20 KiB
JavaScript Algorytmy i Struktury Danych

![]()
To repozytorium zawiera wiele przykładów JavaScript opartych na znanych algorytmach i strukturach danych.
Każdy algorytm i struktura danych zawiera osobny plik README wraz z powiązanymi wyjaśnieniami i odnośnikami do dalszego czytania (włącznie z tymi do YouTube videos).
Read this in other languages: English 简体中文, 繁體中文, 한국어, Français, Español
Jesteśmy w trakcie pisania książki, która w jasny i specyficzny sposób, wyjaśni główne algorytmy. Jeżeli chcesz dostać powiadomienie o tym kiedy książka “JavaScript Algorithms†zostanie wydana,kliknij tutaj.
Struktury Danych
Struktura danych to sposób uporządkowania i przechowywania informacji w komputerze żeby mogłaby być sprawnie dostępna i efektywnie zmodyfikowana. Dokładniej, struktura danych jest zbiorem wartości danych, relacjami pomiędzy nimi, zadaniami lub działaniami, które mogą dotyczyć danych.
B - Początkujący, A - Zaawansowany
BListaBLista DwukierunkowaBKolejkaBStosBTabela SkrótuBStertaBKolejka PriorytetowaATrieADrzewoAWyszukiwanie BinarneAAVL DrzewoADrzewa czerwono-czarneADrzewo Segmentu - z przykładami zapytań o min / max / sumie sumADrzewo Fenwicka (Drzewo Indeksowane Binarnie)
AGraf (zarówno skierowane i nieukierunkowane)ARozłączny ZestawAFiltr Blooma
Algorytmy
Algorytm jest to skończony ciąg jasno zdefiniowanych czynności, koniecznych do wykonania pewnego rodzaju zadań. Sposób postępowania prowadzący do rozwiązania problemu.
B - Początkujący, A - Zaawansowany
Algorytmy według tematu
- Matematyka
BManipulacja Bitami - ustaw / uzyskaj / aktualizuj / usuwaj bity, mnożenie / dzielenie przez dwa, tworzenie negatywów itp.BSilnaBCiąg FibonacciegoBTest Pierwszorzędności (metoda podziału na próby)BAlgorytm Euclideana - obliczyć Największy Wspólny Dzielnik (GCD)BNajmniejsza Wspólna Wielokrotność (LCM)BSito Eratosthenes-a - znajdowanie wszystkich liczb pierwszych do określonego limituBJest Potęgą Dwójki - sprawdź, czy liczba jest potęgą dwóch (algorytmy naiwne i bitowe)BTrójkąt PascalaAPartycja CałkowitaAAlgorytm Liu Huia - przybliżone obliczenia na podstawie N-gonów
- Zestawy
BProdukt Kartezyjny - wynik wielu zestawówBPrzetasowanie Fisher Yates-a - losowa permutacja kończącej się seriiAZestaw Zasilający - podzbiór wszystkich seriiAPermutacje (z albo bez powtórzeń)AKombinacje (z albo bez powtórzeń)ANajdłuższa Wspólna Podsekwencja (LCS)ANajdłuższa Wzrostająca PodsekwencjaANajkrótsza Wspólna Supersekwencja (SCS)AProblem Knapsacka - "0/1" i "Rozwiązany"AMaksymalna Podtablica - "Metoda Siłowa" i "Dynamiczne Programowanie" (Kadane-a) wersjeASuma Kombinacji - znajdź wszystkie kombinacje, które tworzą określoną sumę
- Łańcuchy
BOdległość Hamminga - liczba pozycji, w których symbole są różneAOdległość Levenshteina - minimalna odległość edycji między dwiema sekwencjamiAAlgorytm Knuth–Morris–Pratta (Algorytm KMP) - dopasowywanie wzorców (dopasowywanie wzorców)AAlgorytm Z - szukanie podłańcucha(dopasowywanie wzorców)AAlgorytm Rabin Karpa - szukanie podłańcuchaANajdłuższa Wspólna PodłańcuchaADopasowanie Wyrażeń Regularnych
- Szukanie
BWyszukiwanie LinioweBJump Search (lub Przeszukiwanie Bloku) - szukaj w posortowanej tablicyBWyszukiwanie Binarne - szukaj w posortowanej tablicyBWyszukiwanie Interpolacyjne - szukaj w równomiernie rozłożonej, posortowanej tablicy
- Sortowanie
BSortowanie bąbelkoweBSortowanie przez wymianeBSortowanie przez wstawianieBSortowanie stogoweBSortowanie przez scalanieBSortowanie szybkie - wdrożenia w miejscu i nie na miejscuBSortowanie ShellaBSortowanie przez zliczanieBSortowanie pozycyjne
- Drzewa
BPrzeszukiwanie w głąb (DFS)BPrzeszukiwanie wszerz (BFS)
- Grafy
BPrzeszukiwanie w głąb (DFS)BPrzeszukiwanie wszerz (BFS)BAlgorytm Kruskala - znalezienie Minimalnego Drzewa Opinającego (MST) dla ważonego nieukierunkowanego wykresuAAlgorytm Dijkstry - znajdowanie najkrótszej ścieżki z pojedynczego źródła w grafieAAlgorytm Bellmana-Forda - znajdowanie najkrótszych ścieżek do wszystkich wierzchołków wykresu z jednego wierzchołkaAAlgorytm Floyd-Warshalla - znajdź najkrótsze ścieżki między wszystkimi parami wierzchołkówADetect Cycle - zarówno dla wykresów skierowanych, jak i nieukierunkowanych(wersje oparte na DFS i Rozłączny Zestaw)AAlgorytm Prima - znalezienie Minimalnego Drzewa Opinającego (MST) dla ważonego nieukierunkowanego wykresuASortowanie Topologiczne - metoda DFSAPunkty Artykulacji - Algorytm Tarjana (oparty o DFS)AMosty - Oparty na algorytmie DFSAŚcieżka Euleriana i Obwód Euleriana - Algorytm Fleurya - Odwiedź każdą krawędź dokładnie razACykl Hamiltoniana - Odwiedź każdy wierzchołek dokładnie razASilnie Połączone Komponenty - Algorytm KosarajaATravelling Salesman Problem - najkrótsza ścieżka która odwiedza każde miasto i wraca miasta początkującego
- Niezkategorizowane
BWieża HanoiBKwadratowa Matryca Obrotu - algorytm w miejscuBJump Game - cofanie, dynamiczne programowanie (od góry do dołu + od dołu do góry) i przykłady chciwegoBUnikatowe Ścieżki - cofanie, dynamiczne programowanie i przykłady oparte na Trójkącie PascalaAProblem N-QueensAKnight's Tour
Algorytmy według paradygmatu
Paradygmat algorytmiczny jest ogólną metodą lub podejściem, które jest podstawą projektowania klasy algorytmów. Jest abstrakcją wyższą niż pojęcie algorytmu, podobnie jak algorytm jest abstrakcją wyższą niż program komputerowy.
- Metoda Siłowa - Sprawdza wszystkie możliwosci i wybiera najlepsze rozwiązanie.
BWyszukiwanie LinioweAMaksymalna PodtablicaAProblem z Podróżującym Sprzedawcą - najkrótsza możliwa trasa, która odwiedza każde miasto i wraca do miasta początkowego
- Chciwy - wybierz najlepszą opcję w obecnym czasie, bez względu na przyszłość
BJump GameANiezwiązany Problem KnapsackaAAlgorytm Dijkstry - znalezienie najkrótszej ścieżki do wszystkich wierzchołków grafuAAlgorytm Prima - znalezienie Minimalnego Drzewa Opinającego (MST) dla ważonego nieukierunkowanego wykresuAAlgorytm Kruskala - znalezienie Minimalnego Drzewa Opinającego (MST) dla ważonego nieukierunkowanego wykresu
- Dziel i Zwyciężaj - podziel problem na mniejsze części, a następnie rozwiąż te części
BWyszukiwanie BinarneBWieża HanoiBTrójkąt PascalaBAlgorytm Euclideana - obliczyć Największy Wspólny Dzielnik(GCD)BSortowanie przez scalanieBSzybkie SortowanieBDrzewo Przeszukiwania W Głąb (DFS)BGraf Przeszukiwania W Głąb (DFS)BJump GameAPermutacje (z albo bez powtórzeń)AKombinacje (z albo bez powtórzeń)
- Programowanie Dynamiczne - zbuduj rozwiązanie, korzystając z wcześniej znalezionych podrzędnych rozwiązań
BCiąg FibonacciegoBJump GameBUnikatowe ScieżkiADystans Levenshteina - minimalna odległość edycji między dwiema sekwencjamiANajdłuższa Wspólna Podsekwencja (LCS)ANajdłuższa Wspólna PodłańcuchaANajdłuższa Wzrostająca PodsekwencjaANajkrótsza Wspólna SupersekwencjaA0/1 Problem KnapsackaAPartycja CałkowitaAMaksymalne PodtabliceAAlgorytm Bellman-Forda - znalezienie najkrótszej ścieżki wszystkich wierzchołków wykresuAAlgorytm Floyd-Warshalla - znajdź najkrótsze ścieżki między wszystkimi parami wierzchołkówADopasowanie Wyrażeń Regularnych
- Algorytm z nawrotami - podobny do metody siłowej, próbuje wygenerować wszystkie możliwe rozwiązania, jednak za każdym razem generujesz następne rozwiązanie które testujesz
jeżeli zaspokaja wszystkie warunki, tylko wtedy generuje kolejne rozwiązania. W innym wypadku, cofa sie, i podąża inna ścieżka znaleźenia rozwiązania. Zazwyczaj, używane jest przejście przez Przeszukiwania W Głąb(DFS) przestrzeni stanów.
BJump GameBUnikatowe ScieżkiACykl Hamiltoniana - Odwiedź każdy wierzchołek dokładnie razAProblem N-QueensAKnight's TourAZestaw Sumy - znajduje wszystkie zestawy które tworzą określoną sumę
- Metoda Podziału i Ograniczeń - Pamięta o niskonakładowym rozwiązaniu znalezionym na każdym etapie szukania nawrotu, używa kosztu niskonakładowego kosztu, które dotychczas zostało znalezione jako niska granica najmniejszego kosztu do rozwiązanie problemu, aby odrzucić cząstkowe rozwiązania o kosztach większych niż niskonakładowe rozwiązanie znalezione do tej pory. Zazwyczan trajektoria BFS, w połączeniu z trajektorią Przeszukiwania W Głąb (DFS) drzewa przestrzeni stanów jest użyte.
Jak używać repozytorium
Zainstaluj wszystkie zależnosci
npm install
Uruchom ESLint
Możesz to uruchomić aby sprawdzić jakość kodu.
npm run lint
Uruchom wszystkie testy
npm test
Uruchom testy używając określonej nazwy
npm test -- 'LinkedList'
Playground
Możesz pociwiczyć ze strukturą danych i algorytmami w ./src/playground/playground.js zakartotekuj i napisz
testy do tego w ./src/playground/__test__/playground.test.js.
Następnie uruchom następującą komendę w celu przetestowania czy twoje kod działa według oczekiwań:
npm test -- 'playground'
Pomocne informacje
Źródła
â–¶ Struktury Danych i Algorytmy na YouTube
Big O Notacja
Kolejność wzrastania algorytmów według Big O notacji.
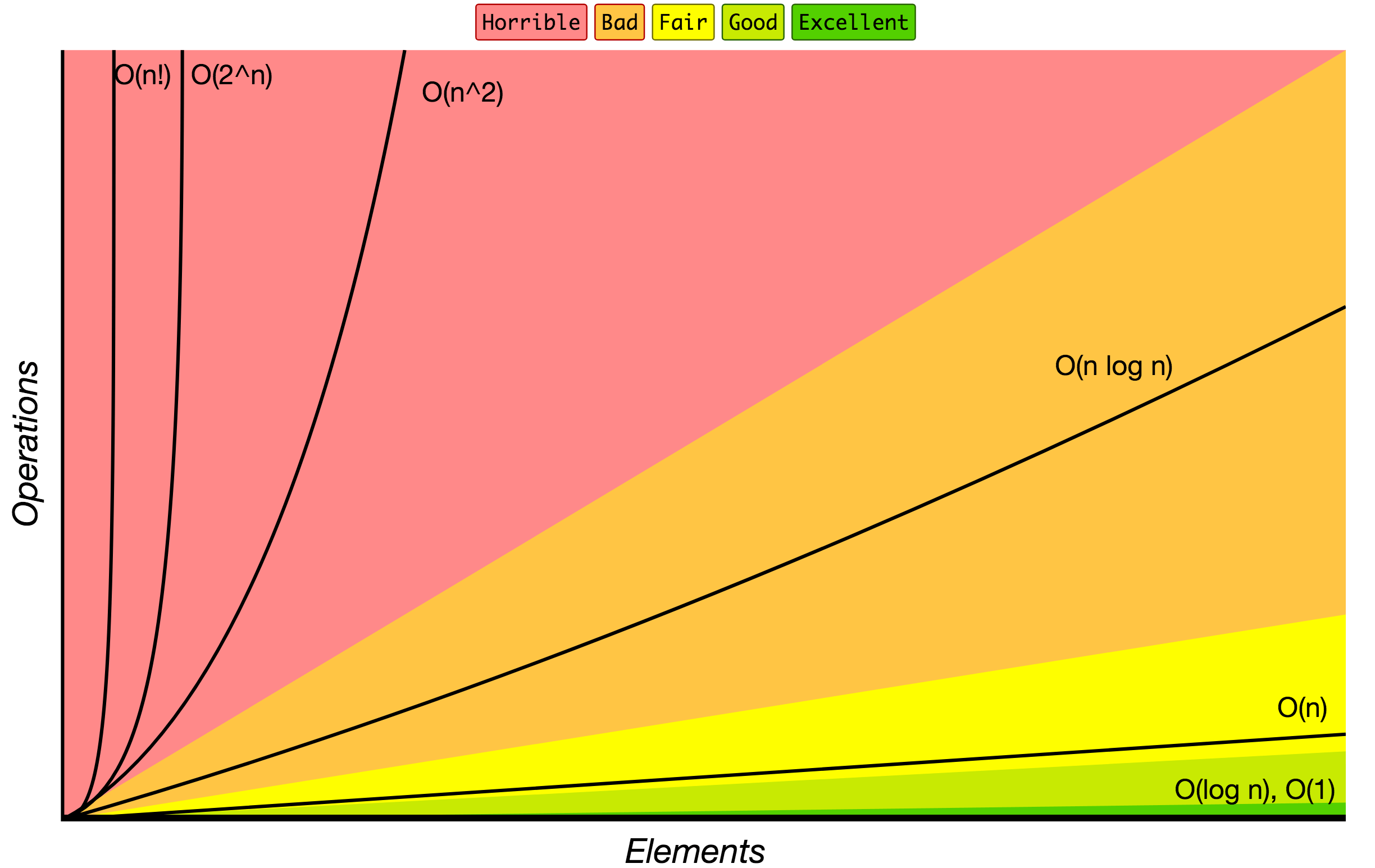
Źródło: Big O Cheat Sheet.
Poniżej umieszczamy listę najbardziej używanych Big O notacji i ich porównania wydajności do róznych rozmiarów z wprowadzonych danych.
| Big O notacja | Obliczenia na 10 elementów | Obliczenia na 100 elementów | Obliczenia na 1000 elementów |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
Złożoność operacji struktury danych
| Struktura Danych | Dostęp | Szukaj | Umieszczanie | Usuwanie | Komentarze |
|---|---|---|---|---|---|
| Szereg | 1 | n | n | n | |
| Sterta | n | n | 1 | 1 | |
| Kolejka | n | n | 1 | 1 | |
| Lista Powiązana | n | n | 1 | 1 | |
| Tablica funkcji mieszanej | - | n | n | n | W wypadku idealnej funkcji skrótu koszt mógłby sie równać O(1) |
| Binarne Drzewo Poszukiwań | n | n | n | n | W przypadku zrównoważonych kosztów drzew byłoby O(log(n)) |
| B-Drzewo | log(n) | log(n) | log(n) | log(n) | |
| Drzewa czerwono-czarne | log(n) | log(n) | log(n) | log(n) | |
| AVL Drzewo | log(n) | log(n) | log(n) | log(n) | |
| Filtr Blooma | - | 1 | 1 | - | Fałszywe dotatnie są możliwe podczas wyszukiwania |
Sortowanie Tablic Złożoności Algorytmów
| Nazwa | Najlepszy | Średni | Najgorszy | Pamięć | Stabilność | Komentarze |
|---|---|---|---|---|---|---|
| Sortowanie bąbelkowe | n | n2 | n2 | 1 | Yes | |
| Sortowanie przez wstawianie | n | n2 | n2 | 1 | Yes | |
| Sortowanie przez wybieranie | n2 | n2 | n2 | 1 | No | |
| Sortowanie przez kopcowanie | n log(n) | n log(n) | n log(n) | 1 | No | |
| Sortowanie przez scalanie | n log(n) | n log(n) | n log(n) | n | Yes | |
| Szybkie sortowanie | n log(n) | n log(n) | n2 | log(n) | No | Szybkie sortowanie jest zazwyczaj robione w miejsce O(log(n)) stosu przestrzeni |
| Sortowanie Shella | n log(n) | zależy od luki w układzie | n (log(n))2 | 1 | No | |
| Sortowanie przez zliczanie | n + r | n + r | n + r | n + r | Yes | r - największy numer w tablicy |
| Sortowanie Radix | n * k | n * k | n * k | n + k | Yes | k -długość najdłuższego klucza |