9.8 KiB
Executable File
9.8 KiB
Executable File
MySQL
docker 安装mysql
- 创建 docker-compose.yml
vim docker-comopse.yml
===
services:
mysql:
image: mysql
restart: on-failure
environment:
- MYSQL_ROOT_PASSWORD=Aa123456
- MYSQL_DATABASE=mybase
- MYSQL_USER=hxx
- MYSQL_PASSWORD=Aa123456
- TZ=Asia/Shanghai
- character-set-server=utf8mb4
- collation-server=utf8mb4_unicode_ci
ports:
- '3307:3306'
volumes:
- ./data:/var/lib/mysql # 数据挂载
- ./init:/docker-entrypoit-initdb.d/ # 初始脚本
===
- 创建授权 root 用户可以远程链接的脚本
mkdir init
vim init/remote.sql
===
-- GRANT ALL privileges on *.* TO 'root'@'%';
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native-pasword BY 'Aa123456';
===
- 错误
Client does not support authentication protocol requested by server; consider upgrading MySQL client
mysql -u root -p
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY '你的密码';
# ALTER USER 'root' IDENTIFIED WITH mysql_native_password BY '你的密码';
flush privileges;
# mysq> 加一个闪烁的光标等待命令的输入, 输入 exit 或 quit 退出登录
语法
- 大小写不敏感
- 可以单行/多行, 以
;结束 - 注释
- 单行:
-- 注释内容 - 单行:
# 注释内容 - 多行:
/* 多行内容 */
- 单行:
数据库操作
# 查看数据库
show databases;
# 使用数据库
use 数据库名;
# 创建数据库
create database 数据库名 [charset utf8];
# 删除数据库
drop database 数据库名;
# 查看当前使用的数据库
select database();
表操作
查
# 查看有哪写表, 需要先选择库
show tables;
# 查看表的结构
desc 表名;
增
# 创建表
create table 表名称(
列名称 列类型,
列名称 列类型,
......
);
/*
列类型有:
int 整数
float 浮点数
varchar(长度) 文件,长度为数字, 做最大长度限制
date 日期类型
timestamp 时间戳
*/
# 复制表结构
create table 新表名 like 旧表名;
# 复制表
create table 新表名 as (select * from 旧表名);
通用字段
- id
- create_time
- creator
- update_time: 默认值可以为 CURRENT_TIMESTAMP
- update_by
- remark
一张表的字段不宜超过20个,超过考虑拆分
删
# 删除表
drop table 表名称;
drop table if exists 表名称;
改
# 增加字段
alter table 表名 add 字段名 类型;
# 删除字段
alter table 表名 drop 字段名;
# 更改字段类型
alter table 表名 modify 字段 类型;
# 更改字段名
alter table 表名 change 旧字段 新字段 类型;
增删改查
增
insert into 表名 [(字段列表)] values (值列表);
-- 如果为所有字段新增数据, 不需要写字段列表
-- null 说明由系统自动生成标识列
-- 如果字段非空, 但有默认值, 可以不赋值
-- 非空字段, 没有默认值, 一定要赋值
-- 字符串一定要加引号, 数字可加可不加
insert into users values (null, '马九', 22, '男', '马家村', 0);
-- 或者
insert into users (name, age, address) values ('马十', 21, '马家村');
# 插入多条
insert into 表名 [(字段列表)] values (值列表), (值列表), ...;
删
delete from 表名 where 条件;
# 清空表
delete from 表名;
DELETE from users where name = '马十';
DELETE from users where id in (1, 3);
改
updata 表名 set 字段 = 新值, 字段 = 新值 where 条件;
-- 一定要加上条件, 不加条件所有的都被修改了
update users set age = 20 where id = 2;
-- 使用表达式
update users set age = age + 1 where id = 1;
UPDATE torrent
SET url = REPLACE(url, 'mikanani.me', 'mikanime.tv')
WHERE url LIKE '%mikanani.me%';
查
-- 注释为双横线加空格
select 字段 from 表名 [where 条件];
-- 条件没有可以不写
-- 返回的结果是虚拟表
-- 在sql中. 逻辑等和赋值都是用=号
-- 逻辑与 and
-- 逻辑或 or
-- 逻辑非 not
select * from users;
select id, name, gender from users;
select * from users where id = 2;
select * frm users where id = 2 or id = 3;
select * from users where gender = '男' and age > 20;
select * from users where id in (2, 3, 4, 5); -- id在2, 3, 4, 5 范围内
select * from users where id not in (1, 2); -- id 不包括2, 3, 4, 5
其他常用函数
统计
-- 统计所有数据条数
select count(*) from users;
-- 只统计非空的数据调数, 过滤null
select count(gender) from users;
-- 查询最大
select max(age) from users;
-- 查询最小
select min(age) from users;
-- 求平均, 数值有效
select avg(age) from users;
排序
-- asc升序, 默认升序可以不写, desc倒序
select * from users order by id [asc];
select * from users order by id desc;
# 排序
select 列|聚合函数|* from 表
[where 条件]
[group by 列]
order by 列
[asc|desc];
# asc 升序, 默认, 可以不写
# desc 倒序
分页
select * from users limit m; -- 前m条
select * from users limit m, n; -- 查询m+n条记录,去掉前m条,返回后n条记录.m的值越大,查询的性能会越低
select * from users limit 3 offset 0; -- 从第1条开始, 向下查询3条
-- offset 偏移
-- 当m非常大时, 要先查询m+n条记录 , 再取n条, 非常慢, 可以进行优化
select * from users limit 10000, 100;
-- 优化思想, 先定位id
select * from users where id >100001 limit 100;
# 分页查询
select 列|聚合函数|* from 表
[where 条件]
[group by 列]
order by 列
[asc|desc]
limit n[,m];
# 只有n, 取n条
# n, m 跳过n条, 取m条
分组聚合
# 分组聚合
select 字段|聚合函数 from 表名 [where 条件] group by 列;
# group by 出现的哪个列, 只有这个列能用在字段中
# 按照 group by后面的条件进行分组
/*
聚合函数有:
sum(列) 求和
avg(列) 平均
min(列) 最小
max(列) 最大
count(列|*) 数量
*/
# 按男女分组, 统计平均年龄
select gender, avg(age) from student group by gender;
# 数值函数
# 四舍五入: round()
# 向上取整: ceil()
# 向下取整: floor()
# 按部门求平均工资, 并且过滤出工资大于3000的
select depnum, ave(salary) as 平均工资 from emp group by depnum having 平均工资>3000;
# HAVING 子句用于对分组结果进行过滤。它通常与 GROUP BY 子句一起使用,用于筛选聚合函数的结果。
# WHERE 子句用于在分组前对记录进行过滤
# as 命名
注意事项:
- select, from 必写
- where, group by, order by, limit 按须
- 执行顺序: from -> where -> group by 和聚合函数 -> select -> order by -> limit
去重
# 从表中选择不重复的列
SELECT DISTINCT 字段 FROM 表名;
# 多列,并且这些列的组合是唯一
SELECT DISTINCT column1, column2 FROM table_name;
模糊查询
# like
# % 表示匹配多个字符
# _ 表示匹配单个字符
select * from 表名 where 字段 like '%字符%';
长度
# 判断字符长度
select length('一');
# 获取姓名为两个中文的
SELECT * FROM users WHERE LENGTH(name)=6;
运算符
# select 后面 + - * /
# 应用在数值类型
# 查询员工半年的工资
select name, salary*6 as 半年工资 from emp;
# ifnull(要检查的表达式, 为null时的替代值)
select name, (salary+ifnull(comm,0))*6 as 半年工资(加奖金) from emp;
日期函数
select month('2024-01-01');
select year('2024-01-01');
select day('2024-01-01');
select week('2024-01-01');
select now(); # 当前时间
# timestampdiff(格式, 开始时间, 结束时间)
SELECT timestampdiff(DAY, '2024-01-01', NOW());
多表查询
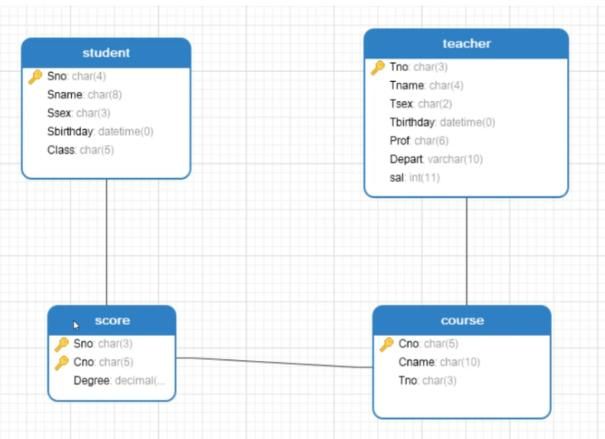
交叉连接/关联查询
速度比较慢
# 交叉连接: cross join
# 学生表和成绩表关联
select * from student cross join score where student.Sno=score.Sno;
# cross join 返回的是笛卡尔积的数据,存在无意义的数据。所以用where过滤掉
# cross join 简写为逗号
select * from student, score where student.Sno=score.Sno;
# 查询每个学生每门课程考多少分
select student.Sname as 姓名, score.cno as 课程编号, score.Degree as 成绩 from student, score where student.Sno=score.Sno;
内连接
# 内连接: 表1 inner join 表2 on 表1.id=表2.id
# 表1.id于表2.id 描述同一显示事物
select student.Sname as 姓名, score.cno as 课程编号, score.Degree as 成绩
from student inner join score
on student.Sno=score.Sno;
# 如果三张表: 表1 inner join 表2 on 表1.id=表2.id inner join 表3 on 表2.id=表3.id
外连接
# 左外连接: 表1 left join 表2 on 表1.id-表2.id
-- 返回左表中的所有数据,对应右表不存在的数据,以nul1的形式返回。
# 右外连接: 表1 right join 表2 on 表1.id-表2.id
-- 返回右表中的所有数据,对应左表中不存在的数据,以nul1形式返回。
# 哪些学生没有选修课程的
select student.Sname as 姓名
from student left join score on student.sno=score.sno
where student.degree is NULL;
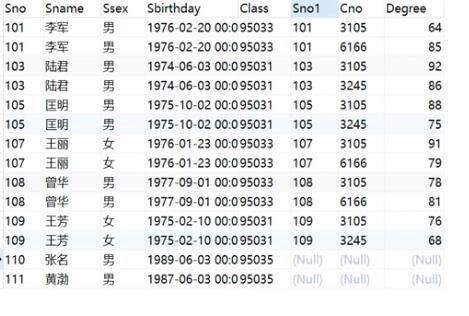
子查询
# 子查询:一个查询语句中,嵌套另一个查询语句。
-- 多行子查询: in 和 not in
-- 单行子查询: >, < , >=, <=, !=, 不等于也可以写成<>
# 哪些学生没有选修课程的
select * from student where sno not in (select sno from score);
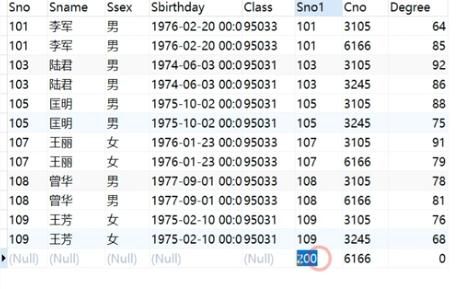
# 查询成绩表中成绩最高的学生
select * from student
where student.sno=score.sno
and score.degree =
(select max(degree) from score);