mirror of
https://github.moeyy.xyz/https://github.com/trekhleb/javascript-algorithms.git
synced 2024-12-26 15:11:16 +08:00
* [REFACTOR] ReadMe.ko-KR.md edit awkward grammar and add more explain about Algorithms by Paradigm * [ADD] ReadMe of japanese * [FIX] change Japan person to langauge of Japan
18 KiB
18 KiB
JavaScript 算法与数据结构

![]()
本仓库包含了多种基于 JavaScript 的算法与数据结构。
每种算法和数据结构都有自己的 README,包含相关说明和链接,以便进一步阅读 (还有 YouTube 视频) 。
Read this in other languages: English, 繁體中文, 한국어, 日本語, Polski, Français, Español, Português
注意:这个项目仅用于学习和研究,不是用于生产环境。
数据结构
数据结构是在计算机中组织和存储数据的一种特殊方式,使得数据可以高效地被访问和修改。更确切地说,数据结构是数据值的集合,表示数据之间的关系,也包括了作用在数据上的函数或操作。
B - 初学者, A - 进阶
算法
算法是如何解决一类问题的明确规范。算法是一组精确定义操作序列的规则。
B - 初学者, A - 进阶
算法主题
- 数学
- 集合
- 字符串
B汉明距离 - 符号不同的位置数A莱温斯坦距离 - 两个序列之间的最小编辑距离AKnuth–Morris–Pratt 算法 KMP 算法 - 子串搜索 (模式匹配)A字符串快速查找 - 子串搜索 (模式匹配)ARabin Karp 算法 - 子串搜索A最长公共子串A正则表达式匹配
- 搜索
- 排序
- 链表
- 树
- 图
B深度优先搜索 (DFS)B广度优先搜索 (BFS)B克鲁斯克尔演算法 - 寻找加权无向图的最小生成树 (MST)A戴克斯特拉算法 - 找到图中所有顶点的最短路径A贝尔曼-福特算法 - 找到图中所有顶点的最短路径A弗洛伊德算法 - 找到所有顶点对 之间的最短路径A判圈算法 - 对于有向图和无向图 (基于 DFS 和不相交集的版本)A普林演算法 - 寻找加权无向图的最小生成树 (MST)A拓扑排序 - DFS 方法A关节点 - Tarjan 算法 (基于 DFS)A桥 - 基于 DFS 的算法A欧拉回径与一笔画问题 - Fleury 的算法 - 一次访问每个边A哈密顿图 - 恰好访问每个顶点一次A强连通分量 - Kosaraju 算法A旅行推销员问题 - 尽可能以最短的路线访问每个城市并返回原始城市
- 加密
B多项式 hash - 基于多项式的 rolling hash 函数
- 未分类
算法范式
算法范式是一种通用方法,基于一类算法的设计。这是比算法更高的抽象,就像算法是比计算机程序更高的抽象。
- BF 算法 -
查找/搜索所有可能性并选择最佳解决方案 - 贪心法 - 在当前选择最佳选项,不考虑以后情况
- 分治法 - 将问题分成较小的部分,然后解决这些部分
- 动态编程 - 使用以前找到的子解决方案构建解决方案
- 回溯法 - 类似于
BF 算法试图产生所有可能的解决方案,但每次生成解决方案测试如果它满足所有条件,那么只有继续生成后续解决方案。否则回溯并继续寻找不同路径的解决方案。 - Branch & Bound - 记住在回溯搜索的每个阶段找到的成本最低的解决方案,并使用到目前为止找到的成本最小值作为下限。以便丢弃成本大于最小值的解决方案。通常,使用 BFS 遍历以及状态空间树的 DFS 遍历。
如何使用本仓库
安装依赖
npm install
运行 ESLint
检查代码质量
npm run lint
执行测试
npm test
按照名称执行测试
npm test -- 'LinkedList'
Playground
你可以在 ./src/playground/playground.js 文件中操作数据结构与算法,并在 ./src/playground/__test__/playground.test.js 中编写测试。
然后,只需运行以下命令来测试你的 Playground 是否按无误:
npm test -- 'playground'
有用的信息
引用
大O符号
大O符号中指定的算法的增长顺序。
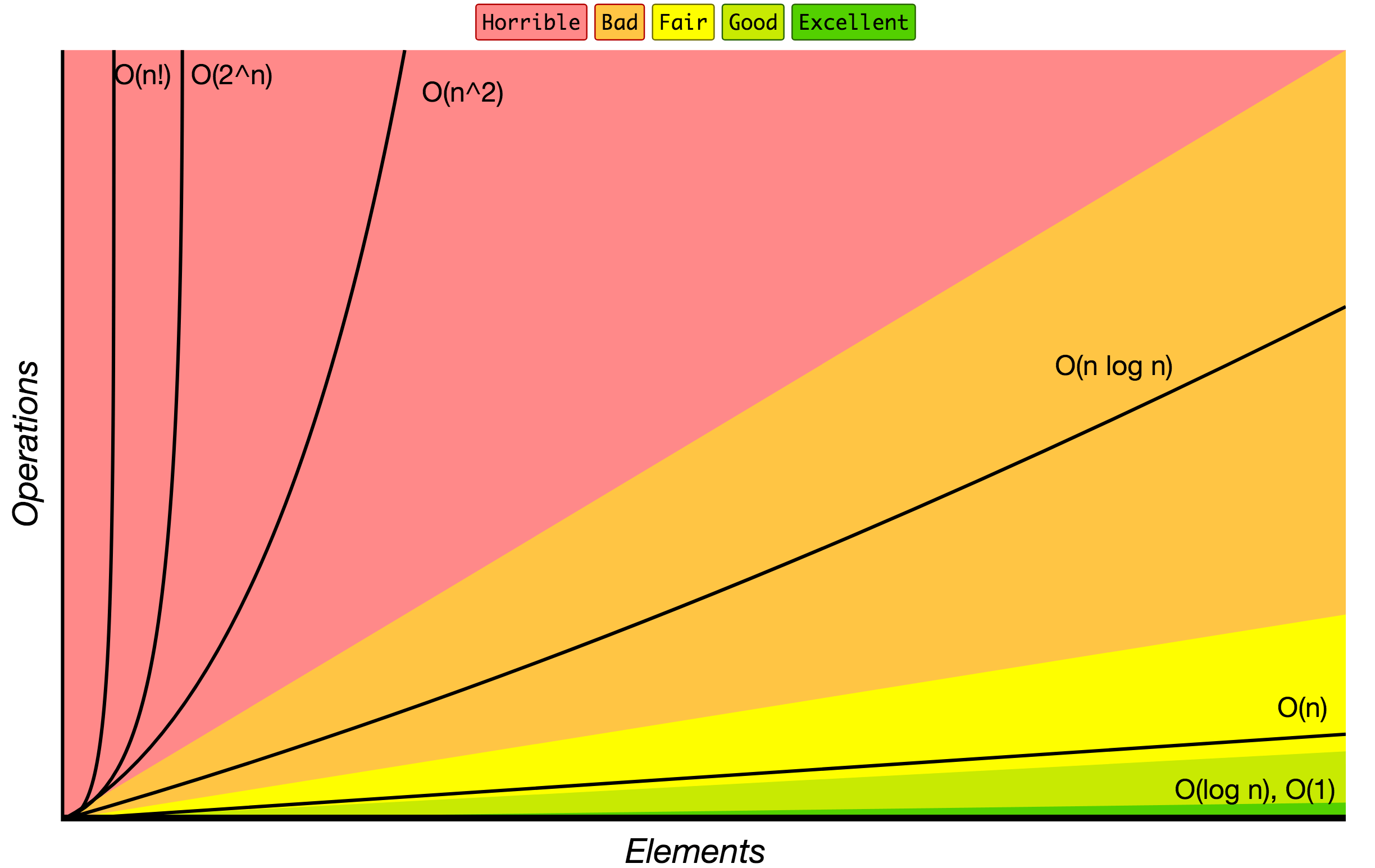
以下是一些最常用的 大O标记法 列表以及它们与不同大小输入数据的性能比较。
| 大O标记法 | 计算10个元素 | 计算100个元素 | 计算1000个元素 |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
数据结构操作的复杂性
| 数据结构 | 连接 | 查找 | 插入 | 删除 | 备注 |
|---|---|---|---|---|---|
| 数组 | 1 | n | n | n | |
| 栈 | n | n | 1 | 1 | |
| 队列 | n | n | 1 | 1 | |
| 链表 | n | n | 1 | 1 | |
| 哈希表 | - | n | n | n | 在完全哈希函数情况下,复杂度是 O(1) |
| 二分查找树 | n | n | n | n | 在平衡树情况下,复杂度是 O(log(n)) |
| B 树 | log(n) | log(n) | log(n) | log(n) | |
| 红黑树 | log(n) | log(n) | log(n) | log(n) | |
| AVL 树 | log(n) | log(n) | log(n) | log(n) | |
| 布隆过滤器 | - | 1 | 1 | - | 存在一定概率的判断错误(误判成存在) |
数组排序算法的复杂性
| 名称 | 最优 | 平均 | 最坏 | 内存 | 稳定 | 备注 |
|---|---|---|---|---|---|---|
| 冒泡排序 | n | n^2 | n^2 | 1 | Yes | |
| 插入排序 | n | n^2 | n^2 | 1 | Yes | |
| 选择排序 | n^2 | n^2 | n^2 | 1 | No | |
| 堆排序 | n log(n) | n log(n) | n log(n) | 1 | No | |
| 归并排序 | n log(n) | n log(n) | n log(n) | n | Yes | |
| 快速排序 | n log(n) | n log(n) | n^2 | log(n) | No | 在 in-place 版本下,内存复杂度通常是 O(log(n)) |
| 希尔排序 | n log(n) | 取决于差距序列 | n (log(n))^2 | 1 | No | |
| 计数排序 | n + r | n + r | n + r | n + r | Yes | r - 数组里最大的数 |
| 基数排序 | n * k | n * k | n * k | n + k | Yes | k - 最长 key 的升序 |