Sau(Post): giá trị đã được đặt ở cuối danh sách
|
||||||
|
|
||||||
|
n ← node(value)
|
||||||
|
if head = ø
|
||||||
|
head ← n
|
||||||
|
tail ← n
|
||||||
|
else
|
||||||
|
tail.next ← n
|
||||||
|
tail ← n
|
||||||
|
end if
|
||||||
|
end ThêmGiáTrị(Add)
|
||||||
|
```
|
||||||
|
|
||||||
|
```
|
||||||
|
ChènVàoĐầu(giá trị)
|
||||||
|
Trước(Pre): giá trị là giá trị muốn thêm vào danh sách
|
||||||
|
Sau(Post): giá trị đã được đặt ở đầu danh sách
|
||||||
|
|
||||||
|
n ← node(value)
|
||||||
|
n.next ← head
|
||||||
|
head ← n
|
||||||
|
if tail = ø
|
||||||
|
tail ← n
|
||||||
|
end
|
||||||
|
end ChènVàoĐầu
|
||||||
|
```
|
||||||
|
|
||||||
|
### Tìm Kiếm (Search)
|
||||||
|
```
|
||||||
|
Chứa(đầu, giá trị)
|
||||||
|
Trước: đầu là nút đầu trong danh sách
|
||||||
|
giá trị là giá trị cần tìm kiếm
|
||||||
|
Sau: mục đó có thể ở trong danh sách liên kết, true; nếu không, là false
|
||||||
|
n ← head
|
||||||
|
while n != ø and n.value != value
|
||||||
|
n ← n.next
|
||||||
|
end while
|
||||||
|
if n = ø
|
||||||
|
return false
|
||||||
|
end if
|
||||||
|
return true
|
||||||
|
end Contains
|
||||||
|
```
|
||||||
|
|
||||||
|
### Xóa (Delete)
|
||||||
|
```
|
||||||
|
Xóa(đầu, giá trị)
|
||||||
|
Trước: đầu là nút đầu trong danh sách
|
||||||
|
giá trị là giá trị cần xóa khỏi danh sách
|
||||||
|
Sau: giá trị đã được xóa khỏi danh sách, true; nếu không, là false
|
||||||
|
if head = ø
|
||||||
|
return false
|
||||||
|
end if
|
||||||
|
n ← head
|
||||||
|
if n.value = value
|
||||||
|
if head = tail
|
||||||
|
head ← ø
|
||||||
|
tail ← ø
|
||||||
|
else
|
||||||
|
head ← head.next
|
||||||
|
end if
|
||||||
|
return true
|
||||||
|
end if
|
||||||
|
while n.next != ø and n.next.value != value
|
||||||
|
n ← n.next
|
||||||
|
end while
|
||||||
|
if n.next != ø
|
||||||
|
if n.next = tail
|
||||||
|
tail ← n
|
||||||
|
tail.next = null
|
||||||
|
else
|
||||||
|
n.next ← n.next.next
|
||||||
|
end if
|
||||||
|
return true
|
||||||
|
end if
|
||||||
|
return false
|
||||||
|
end Remove
|
||||||
|
```
|
||||||
|
|
||||||
|
### Duyệt(raverse)
|
||||||
|
Duyệt(đầu)
|
||||||
|
Trước: đầu là nút đầu trong danh sách
|
||||||
|
Sau: các mục trong danh sách đã được duyệt
|
||||||
|
n ← head
|
||||||
|
while n != ø
|
||||||
|
yield n.value
|
||||||
|
n ← n.next
|
||||||
|
end while
|
||||||
|
end Traverse
|
||||||
|
|
||||||
|
### Duyệt Ngược (Traverse in Reverse)
|
||||||
|
DuyệtNgược(đầu, đuôi)
|
||||||
|
Trước: đầu và đuôi thuộc cùng một danh sách
|
||||||
|
Sau: các mục trong danh sách đã được duyệt theo thứ tự ngược lại
|
||||||
|
|
||||||
|
## Độ Phức Tạp
|
||||||
|
|
||||||
|
### Độ Phức Tạp Thời Gian (Time Complexity)
|
||||||
|
|
||||||
|
| Access | Search | Insertion | Deletion |
|
||||||
|
| :-------: | :-------: | :-------: | :-------: |
|
||||||
|
| O(n) | O(n) | O(1) | O(n) |
|
||||||
|
|
||||||
|
## Độ Phức Tạp Không Gian (Space Complexity)
|
||||||
|
O(n)
|
||||||
|
|
||||||
|
## Tham Khảo
|
||||||
|
|
||||||
|
- [Wikipedia](https://en.wikipedia.org/wiki/Linked_list)
|
||||||
|
- [YouTube](https://www.youtube.com/watch?v=njTh_OwMljA&index=2&t=1s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||||
153
src/data-structures/lru-cache/LRUCache.js
Normal file
@ -0,0 +1,153 @@
|
|||||||
|
/* eslint-disable no-param-reassign, max-classes-per-file */
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Simple implementation of the Doubly-Linked List Node
|
||||||
|
* that is used in LRUCache class below.
|
||||||
|
*/
|
||||||
|
class LinkedListNode {
|
||||||
|
/**
|
||||||
|
* Creates a doubly-linked list node.
|
||||||
|
* @param {string} key
|
||||||
|
* @param {any} val
|
||||||
|
* @param {LinkedListNode} prev
|
||||||
|
* @param {LinkedListNode} next
|
||||||
|
*/
|
||||||
|
constructor(key, val, prev = null, next = null) {
|
||||||
|
this.key = key;
|
||||||
|
this.val = val;
|
||||||
|
this.prev = prev;
|
||||||
|
this.next = next;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Implementation of the LRU (Least Recently Used) Cache
|
||||||
|
* based on the HashMap and Doubly Linked List data-structures.
|
||||||
|
*
|
||||||
|
* Current implementation allows to have fast O(1) (in average) read and write operations.
|
||||||
|
*
|
||||||
|
* At any moment in time the LRU Cache holds not more that "capacity" number of items in it.
|
||||||
|
*/
|
||||||
|
class LRUCache {
|
||||||
|
/**
|
||||||
|
* Creates a cache instance of a specific capacity.
|
||||||
|
* @param {number} capacity
|
||||||
|
*/
|
||||||
|
constructor(capacity) {
|
||||||
|
this.capacity = capacity; // How many items to store in cache at max.
|
||||||
|
this.nodesMap = {}; // The quick links to each linked list node in cache.
|
||||||
|
this.size = 0; // The number of items that is currently stored in the cache.
|
||||||
|
this.head = new LinkedListNode(); // The Head (first) linked list node.
|
||||||
|
this.tail = new LinkedListNode(); // The Tail (last) linked list node.
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Returns the cached value by its key.
|
||||||
|
* Time complexity: O(1) in average.
|
||||||
|
* @param {string} key
|
||||||
|
* @returns {any}
|
||||||
|
*/
|
||||||
|
get(key) {
|
||||||
|
if (this.nodesMap[key] === undefined) return undefined;
|
||||||
|
const node = this.nodesMap[key];
|
||||||
|
this.promote(node);
|
||||||
|
return node.val;
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Sets the value to cache by its key.
|
||||||
|
* Time complexity: O(1) in average.
|
||||||
|
* @param {string} key
|
||||||
|
* @param {any} val
|
||||||
|
*/
|
||||||
|
set(key, val) {
|
||||||
|
if (this.nodesMap[key]) {
|
||||||
|
const node = this.nodesMap[key];
|
||||||
|
node.val = val;
|
||||||
|
this.promote(node);
|
||||||
|
} else {
|
||||||
|
const node = new LinkedListNode(key, val);
|
||||||
|
this.append(node);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Promotes the node to the end of the linked list.
|
||||||
|
* It means that the node is most frequently used.
|
||||||
|
* It also reduces the chance for such node to get evicted from cache.
|
||||||
|
* @param {LinkedListNode} node
|
||||||
|
*/
|
||||||
|
promote(node) {
|
||||||
|
this.evict(node);
|
||||||
|
this.append(node);
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Appends a new node to the end of the cache linked list.
|
||||||
|
* @param {LinkedListNode} node
|
||||||
|
*/
|
||||||
|
append(node) {
|
||||||
|
this.nodesMap[node.key] = node;
|
||||||
|
|
||||||
|
if (!this.head.next) {
|
||||||
|
// First node to append.
|
||||||
|
this.head.next = node;
|
||||||
|
this.tail.prev = node;
|
||||||
|
node.prev = this.head;
|
||||||
|
node.next = this.tail;
|
||||||
|
} else {
|
||||||
|
// Append to an existing tail.
|
||||||
|
const oldTail = this.tail.prev;
|
||||||
|
oldTail.next = node;
|
||||||
|
node.prev = oldTail;
|
||||||
|
node.next = this.tail;
|
||||||
|
this.tail.prev = node;
|
||||||
|
}
|
||||||
|
|
||||||
|
this.size += 1;
|
||||||
|
|
||||||
|
if (this.size > this.capacity) {
|
||||||
|
this.evict(this.head.next);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Evicts (removes) the node from cache linked list.
|
||||||
|
* @param {LinkedListNode} node
|
||||||
|
*/
|
||||||
|
evict(node) {
|
||||||
|
delete this.nodesMap[node.key];
|
||||||
|
this.size -= 1;
|
||||||
|
|
||||||
|
const prevNode = node.prev;
|
||||||
|
const nextNode = node.next;
|
||||||
|
|
||||||
|
// If one and only node.
|
||||||
|
if (prevNode === this.head && nextNode === this.tail) {
|
||||||
|
this.head.next = null;
|
||||||
|
this.tail.prev = null;
|
||||||
|
this.size = 0;
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
|
||||||
|
// If this is a Head node.
|
||||||
|
if (prevNode === this.head) {
|
||||||
|
nextNode.prev = this.head;
|
||||||
|
this.head.next = nextNode;
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
|
||||||
|
// If this is a Tail node.
|
||||||
|
if (nextNode === this.tail) {
|
||||||
|
prevNode.next = this.tail;
|
||||||
|
this.tail.prev = prevNode;
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
|
||||||
|
// If the node is in the middle.
|
||||||
|
prevNode.next = nextNode;
|
||||||
|
nextNode.prev = prevNode;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export default LRUCache;
|
||||||
53
src/data-structures/lru-cache/LRUCacheOnMap.js
Normal file
@ -0,0 +1,53 @@
|
|||||||
|
/* eslint-disable no-restricted-syntax, no-unreachable-loop */
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Implementation of the LRU (Least Recently Used) Cache
|
||||||
|
* based on the (ordered) Map data-structure.
|
||||||
|
*
|
||||||
|
* Current implementation allows to have fast O(1) (in average) read and write operations.
|
||||||
|
*
|
||||||
|
* At any moment in time the LRU Cache holds not more that "capacity" number of items in it.
|
||||||
|
*/
|
||||||
|
class LRUCacheOnMap {
|
||||||
|
/**
|
||||||
|
* Creates a cache instance of a specific capacity.
|
||||||
|
* @param {number} capacity
|
||||||
|
*/
|
||||||
|
constructor(capacity) {
|
||||||
|
this.capacity = capacity; // How many items to store in cache at max.
|
||||||
|
this.items = new Map(); // The ordered hash map of all cached items.
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Returns the cached value by its key.
|
||||||
|
* Time complexity: O(1) in average.
|
||||||
|
* @param {string} key
|
||||||
|
* @returns {any}
|
||||||
|
*/
|
||||||
|
get(key) {
|
||||||
|
if (!this.items.has(key)) return undefined;
|
||||||
|
const val = this.items.get(key);
|
||||||
|
this.items.delete(key);
|
||||||
|
this.items.set(key, val);
|
||||||
|
return val;
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Sets the value to cache by its key.
|
||||||
|
* Time complexity: O(1).
|
||||||
|
* @param {string} key
|
||||||
|
* @param {any} val
|
||||||
|
*/
|
||||||
|
set(key, val) {
|
||||||
|
this.items.delete(key);
|
||||||
|
this.items.set(key, val);
|
||||||
|
if (this.items.size > this.capacity) {
|
||||||
|
for (const headKey of this.items.keys()) {
|
||||||
|
this.items.delete(headKey);
|
||||||
|
break;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
export default LRUCacheOnMap;
|
||||||
51
src/data-structures/lru-cache/README.ko-KR.md
Normal file
@ -0,0 +1,51 @@
|
|||||||
|
# LRU 캐시 알고리즘
|
||||||
|
|
||||||
|
**LRU 캐시 알고리즘** 은 사용된 순서대로 아이템을 정리함으로써, 오랜 시간 동안 사용되지 않은 아이템을 빠르게 찾아낼 수 있도록 한다.
|
||||||
|
|
||||||
|
한방향으로만 옷을 걸 수 있는 옷걸이 행거를 생각해봅시다. 가장 오랫동안 입지 않은 옷을 찾기 위해서는, 행거의 반대쪽 끝을 보면 됩니다.
|
||||||
|
|
||||||
|
## 문제 정의
|
||||||
|
|
||||||
|
LRUCache 클래스를 구현해봅시다:
|
||||||
|
|
||||||
|
- `LRUCache(int capacity)` LRU 캐시를 **양수** 의 `capacity` 로 초기화합니다.
|
||||||
|
- `int get(int key)` `key` 가 존재할 경우 `key` 값을 반환하고, 그렇지 않으면 `undefined` 를 반환합니다.
|
||||||
|
- `void set(int key, int value)` `key` 가 존재할 경우 `key` 값을 업데이트 하고, 그렇지 않으면 `key-value` 쌍을 캐시에 추가합니다. 만약 이 동작으로 인해 키 개수가 `capacity` 를 넘는 경우, 가장 오래된 키 값을 **제거** 합니다.
|
||||||
|
|
||||||
|
`get()` 과 `set()` 함수는 무조건 평균 `O(1)` 의 시간 복잡도 내에 실행되어야 합니다.
|
||||||
|
|
||||||
|
## 구현
|
||||||
|
|
||||||
|
### 버전 1: 더블 링크드 리스트 + 해시맵
|
||||||
|
|
||||||
|
[LRUCache.js](./LRUCache.js) 에서 `LRUCache` 구현체 예시를 확인할 수 있습니다. 예시에서는 (평균적으로) 빠른 `O(1)` 캐시 아이템 접근을 위해 `HashMap` 을 사용했고, (평균적으로) 빠른 `O(1)` 캐시 아이템 수정과 제거를 위해 `DoublyLinkedList` 를 사용했습니다. (허용된 최대의 캐시 용량을 유지하기 위해)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_[okso.app](https://okso.app) 으로 만듦_
|
||||||
|
|
||||||
|
LRU 캐시가 어떻게 작동하는지 더 많은 예시로 확인하고 싶다면 LRUCache.test.js](./**test**/LRUCache.test.js) 파일을 참고하세요.
|
||||||
|
|
||||||
|
### 버전 2: 정렬된 맵
|
||||||
|
|
||||||
|
더블 링크드 리스트로 구현한 첫번째 예시는 어떻게 평균 `O(1)` 시간 복잡도가 `set()` 과 `get()` 으로 나올 수 있는지 학습 목적과 이해를 돕기 위해 좋은 예시입니다.
|
||||||
|
|
||||||
|
그러나, 더 쉬운 방법은 자바스크립트의 [Map](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) 객체를 사용하는 것입니다. 이 `Map` 객체는 키-값 쌍과 키를 **추가하는 순서 원본** 을 지닙니다. 우리는 이걸 아이템을 제거하거나 다시 추가하면서 맵의 "가장 마지막" 동작에서 최근에 사용된 아이템을 유지하기 위해 사용할 수 있습니다. `Map` 의 시작점에 있는 아이템은 캐시 용량이 넘칠 경우 가장 먼저 제거되는 대상입니다. 아이템의 순서는 `map.keys()` 와 같은 `IterableIterator` 을 사용해 확인할 수 있습니다.
|
||||||
|
|
||||||
|
해당 구현체는 [LRUCacheOnMap.js](./LRUCacheOnMap.js) 의 `LRUCacheOnMap` 예시에서 확인할 수 있습니다.
|
||||||
|
|
||||||
|
이 LRU 캐시 방식이 어떻게 작동하는지 더 많은 테스트 케이스를 확인하고 싶다면 [LRUCacheOnMap.test.js](./__test__/LRUCacheOnMap.test.js) 파일을 참고하세요.
|
||||||
|
|
||||||
|
## 복잡도
|
||||||
|
|
||||||
|
| | 평균 |
|
||||||
|
| --------------- | ------ |
|
||||||
|
| 공간 | `O(n)` |
|
||||||
|
| 아이템 찾기 | `O(1)` |
|
||||||
|
| 아이템 설정하기 | `O(1)` |
|
||||||
|
|
||||||
|
## 참조
|
||||||
|
|
||||||
|
- [LRU Cache on LeetCode](https://leetcode.com/problems/lru-cache/solutions/244744/lru-cache/)
|
||||||
|
- [LRU Cache on InterviewCake](https://www.interviewcake.com/concept/java/lru-cache)
|
||||||
|
- [LRU Cache on Wiki](https://en.wikipedia.org/wiki/Cache_replacement_policies)
|
||||||
54
src/data-structures/lru-cache/README.md
Normal file
@ -0,0 +1,54 @@
|
|||||||
|
# Least Recently Used (LRU) Cache
|
||||||
|
|
||||||
|
_Read this in other languages:_
|
||||||
|
[한국어](README.ko-KR.md),
|
||||||
|
|
||||||
|
A **Least Recently Used (LRU) Cache** organizes items in order of use, allowing you to quickly identify which item hasn't been used for the longest amount of time.
|
||||||
|
|
||||||
|
Picture a clothes rack, where clothes are always hung up on one side. To find the least-recently used item, look at the item on the other end of the rack.
|
||||||
|
|
||||||
|
## The problem statement
|
||||||
|
|
||||||
|
Implement the LRUCache class:
|
||||||
|
|
||||||
|
- `LRUCache(int capacity)` Initialize the LRU cache with **positive** size `capacity`.
|
||||||
|
- `int get(int key)` Return the value of the `key` if the `key` exists, otherwise return `undefined`.
|
||||||
|
- `void set(int key, int value)` Update the value of the `key` if the `key` exists. Otherwise, add the `key-value` pair to the cache. If the number of keys exceeds the `capacity` from this operation, **evict** the least recently used key.
|
||||||
|
|
||||||
|
The functions `get()` and `set()` must each run in `O(1)` average time complexity.
|
||||||
|
|
||||||
|
## Implementation
|
||||||
|
|
||||||
|
### Version 1: Doubly Linked List + Hash Map
|
||||||
|
|
||||||
|
See the `LRUCache` implementation example in [LRUCache.js](./LRUCache.js). The solution uses a `HashMap` for fast `O(1)` (in average) cache items access, and a `DoublyLinkedList` for fast `O(1)` (in average) cache items promotions and eviction (to keep the maximum allowed cache capacity).
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_Made with [okso.app](https://okso.app)_
|
||||||
|
|
||||||
|
You may also find more test-case examples of how the LRU Cache works in [LRUCache.test.js](./__test__/LRUCache.test.js) file.
|
||||||
|
|
||||||
|
### Version 2: Ordered Map
|
||||||
|
|
||||||
|
The first implementation that uses doubly linked list is good for learning purposes and for better understanding of how the average `O(1)` time complexity is achievable while doing `set()` and `get()`.
|
||||||
|
|
||||||
|
However, the simpler approach might be to use a JavaScript [Map](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Map) object. The `Map` object holds key-value pairs and **remembers the original insertion order** of the keys. We can use this fact in order to keep the recently-used items in the "end" of the map by removing and re-adding items. The item at the beginning of the `Map` is the first one to be evicted if cache capacity overflows. The order of the items may checked by using the `IterableIterator` like `map.keys()`.
|
||||||
|
|
||||||
|
See the `LRUCacheOnMap` implementation example in [LRUCacheOnMap.js](./LRUCacheOnMap.js).
|
||||||
|
|
||||||
|
You may also find more test-case examples of how the LRU Cache works in [LRUCacheOnMap.test.js](./__test__/LRUCacheOnMap.test.js) file.
|
||||||
|
|
||||||
|
## Complexities
|
||||||
|
|
||||||
|
| | Average |
|
||||||
|
| -------- | ------- |
|
||||||
|
| Space | `O(n)` |
|
||||||
|
| Get item | `O(1)` |
|
||||||
|
| Set item | `O(1)` |
|
||||||
|
|
||||||
|
## References
|
||||||
|
|
||||||
|
- [LRU Cache on LeetCode](https://leetcode.com/problems/lru-cache/solutions/244744/lru-cache/)
|
||||||
|
- [LRU Cache on InterviewCake](https://www.interviewcake.com/concept/java/lru-cache)
|
||||||
|
- [LRU Cache on Wiki](https://en.wikipedia.org/wiki/Cache_replacement_policies)
|
||||||
150
src/data-structures/lru-cache/__test__/LRUCache.test.js
Normal file
@ -0,0 +1,150 @@
|
|||||||
|
import LRUCache from '../LRUCache';
|
||||||
|
|
||||||
|
describe('LRUCache', () => {
|
||||||
|
it('should set and get values to and from the cache', () => {
|
||||||
|
const cache = new LRUCache(100);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
|
||||||
|
cache.set('key-1', 15);
|
||||||
|
cache.set('key-2', 16);
|
||||||
|
cache.set('key-3', 17);
|
||||||
|
expect(cache.get('key-1')).toBe(15);
|
||||||
|
expect(cache.get('key-2')).toBe(16);
|
||||||
|
expect(cache.get('key-3')).toBe(17);
|
||||||
|
expect(cache.get('key-3')).toBe(17);
|
||||||
|
expect(cache.get('key-2')).toBe(16);
|
||||||
|
expect(cache.get('key-1')).toBe(15);
|
||||||
|
|
||||||
|
cache.set('key-1', 5);
|
||||||
|
cache.set('key-2', 6);
|
||||||
|
cache.set('key-3', 7);
|
||||||
|
expect(cache.get('key-1')).toBe(5);
|
||||||
|
expect(cache.get('key-2')).toBe(6);
|
||||||
|
expect(cache.get('key-3')).toBe(7);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should evict least recently used items from cache with cache size of 1', () => {
|
||||||
|
const cache = new LRUCache(1);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
|
||||||
|
cache.set('key-1', 15);
|
||||||
|
expect(cache.get('key-1')).toBe(15);
|
||||||
|
|
||||||
|
cache.set('key-2', 16);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
expect(cache.get('key-2')).toBe(16);
|
||||||
|
|
||||||
|
cache.set('key-2', 17);
|
||||||
|
expect(cache.get('key-2')).toBe(17);
|
||||||
|
|
||||||
|
cache.set('key-3', 18);
|
||||||
|
cache.set('key-4', 19);
|
||||||
|
expect(cache.get('key-2')).toBeUndefined();
|
||||||
|
expect(cache.get('key-3')).toBeUndefined();
|
||||||
|
expect(cache.get('key-4')).toBe(19);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should evict least recently used items from cache with cache size of 2', () => {
|
||||||
|
const cache = new LRUCache(2);
|
||||||
|
expect(cache.get('key-21')).toBeUndefined();
|
||||||
|
|
||||||
|
cache.set('key-21', 15);
|
||||||
|
expect(cache.get('key-21')).toBe(15);
|
||||||
|
|
||||||
|
cache.set('key-22', 16);
|
||||||
|
expect(cache.get('key-21')).toBe(15);
|
||||||
|
expect(cache.get('key-22')).toBe(16);
|
||||||
|
|
||||||
|
cache.set('key-22', 17);
|
||||||
|
expect(cache.get('key-22')).toBe(17);
|
||||||
|
|
||||||
|
cache.set('key-23', 18);
|
||||||
|
expect(cache.size).toBe(2);
|
||||||
|
expect(cache.get('key-21')).toBeUndefined();
|
||||||
|
expect(cache.get('key-22')).toBe(17);
|
||||||
|
expect(cache.get('key-23')).toBe(18);
|
||||||
|
|
||||||
|
cache.set('key-24', 19);
|
||||||
|
expect(cache.size).toBe(2);
|
||||||
|
expect(cache.get('key-21')).toBeUndefined();
|
||||||
|
expect(cache.get('key-22')).toBeUndefined();
|
||||||
|
expect(cache.get('key-23')).toBe(18);
|
||||||
|
expect(cache.get('key-24')).toBe(19);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should evict least recently used items from cache with cache size of 3', () => {
|
||||||
|
const cache = new LRUCache(3);
|
||||||
|
|
||||||
|
cache.set('key-1', 1);
|
||||||
|
cache.set('key-2', 2);
|
||||||
|
cache.set('key-3', 3);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
|
||||||
|
cache.set('key-3', 4);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(4);
|
||||||
|
|
||||||
|
cache.set('key-4', 5);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(4);
|
||||||
|
expect(cache.get('key-4')).toBe(5);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should promote the node while calling set() method', () => {
|
||||||
|
const cache = new LRUCache(2);
|
||||||
|
|
||||||
|
cache.set('2', 1);
|
||||||
|
cache.set('1', 1);
|
||||||
|
cache.set('2', 3);
|
||||||
|
cache.set('4', 1);
|
||||||
|
expect(cache.get('1')).toBeUndefined();
|
||||||
|
expect(cache.get('2')).toBe(3);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should promote the recently accessed item with cache size of 3', () => {
|
||||||
|
const cache = new LRUCache(3);
|
||||||
|
|
||||||
|
cache.set('key-1', 1);
|
||||||
|
cache.set('key-2', 2);
|
||||||
|
cache.set('key-3', 3);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
|
||||||
|
cache.set('key-4', 4);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
expect(cache.get('key-4')).toBe(4);
|
||||||
|
expect(cache.get('key-2')).toBeUndefined();
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should promote the recently accessed item with cache size of 4', () => {
|
||||||
|
const cache = new LRUCache(4);
|
||||||
|
|
||||||
|
cache.set('key-1', 1);
|
||||||
|
cache.set('key-2', 2);
|
||||||
|
cache.set('key-3', 3);
|
||||||
|
cache.set('key-4', 4);
|
||||||
|
expect(cache.get('key-4')).toBe(4);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
|
||||||
|
cache.set('key-5', 5);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
expect(cache.get('key-4')).toBeUndefined();
|
||||||
|
expect(cache.get('key-5')).toBe(5);
|
||||||
|
|
||||||
|
cache.set('key-6', 6);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
expect(cache.get('key-4')).toBeUndefined();
|
||||||
|
expect(cache.get('key-5')).toBe(5);
|
||||||
|
expect(cache.get('key-6')).toBe(6);
|
||||||
|
});
|
||||||
|
});
|
||||||
148
src/data-structures/lru-cache/__test__/LRUCacheOnMap.test.js
Normal file
@ -0,0 +1,148 @@
|
|||||||
|
import LRUCache from '../LRUCacheOnMap';
|
||||||
|
|
||||||
|
describe('LRUCacheOnMap', () => {
|
||||||
|
it('should set and get values to and from the cache', () => {
|
||||||
|
const cache = new LRUCache(100);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
|
||||||
|
cache.set('key-1', 15);
|
||||||
|
cache.set('key-2', 16);
|
||||||
|
cache.set('key-3', 17);
|
||||||
|
expect(cache.get('key-1')).toBe(15);
|
||||||
|
expect(cache.get('key-2')).toBe(16);
|
||||||
|
expect(cache.get('key-3')).toBe(17);
|
||||||
|
expect(cache.get('key-3')).toBe(17);
|
||||||
|
expect(cache.get('key-2')).toBe(16);
|
||||||
|
expect(cache.get('key-1')).toBe(15);
|
||||||
|
|
||||||
|
cache.set('key-1', 5);
|
||||||
|
cache.set('key-2', 6);
|
||||||
|
cache.set('key-3', 7);
|
||||||
|
expect(cache.get('key-1')).toBe(5);
|
||||||
|
expect(cache.get('key-2')).toBe(6);
|
||||||
|
expect(cache.get('key-3')).toBe(7);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should evict least recently used items from cache with cache size of 1', () => {
|
||||||
|
const cache = new LRUCache(1);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
|
||||||
|
cache.set('key-1', 15);
|
||||||
|
expect(cache.get('key-1')).toBe(15);
|
||||||
|
|
||||||
|
cache.set('key-2', 16);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
expect(cache.get('key-2')).toBe(16);
|
||||||
|
|
||||||
|
cache.set('key-2', 17);
|
||||||
|
expect(cache.get('key-2')).toBe(17);
|
||||||
|
|
||||||
|
cache.set('key-3', 18);
|
||||||
|
cache.set('key-4', 19);
|
||||||
|
expect(cache.get('key-2')).toBeUndefined();
|
||||||
|
expect(cache.get('key-3')).toBeUndefined();
|
||||||
|
expect(cache.get('key-4')).toBe(19);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should evict least recently used items from cache with cache size of 2', () => {
|
||||||
|
const cache = new LRUCache(2);
|
||||||
|
expect(cache.get('key-21')).toBeUndefined();
|
||||||
|
|
||||||
|
cache.set('key-21', 15);
|
||||||
|
expect(cache.get('key-21')).toBe(15);
|
||||||
|
|
||||||
|
cache.set('key-22', 16);
|
||||||
|
expect(cache.get('key-21')).toBe(15);
|
||||||
|
expect(cache.get('key-22')).toBe(16);
|
||||||
|
|
||||||
|
cache.set('key-22', 17);
|
||||||
|
expect(cache.get('key-22')).toBe(17);
|
||||||
|
|
||||||
|
cache.set('key-23', 18);
|
||||||
|
expect(cache.get('key-21')).toBeUndefined();
|
||||||
|
expect(cache.get('key-22')).toBe(17);
|
||||||
|
expect(cache.get('key-23')).toBe(18);
|
||||||
|
|
||||||
|
cache.set('key-24', 19);
|
||||||
|
expect(cache.get('key-21')).toBeUndefined();
|
||||||
|
expect(cache.get('key-22')).toBeUndefined();
|
||||||
|
expect(cache.get('key-23')).toBe(18);
|
||||||
|
expect(cache.get('key-24')).toBe(19);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should evict least recently used items from cache with cache size of 3', () => {
|
||||||
|
const cache = new LRUCache(3);
|
||||||
|
|
||||||
|
cache.set('key-1', 1);
|
||||||
|
cache.set('key-2', 2);
|
||||||
|
cache.set('key-3', 3);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
|
||||||
|
cache.set('key-3', 4);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(4);
|
||||||
|
|
||||||
|
cache.set('key-4', 5);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(4);
|
||||||
|
expect(cache.get('key-4')).toBe(5);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should promote the node while calling set() method', () => {
|
||||||
|
const cache = new LRUCache(2);
|
||||||
|
|
||||||
|
cache.set('2', 1);
|
||||||
|
cache.set('1', 1);
|
||||||
|
cache.set('2', 3);
|
||||||
|
cache.set('4', 1);
|
||||||
|
expect(cache.get('1')).toBeUndefined();
|
||||||
|
expect(cache.get('2')).toBe(3);
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should promote the recently accessed item with cache size of 3', () => {
|
||||||
|
const cache = new LRUCache(3);
|
||||||
|
|
||||||
|
cache.set('key-1', 1);
|
||||||
|
cache.set('key-2', 2);
|
||||||
|
cache.set('key-3', 3);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
|
||||||
|
cache.set('key-4', 4);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
expect(cache.get('key-4')).toBe(4);
|
||||||
|
expect(cache.get('key-2')).toBeUndefined();
|
||||||
|
});
|
||||||
|
|
||||||
|
it('should promote the recently accessed item with cache size of 4', () => {
|
||||||
|
const cache = new LRUCache(4);
|
||||||
|
|
||||||
|
cache.set('key-1', 1);
|
||||||
|
cache.set('key-2', 2);
|
||||||
|
cache.set('key-3', 3);
|
||||||
|
cache.set('key-4', 4);
|
||||||
|
expect(cache.get('key-4')).toBe(4);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
|
||||||
|
cache.set('key-5', 5);
|
||||||
|
expect(cache.get('key-1')).toBe(1);
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
expect(cache.get('key-4')).toBeUndefined();
|
||||||
|
expect(cache.get('key-5')).toBe(5);
|
||||||
|
|
||||||
|
cache.set('key-6', 6);
|
||||||
|
expect(cache.get('key-1')).toBeUndefined();
|
||||||
|
expect(cache.get('key-2')).toBe(2);
|
||||||
|
expect(cache.get('key-3')).toBe(3);
|
||||||
|
expect(cache.get('key-4')).toBeUndefined();
|
||||||
|
expect(cache.get('key-5')).toBe(5);
|
||||||
|
expect(cache.get('key-6')).toBe(6);
|
||||||
|
});
|
||||||
|
});
|
||||||
BIN
src/data-structures/lru-cache/images/lru-cache.jpg
Normal file
{kind=link}
|
After Width: | Height: | Size: 650 KiB |
@ -6,20 +6,21 @@ _Read this in other languages:_
|
|||||||
[_日本語_](README.ja-JP.md),
|
[_日本語_](README.ja-JP.md),
|
||||||
[_Français_](README.fr-FR.md),
|
[_Français_](README.fr-FR.md),
|
||||||
[_Português_](README.pt-BR.md),
|
[_Português_](README.pt-BR.md),
|
||||||
[_한국어_](README.ko-KR.md)
|
[_한국어_](README.ko-KR.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
In computer science, a **priority queue** is an abstract data type
|
In computer science, a **priority queue** is an abstract data type
|
||||||
which is like a regular queue or stack data structure, but where
|
which is like a regular queue or stack data structure, but where
|
||||||
additionally each element has a "priority" associated with it.
|
additionally each element has a "priority" associated with it.
|
||||||
In a priority queue, an element with high priority is served before
|
In a priority queue, an element with high priority is served before
|
||||||
an element with low priority. If two elements have the same
|
an element with low priority. If two elements have the same
|
||||||
priority, they are served according to their order in the queue.
|
priority, they are served according to their order in the queue.
|
||||||
|
|
||||||
While priority queues are often implemented with heaps, they are
|
While priority queues are often implemented with heaps, they are
|
||||||
conceptually distinct from heaps. A priority queue is an abstract
|
conceptually distinct from heaps. A priority queue is an abstract
|
||||||
concept like "a list" or "a map"; just as a list can be implemented
|
concept like "a list" or "a map"; just as a list can be implemented
|
||||||
with a linked list or an array, a priority queue can be implemented
|
with a linked list or an array, a priority queue can be implemented
|
||||||
with a heap or a variety of other methods such as an unordered
|
with a heap or a variety of other methods such as an unordered
|
||||||
array.
|
array.
|
||||||
|
|
||||||
## References
|
## References
|
||||||
|
|||||||
21
src/data-structures/priority-queue/README.uk-UA.md
Normal file
@ -0,0 +1,21 @@
|
|||||||
|
# Черга з пріоритетом
|
||||||
|
|
||||||
|
Черга з пріоритетом (англ. priority queue) - абстрактний тип даних в інформатиці,
|
||||||
|
для кожного елемента якого можна визначити його пріоритет.
|
||||||
|
|
||||||
|
У черзі з пріоритетами елемент із високим пріоритетом обслуговується раніше
|
||||||
|
елемент з низьким пріоритетом. Якщо два елементи мають однаковий пріоритет, вони
|
||||||
|
обслуговуються відповідно до їх порядку в черзі.
|
||||||
|
|
||||||
|
Черга з пріоритетом підтримує дві обов'язкові операції – додати елемент та
|
||||||
|
витягти максимум (мінімум).
|
||||||
|
|
||||||
|
Хоча пріоритетні черги часто реалізуються у вигляді куп (heaps), вони
|
||||||
|
концептуально відрізняються від куп. Черга пріоритетів є абстрактною
|
||||||
|
концепцією на кшталт «списку» чи «карти»; так само, як список може бути реалізований
|
||||||
|
у вигляді зв'язкового списку або масиву, так і черга з пріоритетом може бути реалізована
|
||||||
|
у вигляді купи або безліччю інших методів, наприклад, у вигляді невпорядкованого масиву.
|
||||||
|
|
||||||
|
## Посилання
|
||||||
|
|
||||||
|
- [Wikipedia](https://uk.wikipedia.org/wiki/%D0%A7%D0%B5%D1%80%D0%B3%D0%B0_%D0%B7_%D0%BF%D1%80%D1%96%D0%BE%D1%80%D0%B8%D1%82%D0%B5%D1%82%D0%BE%D0%BC)
|
||||||
@ -6,7 +6,8 @@ _Read this in other languages:_
|
|||||||
[_日本語_](README.ja-JP.md),
|
[_日本語_](README.ja-JP.md),
|
||||||
[_Français_](README.fr-FR.md),
|
[_Français_](README.fr-FR.md),
|
||||||
[_Português_](README.pt-BR.md),
|
[_Português_](README.pt-BR.md),
|
||||||
[_한국어_](README.ko-KR.md)
|
[_한국어_](README.ko-KR.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
In computer science, a **queue** is a particular kind of abstract data
|
In computer science, a **queue** is a particular kind of abstract data
|
||||||
type or collection in which the entities in the collection are
|
type or collection in which the entities in the collection are
|
||||||
|
|||||||
21
src/data-structures/queue/README.uk-UA.md
Normal file
@ -0,0 +1,21 @@
|
|||||||
|
# Черга
|
||||||
|
|
||||||
|
Черга (англ. queue) – структура даних в інформатиці, в якій елементи
|
||||||
|
зберігаються у порядку їх додавання. Додавання нових елементів(enqueue)
|
||||||
|
здійснюється на кінець списку. А видалення елементів (dequeue)
|
||||||
|
здійснюється із початку. Таким чином черга реалізує принцип
|
||||||
|
"першим увійшов – першим вийшов" (FIFO). Часто реалізується операція читання
|
||||||
|
головного елемента (peek), яка повертає перший у черзі елемент,
|
||||||
|
при цьому не видаляючи його. Черга є прикладом лінійної структури
|
||||||
|
даних чи послідовної колекції.
|
||||||
|
|
||||||
|
Ілюстрація роботи з чергою.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
## Список літератури
|
||||||
|
|
||||||
|
- [Wikipedia](https://uk.wikipedia.org/wiki/%D0%A7%D0%B5%D1%80%D0%B3%D0%B0_(%D1%81%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D0%B4%D0%B0%D0%BD%D0%B8%D1%85))
|
||||||
|
- [YouTube](https://www.youtube.com/watch?v=ll4QLNSPn60)
|
||||||
22
src/data-structures/queue/README.vi-VN.md
Normal file
@ -0,0 +1,22 @@
|
|||||||
|
# Hàng đợi (Queue)
|
||||||
|
|
||||||
|
_Đọc bằng ngôn ngữ khác:_
|
||||||
|
[_简体中文_](README.zh-CN.md),
|
||||||
|
[_Русский_](README.ru-RU.md),
|
||||||
|
[_日本語_](README.ja-JP.md),
|
||||||
|
[_Português_](README.pt-BR.md),
|
||||||
|
[_한국어_](README.ko-KR.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
|
Trong khoa học máy tính, một **hàng đợi** là một loại cụ thể của kiểu dữ liệu trừu tượng hoặc bộ sưu tập trong đó các phần tử trong bộ sưu tập được giữ theo thứ tự và nguyên tắc (hoặc chỉ) các hoạt động trên bộ sưu tập là thêm các phần tử vào vị trí cuối cùng, được gọi là đưa vào hàng đợi (enqueue), và loại bỏ các phần tử từ vị trí đầu tiên, được gọi là đưa ra khỏi hàng đợi (dequeue). Điều này khiến cho hàng đợi trở thành một cấu trúc dữ liệu First-In-First-Out (FIFO). Trong cấu trúc dữ liệu FIFO, phần tử đầu tiên được thêm vào hàng đợi sẽ là phần tử đầu tiên được loại bỏ. Điều này tương đương với yêu cầu rằng sau khi một phần tử mới được thêm vào, tất cả các phần tử đã được thêm vào trước đó phải được loại bỏ trước khi có thể loại bỏ phần tử mới. Thường thì cũng có thêm một hoạt động nhìn hay lấy phần đầu, trả về giá trị của phần tử đầu tiên mà không loại bỏ nó. Hàng đợi là một ví dụ về cấu trúc dữ liệu tuyến tính, hoặc trừu tượng hơn là một bộ sưu tập tuần tự.
|
||||||
|
|
||||||
|
Hàng đợi FIFO (First-In-First-Out) có thể được biểu diễn như sau:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
## Tham Khảo
|
||||||
|
|
||||||
|
- [Wikipedia](https://en.wikipedia.org/wiki/Queue_(abstract_data_type))
|
||||||
|
- [YouTube](https://www.youtube.com/watch?v=wjI1WNcIntg&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=3&)
|
||||||
@ -6,7 +6,8 @@ _Read this in other languages:_
|
|||||||
[_日本語_](README.ja-JP.md),
|
[_日本語_](README.ja-JP.md),
|
||||||
[_Français_](README.fr-FR.md),
|
[_Français_](README.fr-FR.md),
|
||||||
[_Português_](README.pt-BR.md),
|
[_Português_](README.pt-BR.md),
|
||||||
[_한국어_](README.ko-KR.md)
|
[_한국어_](README.ko-KR.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
In computer science, a **stack** is an abstract data type that serves
|
In computer science, a **stack** is an abstract data type that serves
|
||||||
as a collection of elements, with two principal operations:
|
as a collection of elements, with two principal operations:
|
||||||
|
|||||||
25
src/data-structures/stack/README.uk-UA.md
Normal file
@ -0,0 +1,25 @@
|
|||||||
|
# Стек
|
||||||
|
|
||||||
|
Стек (англ. stack - стопка) - абстрактний тип даних, що представляє собою
|
||||||
|
список елементів, організованих за принципом LIFO (останнім прийшов – першим вийшов).
|
||||||
|
|
||||||
|
Стек має дві ключові операції:
|
||||||
|
* **додавання (push)** елемента в кінець стеку, та
|
||||||
|
* **видалення (pop)**, останнього доданого елемента.
|
||||||
|
|
||||||
|
Додаткова операція для читання головного елемента (peek) дає доступ
|
||||||
|
до останнього елементу стека без зміни самого стека.
|
||||||
|
|
||||||
|
Найчастіше принцип роботи стека порівнюють зі чаркою тарілок: щоб узяти другу
|
||||||
|
зверху потрібно зняти верхню.
|
||||||
|
|
||||||
|
Ілюстрація роботи зі стеком.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
## Посилання
|
||||||
|
|
||||||
|
- [Wikipedia](https://uk.wikipedia.org/wiki/%D0%A1%D1%82%D0%B5%D0%BA)
|
||||||
|
- [YouTube](https://www.youtube.com/watch?v=4jh1e1YCbYc)
|
||||||
27
src/data-structures/stack/README.vi-VN.md
Normal file
@ -0,0 +1,27 @@
|
|||||||
|
# Ngăn xếp (stack)
|
||||||
|
|
||||||
|
_Đọc bằng ngôn ngữ khác:_
|
||||||
|
[_简体中文_](README.zh-CN.md),
|
||||||
|
[_Русский_](README.ru-RU.md),
|
||||||
|
[_日本語_](README.ja-JP.md),
|
||||||
|
[_Português_](README.pt-BR.md),
|
||||||
|
[_한국어_](README.ko-KR.md),
|
||||||
|
[_Español_](README.es-ES.md),
|
||||||
|
[_Українська_](README.uk-UA.md)
|
||||||
|
|
||||||
|
Trong khoa học máy tính, một ngăn xếp (stack) là một kiểu dữ liệu trừu tượng phục vụ như một bộ sưu tập các phần tử, với hai hoạt động chính:
|
||||||
|
|
||||||
|
đẩy (push), thêm một phần tử vào bộ sưu tập, và
|
||||||
|
lấy (pop), loại bỏ phần tử được thêm gần nhất mà chưa được loại bỏ.
|
||||||
|
Thứ tự mà các phần tử được lấy ra khỏi ngăn xếp dẫn đến tên gọi thay thế của nó, là LIFO (last in, first out). Ngoài ra, một hoạt động nhìn có thể cung cấp quyền truy cập vào phần trên mà không làm thay đổi ngăn xếp. Tên "ngăn xếp" cho loại cấu trúc này đến từ sự tương tự với một bộ sưu tập các vật phẩm vật lý được xếp chồng lên nhau, điều này làm cho việc lấy một vật phẩm ra khỏi đỉnh của ngăn xếp dễ dàng, trong khi để đến được một vật phẩm sâu hơn trong ngăn xếp có thể đòi hỏi việc lấy ra nhiều vật phẩm khác trước đó.
|
||||||
|
|
||||||
|
Biểu diễn đơn giản về thời gian chạy của một ngăn xếp với các hoạt động đẩy và lấy.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
## Tham Khảo
|
||||||
|
|
||||||
|
- [Wikipedia](https://en.wikipedia.org/wiki/Linked_list)
|
||||||
|
- [YouTube](https://www.youtube.com/watch?v=njTh_OwMljA&index=2&t=1s&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8)
|
||||||
@ -23,7 +23,7 @@ together with a list of references to nodes (the "children"),
|
|||||||
with the constraints that no reference is duplicated, and none
|
with the constraints that no reference is duplicated, and none
|
||||||
points to the root.
|
points to the root.
|
||||||
|
|
||||||
A simple unordered tree; in this diagram, the node labeled 7 has
|
A simple unordered tree; in this diagram, the node labeled 3 has
|
||||||
two children, labeled 2 and 6, and one parent, labeled 2. The
|
two children, labeled 2 and 6, and one parent, labeled 2. The
|
||||||
root node, at the top, has no parent.
|
root node, at the top, has no parent.
|
||||||
|
|
||||||
|
|||||||
19
src/data-structures/trie/README.ko-KO.md
Normal file
@ -0,0 +1,19 @@
|
|||||||
|
# Trie
|
||||||
|
|
||||||
|
_Read this in other languages:_
|
||||||
|
[_简体中文_](README.zh-CN.md),
|
||||||
|
[_Русский_](README.ru-RU.md),
|
||||||
|
[_Português_](README.pt-BR.md),
|
||||||
|
[_Українська_](README.uk-UA.md),
|
||||||
|
[_한국어_](README.ko-KO.md)
|
||||||
|
|
||||||
|
컴퓨터 과학에서 **트라이**는 디지털 트리라고도 불리며 때로는 기수 트리 또는 접두사 트리(접두사로 검색할 수 있기 때문에)라고도 불리며 일종의 검색 트리입니다. 키가 보통 문자열인 동적 집합 또는 연관 배열을 저장하는 데 사용되는 순서가 지정된 트리 데이터 구조입니다. 이진 검색 트리와 달리 트리의 어떤 노드도 해당 노드와 연결된 키를 저장하지 않으며 대신 트리의 위치가 해당 노드와 연결된 키를 정의합니다. 노드의 모든 하위 항목은 해당 노드와 연결된 문자열의 공통 접두사를 가지며 루트는 빈 문자열과 연결됩니다. 값은 모든 노드와 반드시 연결되지는 않습니다. 오히려 값은 나뭇잎과 관심 있는 키에 해당하는 일부 내부 노드에만 연결되는 경향이 있습니다. 접두사 트리의 공간에 최적화된 표현은 콤팩트 접두사 트리를 참조하십시오.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
_Made with [okso.app](https://okso.app)_
|
||||||
|
|
||||||
|
## 참조
|
||||||
|
|
||||||
|
- [Wikipedia](<https://ko.wikipedia.org/wiki/%ED%8A%B8%EB%9D%BC%EC%9D%B4_(%EC%BB%B4%ED%93%A8%ED%8C%85)>)
|
||||||
|
- [YouTube](https://www.youtube.com/watch?v=zIjfhVPRZCg&list=PLLXdhg_r2hKA7DPDsunoDZ-Z769jWn4R8&index=7&t=0s)
|
||||||
@ -3,7 +3,9 @@
|
|||||||
_Read this in other languages:_
|
_Read this in other languages:_
|
||||||
[_简体中文_](README.zh-CN.md),
|
[_简体中文_](README.zh-CN.md),
|
||||||
[_Русский_](README.ru-RU.md),
|
[_Русский_](README.ru-RU.md),
|
||||||
[_Português_](README.pt-BR.md)
|
[_Português_](README.pt-BR.md),
|
||||||
|
[_Українська_](README.uk-UA.md),
|
||||||
|
[_한국어_](README.ko-KO.md)
|
||||||
|
|
||||||
In computer science, a **trie**, also called digital tree and sometimes
|
In computer science, a **trie**, also called digital tree and sometimes
|
||||||
radix tree or prefix tree (as they can be searched by prefixes),
|
radix tree or prefix tree (as they can be searched by prefixes),
|
||||||
|
|||||||
27
src/data-structures/trie/README.uk-UA.md
Normal file
@ -0,0 +1,27 @@
|
|||||||
|
# Префіксне дерево
|
||||||
|
|
||||||
|
**Префіксне дерево** (Також промінь, навантажене або суфіксне дерево) в інформатиці - впорядкована деревоподібна
|
||||||
|
структура даних, яка використовується для зберігання динамічних множин або асоціативних масивів, де
|
||||||
|
ключем зазвичай виступають рядки. Дерево називається префіксним, тому що пошук здійснюється за префіксами.
|
||||||
|
|
||||||
|
На відміну від бінарного дерева, вузли не містять ключів, що відповідають вузлу. Являє собою кореневе дерево, кожне
|
||||||
|
ребро якого позначено якимось символом так, що для будь-якого вузла всі ребра, що з'єднують цей вузол з його синами,
|
||||||
|
позначені різними символами. Деякі вузли префіксного дерева виділені (на малюнку вони підписані цифрами) і вважається,
|
||||||
|
що префіксне дерево містить цей рядок-ключ тоді і тільки тоді, коли цей рядок можна прочитати на шляху з
|
||||||
|
кореня до певного виділеного вузла.
|
||||||
|
|
||||||
|
Таким чином, на відміну від бінарних дерев пошуку, ключ, що ідентифікує конкретний вузол дерева, не явно зберігається в
|
||||||
|
цьому вузлі, а неявно задається положенням цього вузла в дереві. Отримати ключ можна виписуванням поспіль символів,
|
||||||
|
помічають ребра по дорозі від кореня до вузла. Ключ кореня дерева - порожній рядок. Часто у виділених вузлах зберігають
|
||||||
|
додаткову інформацію, пов'язану з ключем, і зазвичай виділеними є тільки листя і, можливо, деякі
|
||||||
|
внутрішні вузли.
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
*Made with [okso.app](https://okso.app)*
|
||||||
|
|
||||||
|
На малюнку представлено префіксне дерево, що містить ключі. «A», «to», «tea», «ted», «ten», «i», «in», «inn».
|
||||||
|
|
||||||
|
## Посилання
|
||||||
|
|
||||||
|
- [Wikipedia](https://uk.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D1%84%D1%96%D0%BA%D1%81%D0%BD%D0%B5_%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE)
|
||||||